








智东西(公众号:zhidxcom)
编译 | 李水青
编辑 | 云鹏
智东西7月1日消息,刚刚,Anthropic宣布Claude Fable 5解禁。就在6小时前,Anthropic推出一款新模型Claude Sonnet 5,面向所有套餐用户开放。
Anthropic在推文中称:“我们已收到通知,美国商务部已解除对Claude Fable 5和Mythos 5的出口管制。我们将于明日开始恢复访问权限,并尽快发布最新消息。感谢用户的耐心等待,也感谢所有与我们合作的人员。”

▲Anthropic宣布Fable 5解禁
此前6月13日,Anthropic因美国政府发布一项出口管制指令,终止了所有用户的Fable 5和Mythos 5访问权限。而后两周,Anthropic在全球范围内封禁了一大批账号,使得大批原Claude用户转向寻找替代产品。
Fable 5回归的关注度虽高,但Claude最新的Sonnet 5也值得一看。据悉,其最大进步在于能够自主运行长时间任务,用户可以制定计划、使用浏览器和终端等工具。几个月前要达到这样的水平,还需要更昂贵的模型。
从测评成绩来看,Sonnet 5性能接近Opus 4.8,但价格更低;同时,它比其前代产品Sonnet 4.6有了显著的改进,在推理、工具使用、编程和知识工作等Agent性能方面更强。
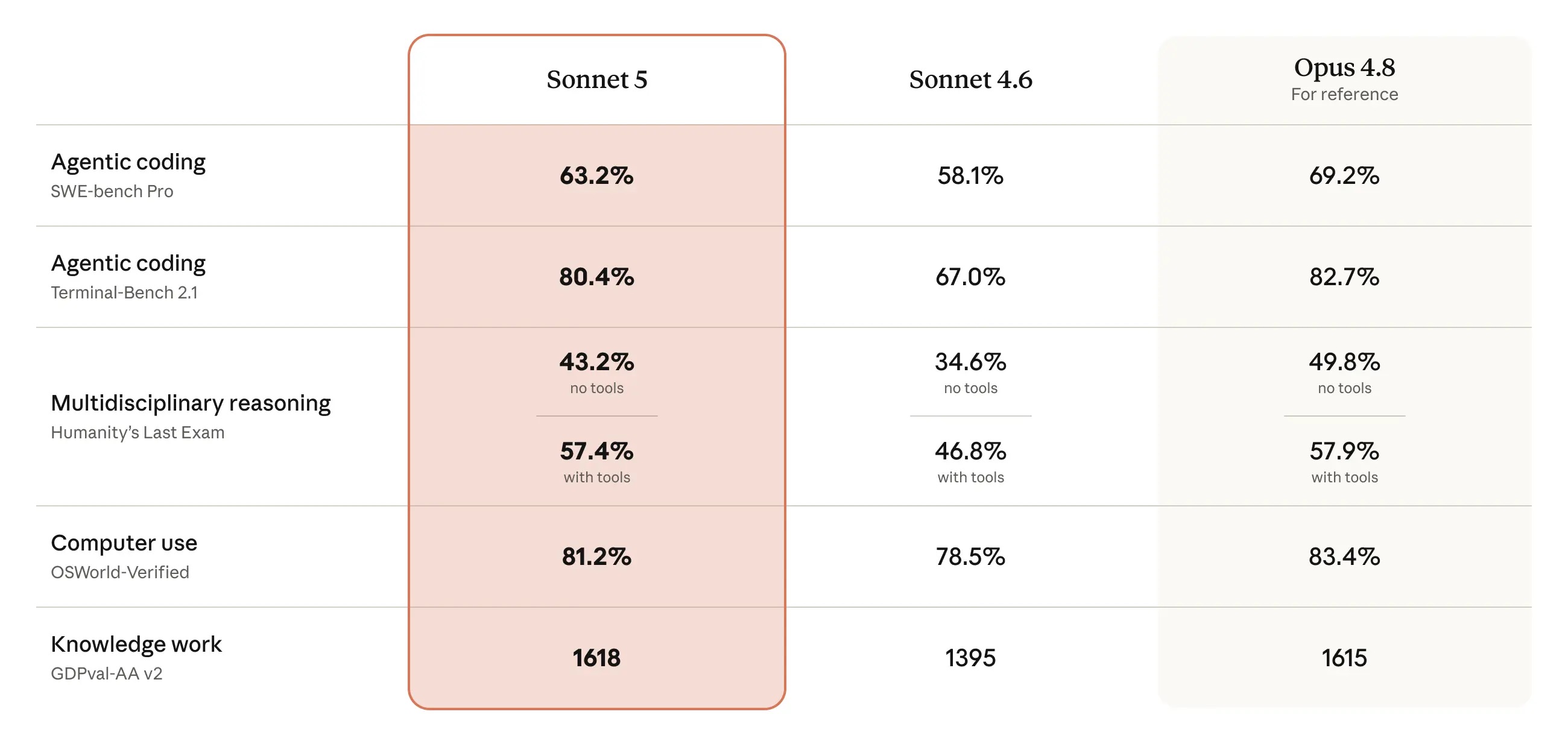
▲Sonnet 5与Sonnet 4.6和Opus 4.8测评得分对比
Sonnet 5在Agent环境中使用更安全,不良行为发生率总体低于Sonnet 4.6,但高于Opus 4.8和Claude Mythos Preview。但在网络安全类任务上,该模型的能力远不及现有Opus系列模型。
从今天起,免费版和专业版Claude用户默认使用Sonnet 5,Max版、团队版和企业版用户也可使用,该模型还可通过Claude Code和Claude Platform使用。在Claude Platform上,Sonnet 5的首发价格为每百万个输入token 2美元(约合人民币13.6元),每百万个输出token 10美元(约合人民币67.9元),优惠期至2026年8月31日。
