







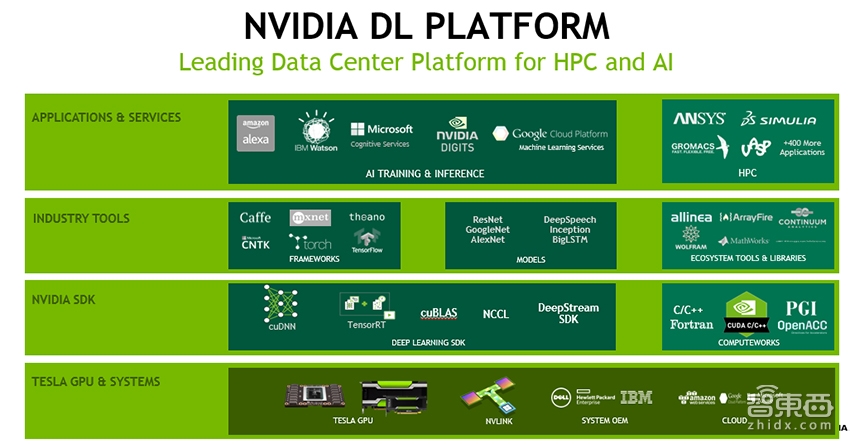
3月20日,智东西与NVIDIA共同策划的「NVIDIA公开课」在深度学习社群开讲,主讲嘉宾为NVIDIA(英伟达)大中华区高性能计算及Applied Deep Learning部门技术总监赖俊杰博士,主题为《AI浪潮来袭,如何搭建适合自己的深度学习平台?》。这是NVIDIA在国内首次就深度学习主题组织公开课,吸引到超过1200人报名,基于专业性审核,共有近1000名以研发工程师为核心的行业用户参与到听课与互动当中。此前,智东西先后与大疆创新、亚马逊中国策划过「大疆公开课」和「亚马逊公开课」。

在「NVIDIA公开课」主讲结束之后,赖俊杰博士回答了学员从不同角度的9个提问。以下为实录:
提问一:创业公司搭建深度学习平台初期,应注意的重点。(来自@Alice-恩知-智慧医疗)
赖博士:前面提到了一些,我这里手打一下吧。主要是看需求,如果只是少量的计算需求,或者刚开始使用GPU平台的话,完全可以先买几块GeForce消费级显卡试水。如果需要大量部署的时候,主要有两种选择。如果不想投入太多硬件维护的人力,可以采用像阿里云,Amazon Cloud等等云服务商提供的GPU节点。当然用户也可以自己购买GPU服务器,这里面包括NVIDIA自己的DGX-1(主要适合对于扩展性要求高,模型大,训练量大的场合),或者是一般的NVIDIA合作伙伴提供的GPU服务器。
提问二:赖老师,您好!非常高兴能听您的分享,我们公司现在在做机器学习这块,工作站及个人笔记本都用的英伟达GPU,想问您一个问题,就是我们在做机器学习时,如何能最大化GPU使用效率?另外一个问题,不知道赖老师对于深度学习在工业方面的应用能不能给出一些建议?或者从您的了解,目前在工业自动化领域,深度学习是否已经开始或得到了一些比较好的运用?非常非常感谢您!(来自@肖素枝-兰宝传感-机器学习)
赖博士:第一个问题,最大化GPU使用效率。在做training的时候,如果用户是用一般的开源框架去做,其实这些东西已经wrap到工具内部了,一般不太涉及到计算性能优化的问题。如果用户是自己开发的训练的软件,这里面问题就很复杂,一两句就描述不清楚了。最核心的其实就是如何能够提高软件的Scalability。如果是做inference,部署的时候的性能优化还是需要做一些工作的。建议有需要的时候可以跟NVIDIA联系,我们的团队可以给一些具体一些的建议。
第二个,深度学习在工业自动化领域的应用。我大致了解,在这个领域,很多都是把CV里面的一些检测分类的方法用到具体的问题里面。NVIDIA跟FANUC已经开展了比较深入的合作。
提问三:现有的深度学习神经网络模型很容易被未来更好的模型所取代。如何在GPU平台做到很好的可重构性,同时保证高效能?(来自@程亚冰-机器学习)
赖博士:GPU平台的一个很大的好处就在于,其有一定的通用性,编程相对容易。所以在新的模型,或者layer出现之后,在GPU上可以很快地获得比较高效的实现。所以新的网络在GPU上往往会获得快速的应用。这也是为什么大家选择GPU做DL的很重要的因素之一。
