








智东西(公众号:zhidxcom)
作者 | 李水青
编辑 | 心缘
智东西6月25日报道,6月24日,ISC 2026大会传来消息:中科曙光ParaStor F9000全闪存储系统同时登顶IO500生产型全节点和10节点双榜第一,成为首个拿下这项双料冠军的中国厂商。
这是中国存储产业的历史性时刻。过去,IO500生产型榜首长期被国际巨头垄断,国产存储首次站上了这个最严苛赛道的最高领奖台。
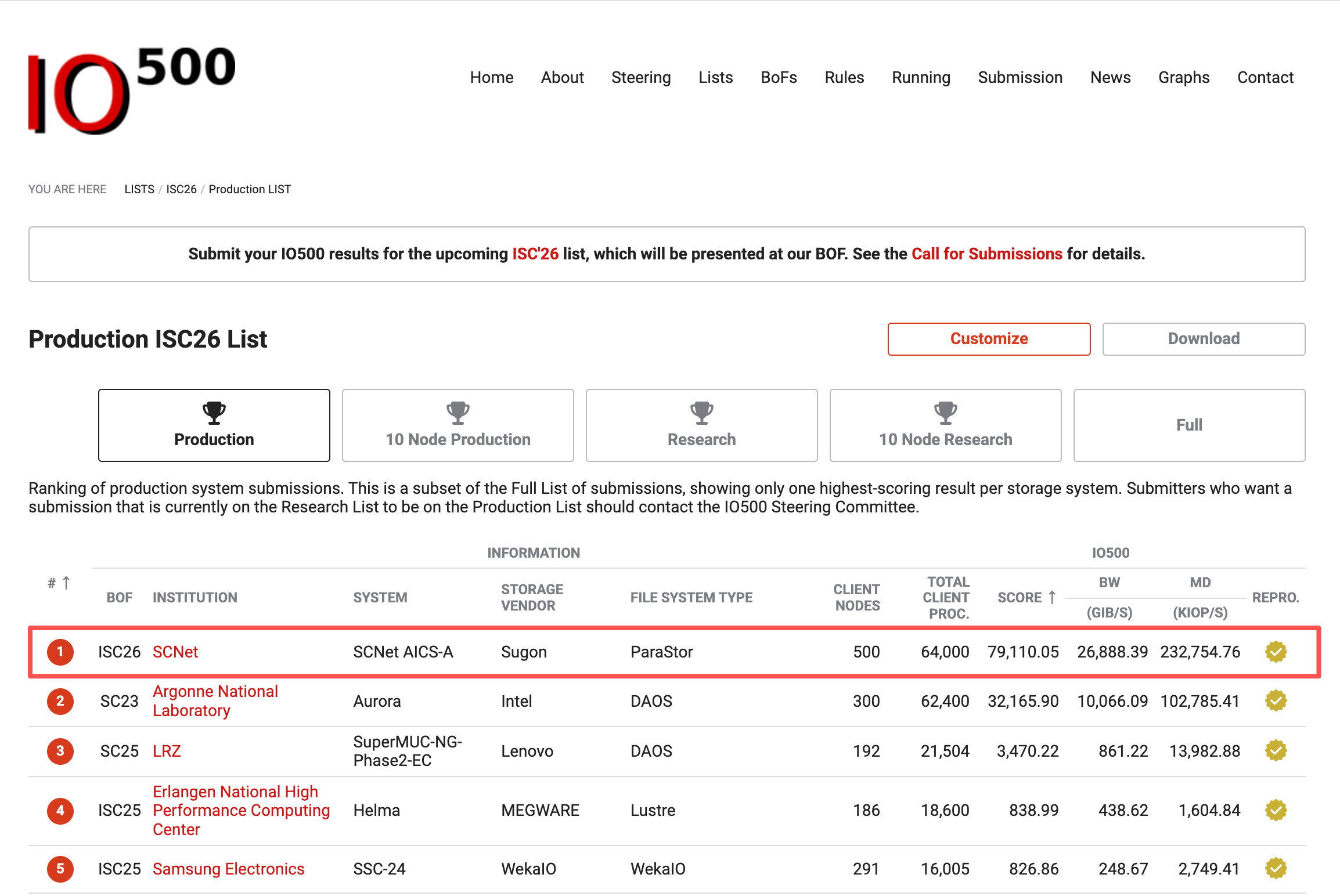
▲IO500 生产型全节点第一
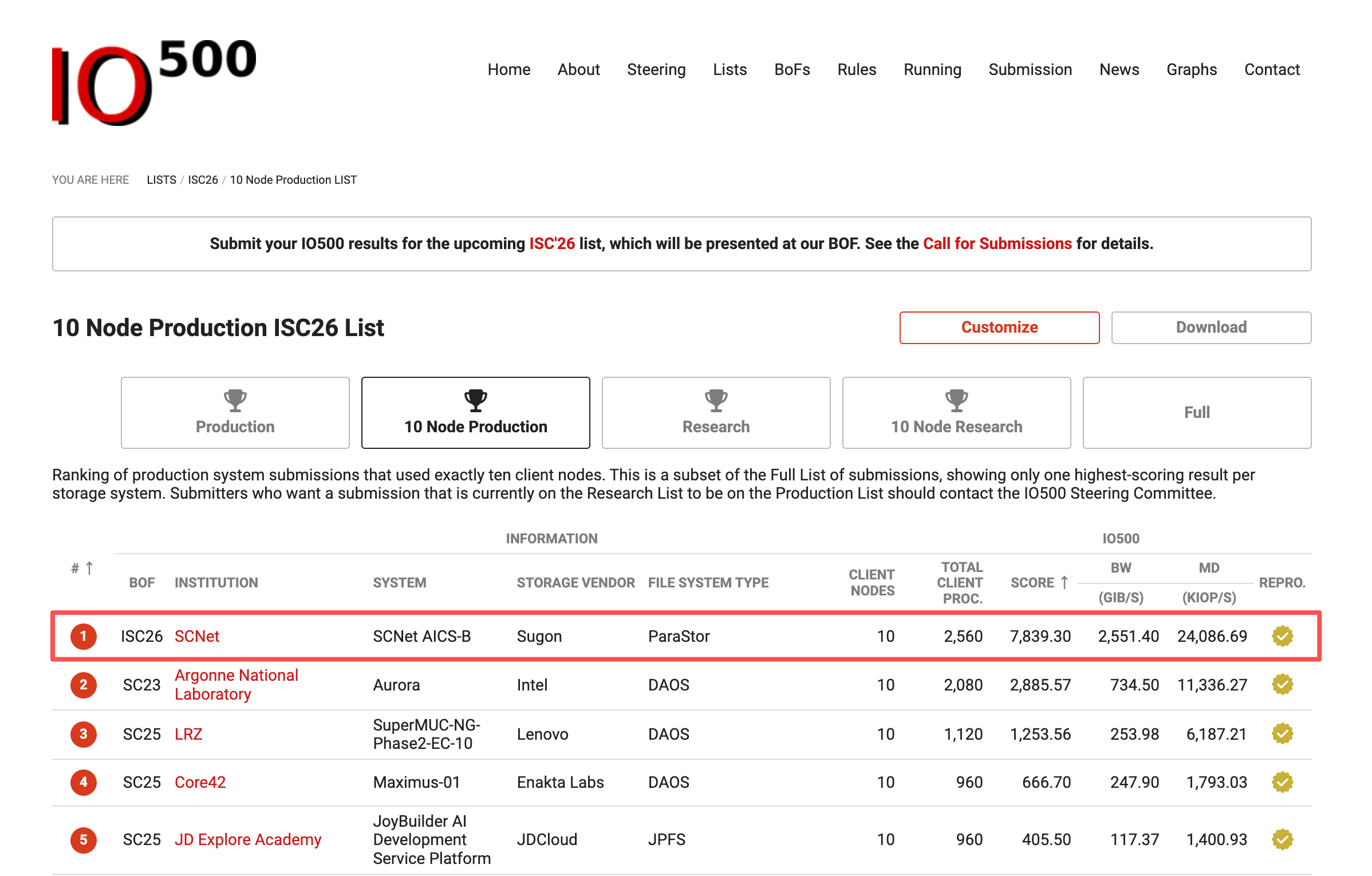
▲IO500 生产型10节点第一
过去很长时间里,存储只是算力叙事中的配角。当AI训练进入PB级吞吐时代,瓶颈从芯片转向了数据供给:GPU空转、训练中断、checkpoint恢复耗时数小时,根因都指向存储。存储,已成为决定GPU利用率的胜负手。
行业早已告别了只看纸面参数的时代。中国厂商此次登顶的IO500生产型榜单,堪称存储实战能力的试金石,它只认真实业务负载,中科曙光ParaStor F9000已在数万卡集群中稳定运行超过一年,稳定支撑上百个AI、科学计算应用。可以说,这次登顶是一次benchmark(基准测试)被真实业务“跑成了生产标准”的验证。
一、Benchmark迎来新拐点:存储不能只拼实验室成绩
benchmark为何如此重要?