优惠结束之后,价格将调整为每百万个输入token 3美元(约合人民币20.4元),每百万个输出token 15美元(约合人民币101.8元);这一价格仍低于Opus 4.8的输入5美元、输出25美元的定价。开发者可通过Claude API使用claude-sonnet-5模型。
模型一经发布,一些网友认为这是一次“巨大的更新”。有网友称:“有趣的不是它与Opus的算法接近,而是算法接近但token的价格却便宜60%。”有网友称:“既然它本身就能处理多步骤Agent工作流程,再去构建更大的模型就不太划算了。”也有人称:“终于有一个能自我检查的模型了,它让我们免于在长时间运行的循环中时刻关注每一个输出结果。”
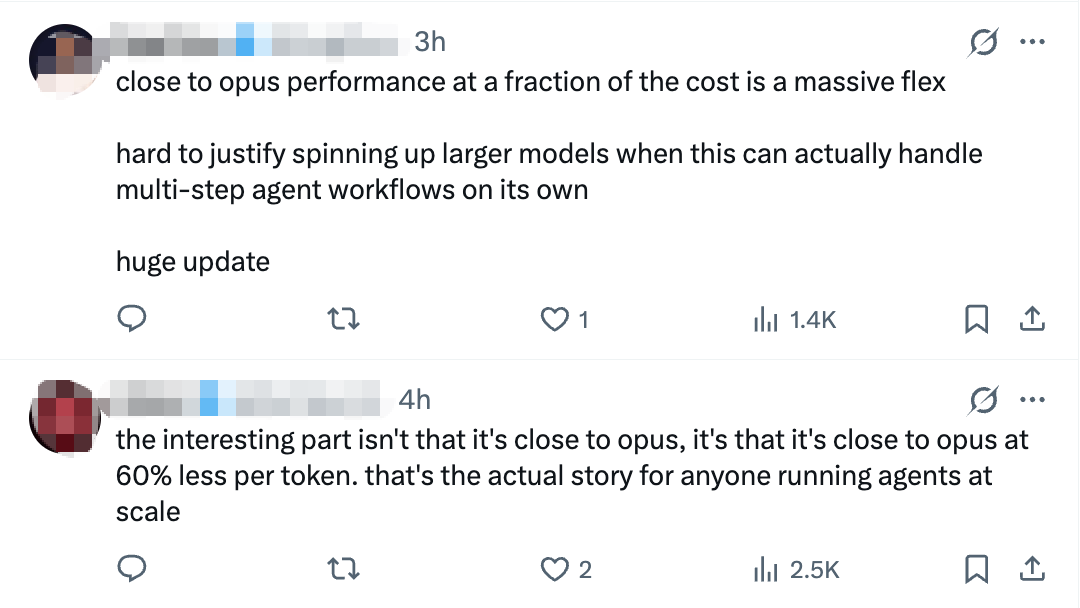

▲网友对Sonnet 5的评论(图源:社交媒体X)
但也有网友认为这款模型颇为“鸡肋”。一位网友称:“你自己也承认,这比你目前排名第二的型号要弱。订阅用户想要的是性能更强的模型,而不是价格便宜几分钱却只会给出虚假答案的玩具。”也有网友担心所谓自主运行,反而让用户担心模型犯傻、删错文件。有人吐槽:“促销价过后,它的价格和Opus差不多。”也有网友认为,Sonnet 5就是面向6月17日新开源的智谱GLM-5.2展开价格战。