提问四:深度学习的商业化广泛应用时间点?(来自@王学刚-Senmass-智能包装)
赖博士:其实我们完全可以说,现在深度学习已经获得了广泛的商业应用。打个比方说,我们常见的语音图像类应用,大部分都已经切换到了深度神经网络的backend。你会发现这几年手机里面的各种语音助手似乎都达到了基本可用的地步。这些都是深度神经网络大规模商用带来的好处。
现在的问题是如何进一步扩展DL应用的应用领域。想象空间如前面所讲,是非常非常大的。
提问五:可以简单介绍下 Applied DL部门主要的工作内容,和已有的成果吗?(来自@贾庸-中科院·MLDL算法精研社)
赖博士:前面其实介绍过一些。我们核心做的还是加速计算。让用户用更少的硬件完成更多的任务。除了做一些具体的代码的移植优化的工作,主要也会做一些library(像DeepStream)之类。另外现阶段基于DeepStream做过一些人脸,人车检测等等应用的参考。主要考虑是了解用户那边的workload,方便用户做二次开发。
提问六:赖博士,DL能够应用到EDA工具软件里面吗?例如,PCB自动布线,未来能够利用DL完全替代人工是否可能?(来自@刘颖峰-舒尔电子-高级工程师)
赖博士:坦白讲,我对这个真不了解。不过我可以讲的是NVIDIA确实有研发人员在探讨如何将DL用在芯片设计流程中。
提问七:非常精彩的报告!想问个问题。与GPU用于一般的HPC相比,GPU用于Deep Learning有啥不同?
赖博士:其实没有什么本质的不同。我们完全可以把Deep Learning的workload,不管是training还是inference看成是HPC的应用。这也是为什么现在做DL的infrastructure一般都采用的HPC模式。像通信接口采用MPI。这里面追求的核心是performance,而不是扩展性,容错性,等等。
提问八:GPU Server的计算能力和memory之间有瓶颈吗?有的话是在内存(DRAM, HBM)带宽,还是内存和存储(SSD, 3D point)之间的带宽?(来自@王楠-中科创达-战略投资经理)
赖博士:计算能力跟内存(DRAM)到底谁是瓶颈取决于应用大致是compute bound还是memory bound的?
一般来讲,至少我看到的例子,不太会反复地对存储进行大量数据的读写,如果真有这样的应用的话,那很有可能存储的带宽会变成瓶颈。GPU的计算能力跟memory带宽量级都较存储带宽高很多。更多的情况是,预先把数据都load 到memory(CPU或者GPU),或者存储里的数据地访问,相对于后续的处理是相对少量的。
提问九:谢谢赖博士精彩的报告。我们对瞳孔识别的定位帧率和精确度有比较高的要求,我们自己普通PC上做到了120HZ左右。但想更快。不知道有没有可能利用DL进一步提升。NVIDIA有训练相关的模型或者库,支持相关的开发吗?(来自@范杭-弥德科技-裸眼3D游戏)
赖博士:这个太专了。我首先不清楚DL用在你们的应用里面是否能达到足够的,你们需要的精度。其次,一般来讲,DL相对于传统的方法的计算量需求都大。所以一般不太会有为了提高计算速度而采用DL的。一般都是为了提高精度(当然是可能的前提下),牺牲一些计算量,来用DL。