在超算与AI基础设施领域,IO500已成为全球高性能存储系统最具权威性的评测基准,与定义算力的TOP500榜单共同构成了衡量超算产业实力的两大风向标。长期以来,包括英特尔、DDN等国际巨头,都将IO500视为展示技术实力的最高舞台。
其中,生产型榜单的要求极为严苛。该榜单仅纳入已在真实生产环境中长期运行的存储系统,要求满足实际业务负载、冗余设计与持续运行能力,部署周期通常以年计算。
中国存储行业过去不缺实验室冠军,缺的是能在生产环境扛旗的选手。
ParaStor F9000此次用双重验证改变了这一局面:
第一重验证来自IO500测试本身。IO500的测试套件本身就是对真实科研与工业场景I/O模式的模拟。无论是复杂目录结构下的小文件访问,还是海量并发环境中的元数据处理,其压力模型都与AI训练、科学计算等真实场景高度一致。
第二重验证更为关键,榜单成绩建立在实际业务运行的基础之上,是“先生产、再benchmark”。目前,ParaStor F9000已在数万卡scaleX超智融合集群中稳定运行超过一年,成功支撑了百余个AI与高性能计算领域的生产应用,涵盖大模型训练、科学计算、数据分析等关键场景。
这意味着,榜单成绩的形成路径已经发生改变:从“先benchmark,再寻找落地场景”,转变为“先生产,再benchmark”。
对于AI时代而言,这种变化意义重大。今天的大模型训练不再需要一个只能跑出峰值的系统,而需要一个能够持续支撑万卡集群7×24小时稳定运行的基础设施。
总的来说,AI时代benchmark依然重要,但只有经过生产验证的benchmark,才更具备产业价值。 
▲IO500 生产型全节点第一
▲IO500 生产型10节点第一
二、世界级成果,三项落地实践,把benchmark数字变成业务结果
登顶IO500是ParaStor F9000技术实力的全球认证,但benchmark数字再好看,最终要看的还是业务能不能跑出真效果。
ParaStor系列产品在三个截然不同的领域中,用实际成果证明国产存储已经走向全球最前沿。
1、具身智能领域:500GB/s聚合读带宽,让机器人“反应跟上思维”
具身智能是AI从数字世界走向物理世界的关键一跃,而具身智能大模型的训练对海量多模态数据的处理提出了极为苛刻的存储需求:激光雷达点云、深度图像、六维力觉数据、关节角度序列,数据类型繁多且吞吐量巨大。
以智元机器人为例,中科曙光为其提供了基于ParaStor分布式全闪存储的专属解决方案,支撑具身智能机器人的快速迭代。系统提供超过500GB/s的聚合读带宽,满足具身智能大模型训练对海量多模态数据的实时处理需求;同时实现低时延数据访问,保障机器人实时响应和丝滑交互体验,加速具身智能技术的商用落地。
当机器人需要在毫秒级时间内完成感知、决策、执行的全链路闭环,存储的响应速度成为决定机器人“反应能不能跟上思维”的产业命门。
2、自动驾驶领域:每日TB级路采数据实时接入,研发周期缩短40%
自动驾驶是典型的数据驱动产业。每一辆测试车每天产生TB级的摄像头、激光雷达、毫米波雷达等多源异构数据,这些数据需要实时接入、高效存储、快速流转,才能驱动从“数据采集—清洗标注—模型训练—仿真验证”的全流程闭环。
中科曙光连续为国内头部造车新势力提供超百PB存储资源,通过智能数据分层策略,在支撑海量数据增长的同时降低总体TCO达40%。在实际效果上,ParaStor支撑的完整数据闭环将模型研发周期缩短了40%以上。
对于竞争白热化的新能源汽车赛道,研发周期每缩短一个月,就意味着产品迭代快人一步、市场窗口多抢一轮。