GLM-5.2在OpenRouter等第三方API平台定价为每百万token输入1.40美元,输出4.40美元,Sonnet 5依然高出不少。
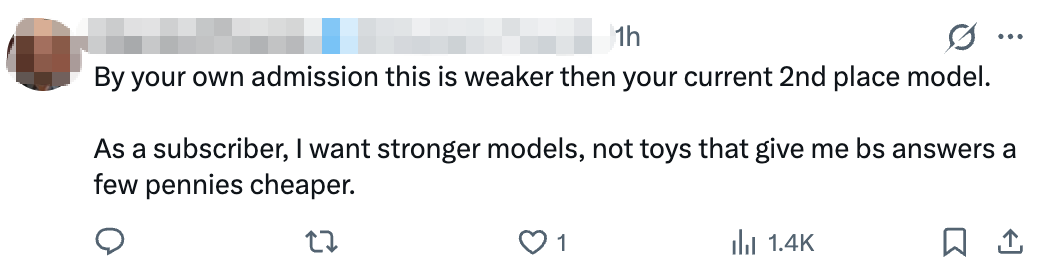
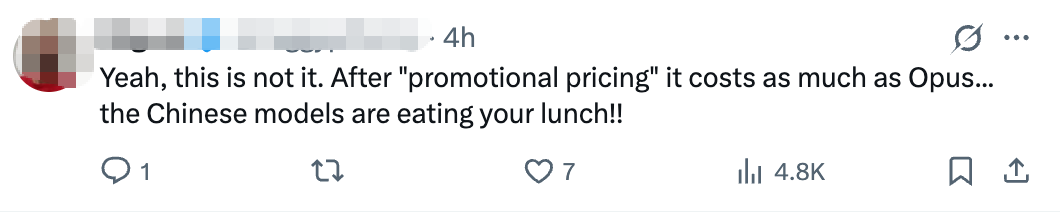

▲网友对Sonnet 5的评论(图源:社交媒体X)
一、性能对标、价格骨折,Sonnet 5拳打自家Opus 4.8
下图比较了Sonnet 5、Sonnet 4.6和Opus 4.8在不同工作量水平下,在BrowseComp智能搜索评估和OSWorld-Verified计算机使用评估中的性能表现。
Sonnet 5(橙色线)相比Sonnet 4.6(灰色线)有了显著提升,并且比Opus 4.8(黄色线)涵盖了更广泛的性价比选择。它在中等工作量下提供了更高的成本效益;在某些任务中,其高工作量下的性能可以与Opus 4.8相媲美。用户可以在Sonnet 5和Opus 4.8之间调整工作量水平,以找到成本和性能的最佳平衡点。
下图显示了不同投入水平下的性价比曲线。前代产品Sonnet 4.6远逊于Opus 4.8,但Sonnet 5提供的性价比选择范围比Sonnet 4.6更广,在某些情况下甚至可以与Opus 4.8的性能水平相媲美。
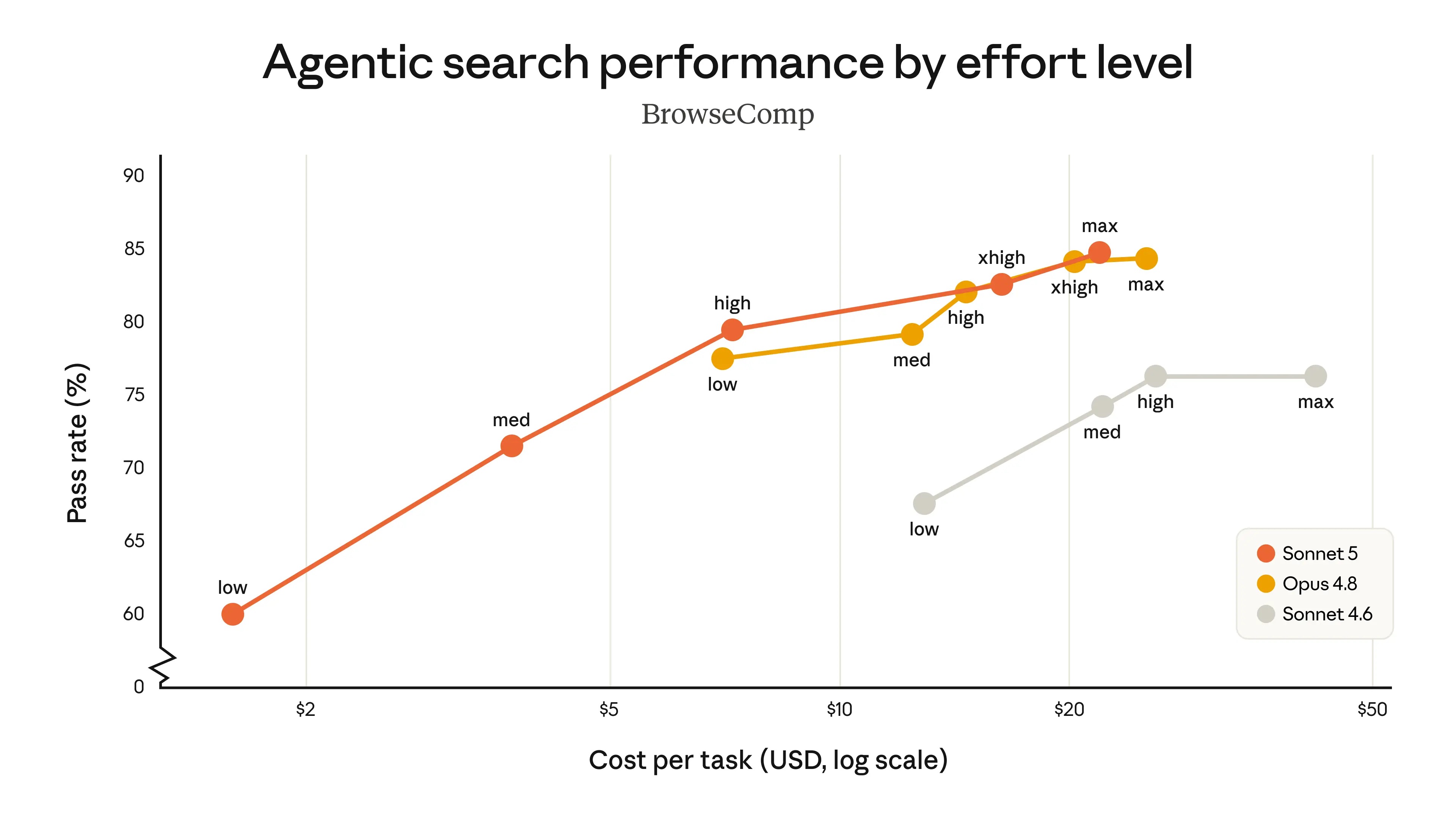
▲Agent搜索
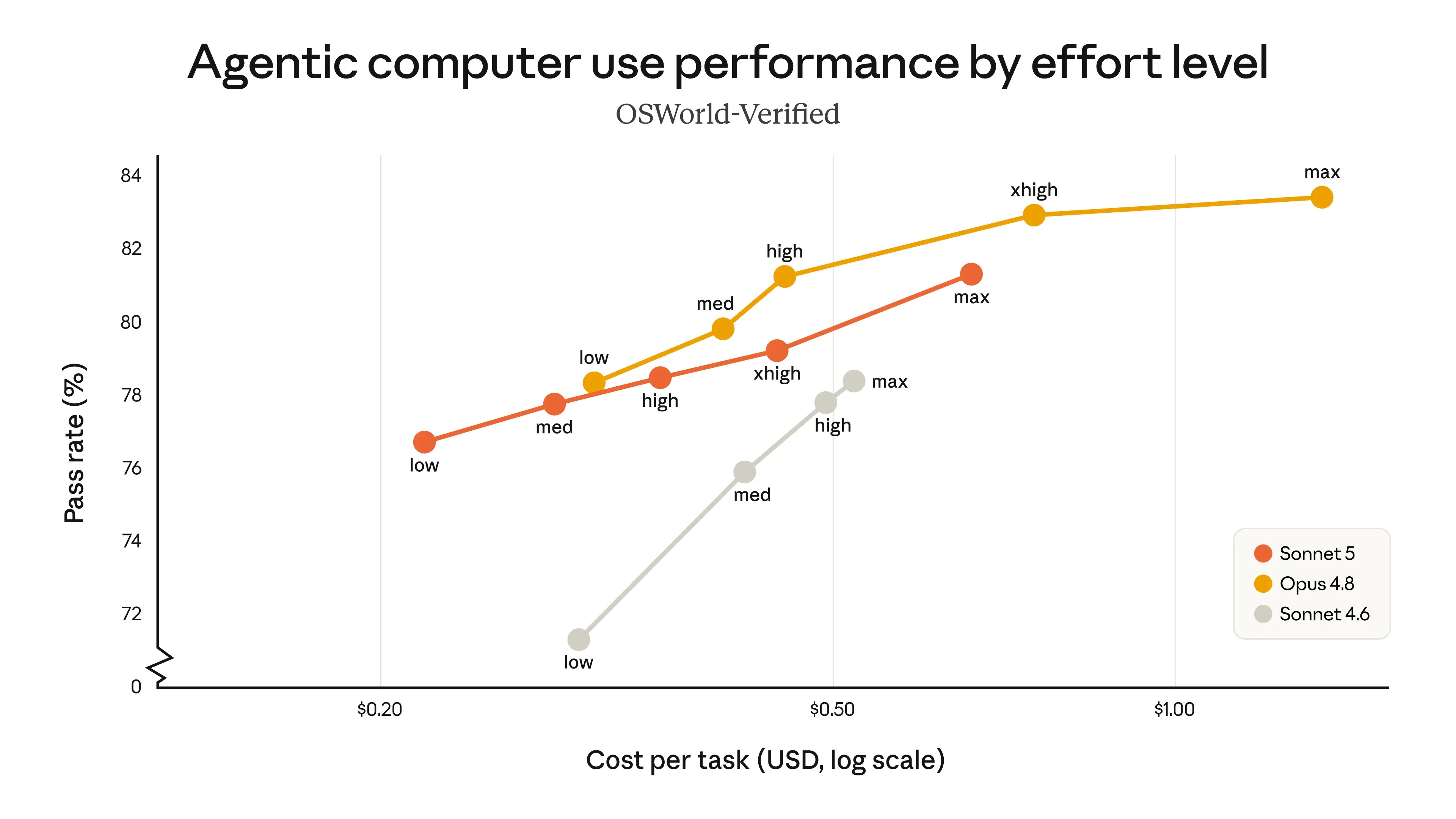
▲Agent计算机使用
图表显示了Sonnet 5的定价,但其实际成本甚至比图中所示还要低。Opus 4.8的定价为每百万输入token 5美元,每百万输出token 25美元。xhigh表示,Opus 4.8达到了超高投入水平。
来自早期体验合作伙伴的反馈一致,Sonnet 5比其前代产品更具自主性。测试人员描述了它如何完成以往Sonnet型号无法完成的复杂任务,如何在无需明确要求的情况下检查自身输出,以及它如何以极具吸引力的价格完成所有这些自主工作。
一位网友对比了Claude Sonnet 5与Claude Opus 4.8的体验结果,让它们分别创建一个关于Claude Sonnet 5的HTML落地页,认为就输出质量而言,Opus胜出;就模型速度和成本而言,Sonnet 5胜出。