3、AI for Science领域:动力学模拟,刷新世界级计算纪录
AI for Science正在成为科学研究的新范式,而分子动力学模拟是这一范式中最具挑战性的场景之一。百亿级原子的相互作用,每一步模拟都伴随着天文数字级别的数据读写需求。
ParaStor F9000联合龙讯旷腾MatPL软件,依托scaleX万卡超集群,完成了414.7亿原子规模液态水分子动力学模拟计算,刷新世界纪录。如此庞大的模拟规模,需要系统同时处理海量小文件、高并发读写以及极低时延访问,对存储提出极高要求。ParaStor F9000提供的高吞吐、低时延能力,使同规模算力能够在更短时间内完成更复杂计算。
可以看到,三项实践,三种截然不同的业务负载,无一例外地指向同一个事实:ParaStor F9000已经部署在前沿产业场景中、日复一日支撑真实业务,国产存储已经具备了定义行业标准的能力。

▲中科曙光ParaStor F9000全闪存储系统
三、连续两年市占率第一,“平替时代”已翻篇
如果只是benchmark好看,市场不会持续买单。
知名行研机构IDC数据显示,中科曙光AI存储已连续两年位列中国市场第一。作为旗舰产品,ParaStor F9000已成为行业公认的大模型训练优选存储方案。这说明行业客户正在用真金白银投票。
市场为何持续买单?
核心原因在于,AI时代,存储开始真正参与算力生产。ParaStor F9000“以存提算”带来的显著经济效益:通过芯片级协同、软硬件协同以及AI应用协同,构建三级协同架构,让存储深度参与训练和推理过程。
在训练加速与部署效率方面,ParaStor F9000凭借五级加速体系,从本地内存加速、SSD加速层、XDS直通技术、网络加速和存储节点高速层,可将集群训练效率提升50%。该系统还支持千卡、万卡乃至十万卡级集群整机柜交付方案,可将千亿参数模型部署时间缩短50%。这意味着企业能够以更短的时间窗口完成模型迭代,抢占市场先机。
在推理阶段,KV Cache已经成为大模型推理的重要瓶颈。ParaStor F9000内置KV Cache智能卸载引擎,可降低60%以上GPU显存占用,单卡并发推理承载量提升2至10倍,AI推理整体时延降低80%。这意味着,同样数量的GPU,可以承载更多业务。
在当前高端GPU仍然稀缺且昂贵的背景下,这种能力有望大幅提高企业的投资回报率。
因此,国产存储的角色也正在发生变化。过去谈到国产存储,行业的惯性评价是“性价比”高,可以作为国外大厂的“平替”。而今天,ParaStor F9000在万卡乃至十万卡集群中作为核心存储底座,被部署在最关键的业务链路上,已变为“优选”。
结语:中国存储,进入定义标准的时刻
回顾中科曙光在存储领域的路径:2022年,ParaStor分布式存储首次登顶IO500 10节点榜单,将世界纪录提升146%;此后的集中式全闪存储FlashNexus在SPC-1国际性能测试中亦取得领先成绩;如今,ParaStor F9000在最具实战参考价值的生产型榜单上包揽双冠……从单点突破到全线领先,曙光存储用四年时间完成了一条清晰的上升曲线。
比榜单名次更重要的是榜单背后的产业逻辑。当benchmark从实验室走进生产环境,当国产从平替标签变成优选标签,存储行业正在经历一场深刻的价值重估。中国存储企业开始参与定义下一代AI基础设施的技术标准。
在AI大模型向万亿参数迈进、科学计算向百亿原子尺度深入、具身智能从实验室走向工厂车间的时代浪潮中,存储的底层能力将成为决定产业上限的关键变量。中科曙光此次IO500双冠,或许是一个国运级信号:中国存储,已经到了可以定义标准的时刻。