其中Sonnet 5使用token:输入20.9k,输出14.2k,总成本:3.36美元,耗时:2分11秒。Opus 4.8:使用token:输入96.3k,输出73.8k,总成本:20.66美元,耗时:20分15秒。

▲左图为Opus 4.8生成网页,右图为Sonnet 5生成网页
二、安全防御提升,网络安全任务执行远逊于Opus与Mythos
Anthropic的部署前安全评估发现,Sonnet 5总体上比Sonnet 4.6有所改进。在Agent安全方面,该模型能够更好地拒绝恶意请求,并抵御即时注入攻击中的劫持尝试。与Sonnet 4.6相比,该模型表现出更低的幻觉和奉承行为发生率。
在Anthropic的自动化行为审查中,该审计测试各种不协调行为,例如滥用和欺骗等,Sonnet 5的总体得分更低(即更安全)。然而,与Opus 4.8和Claude Mythos Preview相比,Sonnet 5在此项评估中表现出的不协调行为发生率略高。
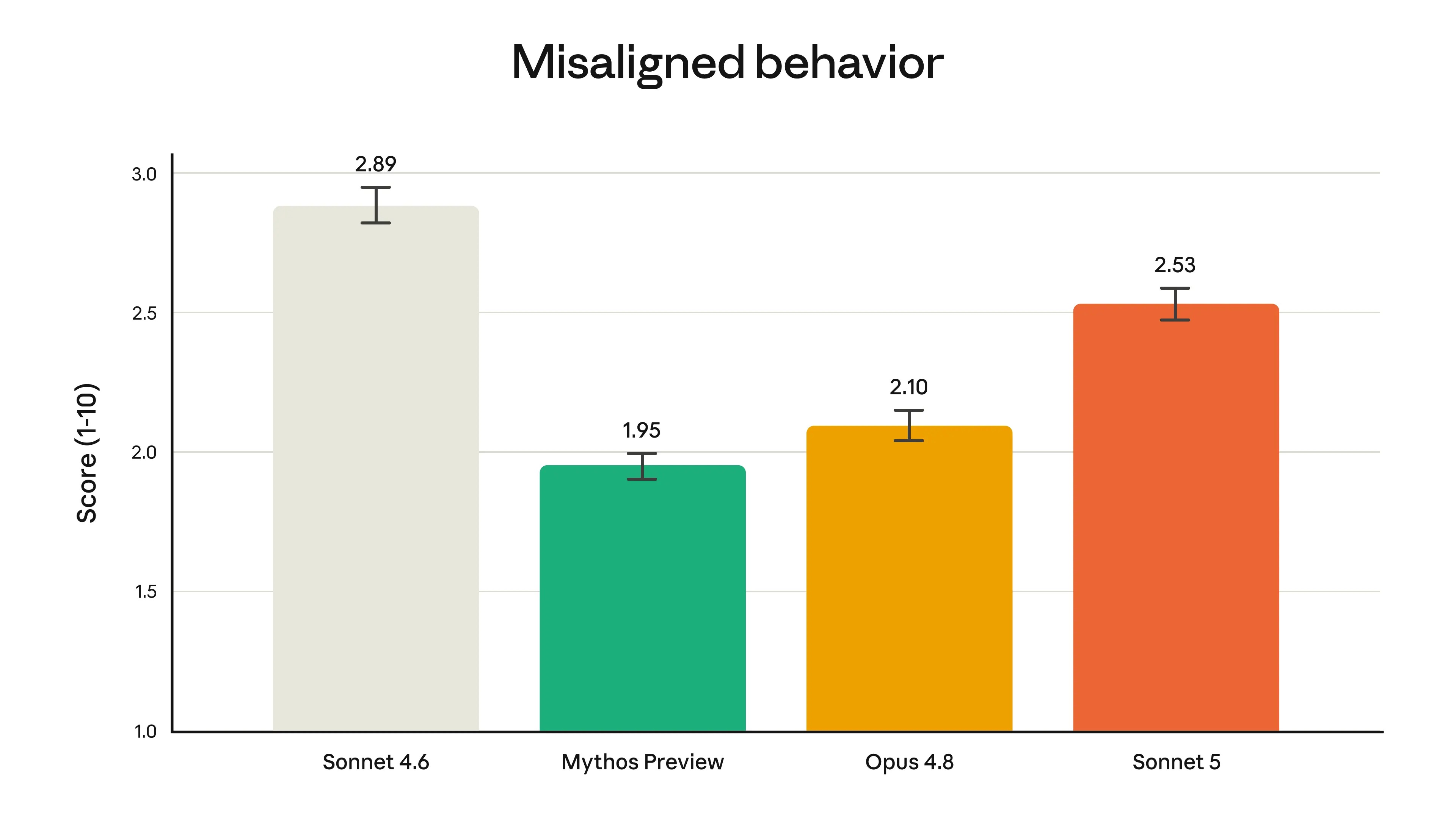
▲Claude模型中不一致行为的发生率
Anthropic并未刻意训练Sonnet 5执行网络安全任务。它可以执行一些常规的、无害的网络安全任务,但在测试潜在危险网络安全技能的评估中,例如开发软件漏洞利用程序,它的表现远逊于Opus 4.8和Mythos 5等模型。
下图展示了一项评估的得分,该评估测试了模型开发针对Firefox浏览器漏洞的利用程序的能力。Sonnet 5从未成功开发出完整的可用漏洞利用程序,但其部分成功率略高于Sonnet 4.6。后者的变化很可能是由于其通用智能的提升,而非特定训练的结果。
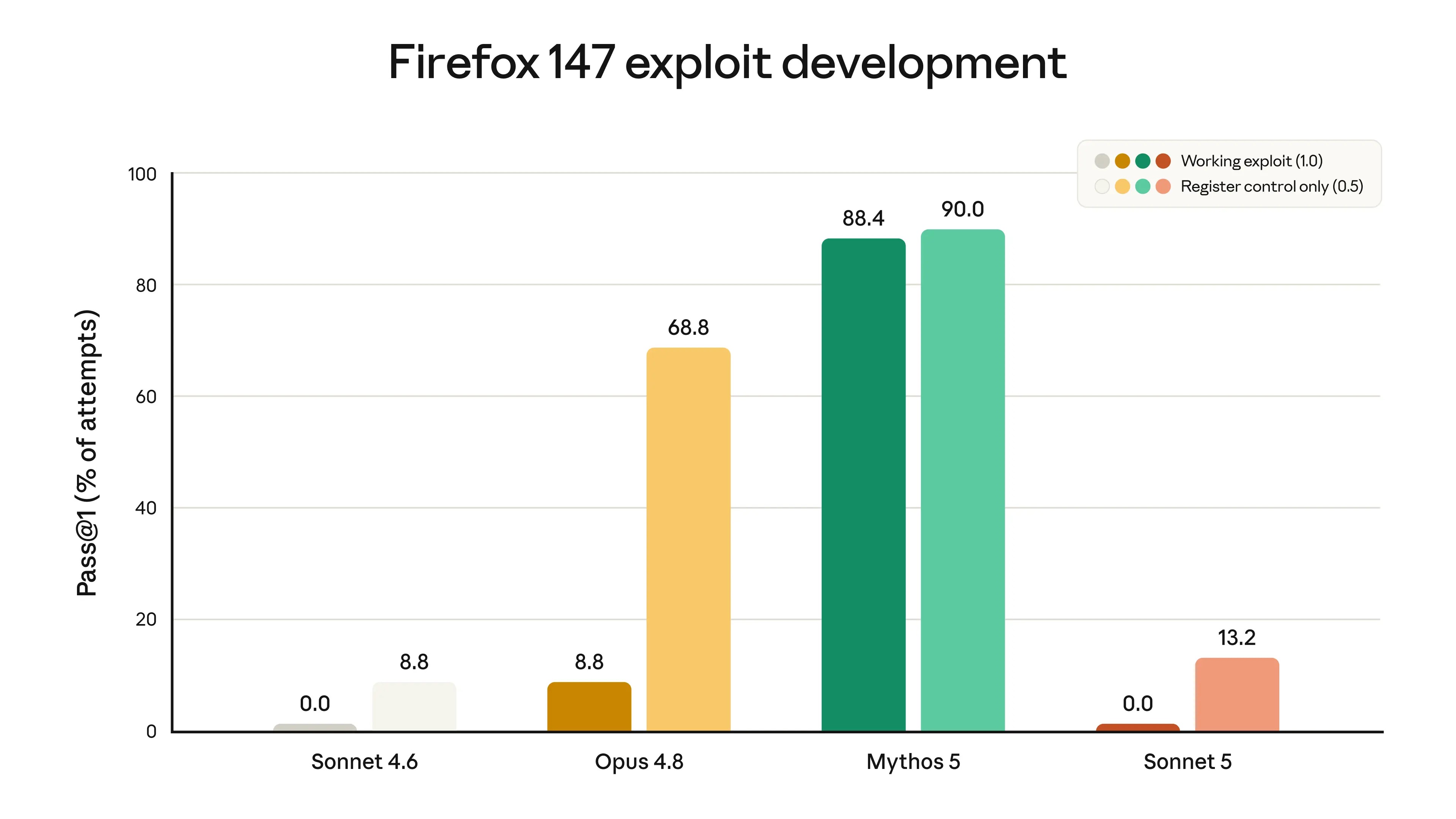
▲衡量Claude模型在开发针对Firefox 147软件漏洞的利用程序方面的成功率
如上图所示,对于每个模型,左侧条形图显示模型在无安全措施的情况下,开发出有效利用程序的频率;右侧条形图显示模型部分成功的频率。Sonnet的两个模型均未能成功开发出有效利用程序,得分均为0.0%;Sonnet 5的部分成功率略高于Sonnet 4.6。Sonnet的两个模型的网络安全能力均远逊于Opus 4.8和Mythos 5。
由于Sonnet 5在这些任务上比其前代产品功能更强大,Anthropic默认启用了网络安全防护功能。这些防护功能可以实时检测并阻止危险的网络攻击,与Claude Opus 4.7和4.8中的防护功能相同。因为Anthropic评估Sonnet 5的总体网络安全风险较低,所以其防护措施比Fable 5的防护措施宽松,Fable 5会阻止更广泛的网络安全攻击。
结语:Sonnet 5来了,但全网都在等Fable 5
曾几何时,Sonnet系列凭借3.5至3.7版本为开发者打开了Agent工程的大门,成为编码与工具调用的标杆。但随后几年,Opus系列在复杂推理和高端任务上持续领跑,让Sonnet逐渐退居“高性价比备选”之位。
如今,Sonnet 5试图宣告回归:在高投入场景下性能足以比肩Opus 4.8,成本更低。不过,对于Sonnet 5这种备选方案,很多网友并不买账,而是催着能力更强的Fable 5解禁。与此同时,Sonnet 5也被认为是面向GML-5.2等模型打响价格战,头部大模型厂商之间的Agent竞赛似乎已进入肉搏阶段。
来源:Anthropic、X
