








智东西(公众号:zhidxcom)
作者 | 王涵
编辑 | 漠影

▲鼠标点击烟花

▲多摆混沌系统模拟器
以上这些,都是用云知声最新发布的U2大模型做出来的。
智东西6月8日报道,今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。
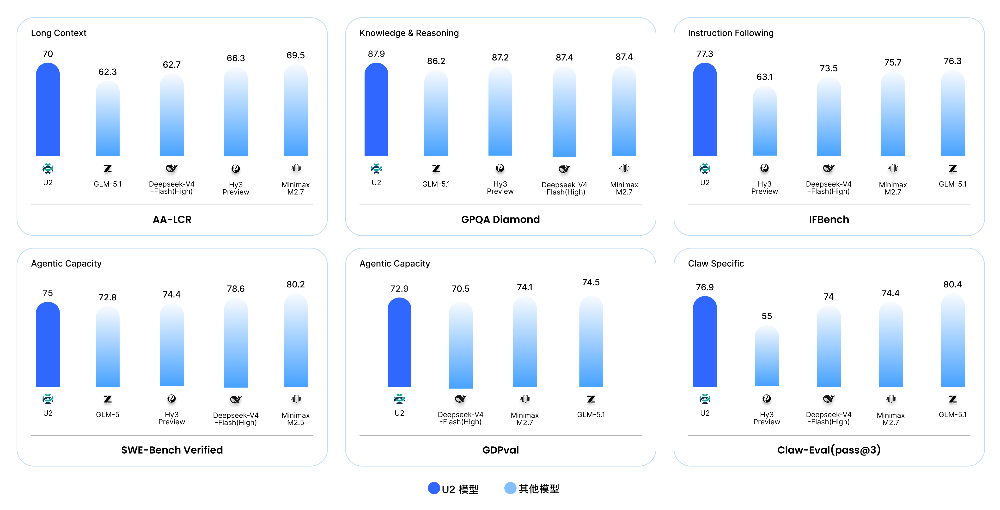
只从基准测试上看,云知声U2就已经跻身国产大模型第一阵列了。
长上下文能力上,U2在AA-LCR评测中得到70分,在对比模型中排在首位,比第二名的MiniMax M2.5/M2.7高出0.5分。知识与推理上,U2也以87.9分的成绩领跑。指令遵循能力方面,U2同样表现突出,IFBench得分77.3分,比第二名的GLM-5.1高出1分。
智能体能力方面,U2在SWE-Bench Verified评测中取得75分,排名第三。Claw-Eval(pass@3)方面,U2获得76.9分,排名仅次于MiniMax M2.5/M2.7。在面向真实办公与知识工作交付能力的GDPval上,U2取得72.5分,展现出扎实的专业办公能力。
提到云知声,许多人的第一反应或许还停留在“那家主攻语音技术的科技公司”。然而,从2012年成立之初深耕智能语音交互,到如今的原生智能体大模型公司,云知声早已寻找到了最适合自己的那条路,完成了蜕变。
一、自动生成俄罗斯方块,2分钟做出大宗商品研报
云知声团队告诉智东西,在当下这个时间衡量今天的大模型价值,已经不能再单纯比拼参数规模和内容生成长度。当AI真正进入真实工作流,用户关心的不再只是模型能否给出一个漂亮回答,而是它能否真正把任务完成。
因此,云知声U2从设计之初,就不是一个单纯面向聊天场景的通用模型,而是一款有着近3000亿参数、面向任务执行的原生智能体大模型。
U2具备长程工作编排与自主纠错能力,这意味着它可以像一位高级工程师那样,把一个复杂任务拆解成多个子步骤,按序执行,并在过程中自我校验、自动修正。
比如编程任务,U2不仅能完成后端逻辑,还能胜任前端全流程开发:从项目功能开发、页面排布到视觉方案设计,均可端到端落地。
我让U2生成一个新产品发布倒数页面,要求包含邮箱信息填写和各个平台联系方式的互动按钮。几乎没有反应时间,它就直接交付了内容清晰、可运行的页面。

这套长程编排与自主纠错机制,也让U2能够独立完成虚拟系统、游戏等完整应用的交付。例如,用户不需要输入完整的游戏逻辑,U2就可以自动搜索相关条件,生成一个符合要求且可玩度很高的俄罗斯方块小游戏。

面对复杂的知识工作,U2同样不靠简单拼接信息。它具备跨行业数据检索、多源信息清洗与专业文献深度结构化分析的能力,能够并行调用多个工具,将零散、异构的数据整合为有逻辑、有结论的分析结果。
我交给了U2一个十分艰巨的任务:分析2026年5月原油、黄金、铜、农产品等大宗商品走势,结合地缘政治、供需关系、美元指数、库存数据,判断短期价格波动与中长期趋势。
这个任务不仅需要对当下地缘政治局面十分了解,还要理解地缘政治与大宗商品的内在逻辑关系,需要扎实的历史知识和金融知识。
面对这个综合金融问题,U2几乎没有反应时间,自动调取了所需的网页检索和分析工具,在一两分钟内就洋洋洒洒生成了一篇超5000 字、带数据表格的分析报告,展现出十分强大的深度结构化分析能力。

除此之外,U2还通过Agentic Harness(智能体编排框架)精准落地各项办公任务。无论是生成报告、分析数据,还是写周报月报这类琐碎工作,U2都能自动理解指令、编排执行路径,给打工人卸下不少负担。
用户只需一句“帮我写一下本周的周报”,U2就会主动梳理已完成事项、提取关键数据、调用docx技能,并且模型还会自动校验其生成结果的准确度。从结果看来,U2输出的周报文档,结构清晰、内容完整详实,可以直接拿来就用。

二、不拼参数拼密度,云知声U2把每一个Token都用在刀刃上
U2模型的核心创新,目的都是指向一个清晰的目标:让模型在真实业务场景中展现出超越体积的智能与效率。
这其中,模型的高智能密度和高Token价值就至关重要。
云知声通过对高质量知识数据的深度提纯,实现知识点级的精准萃取与结构化编码,彻底剔除冗余低质信息,让小参数模型获得与超大模型相当的知识承载能力与智能表现。
U2采用高效稀疏架构,激活参数仅为总参数量的约十分之一,推理成本与激活参数规模线性锚定,高并发场景下的成本优势尤为突出。
并且,通过优化语义表征与推理路径压缩,技术团队让模型的单个Token承载语义、信息量都远超传统模型,用更少Token完成更复杂任务,大幅降低企业部署的算力门槛与推理延迟。
传统显式思维链虽然具备较强可解释性,但往往需要生成大量中间推理文本,带来更高Token消耗与推理延迟。而隐空间推理,却可能在复杂任务中出现逻辑漂移,缺乏足够的可控性与验证能力。
因此,在复杂推理层面,U2进一步引入了一个十分独特的机制:混合思考机制。
它借鉴人脑解题方式:输出前先在隐藏表征中形成连续思考,在高维空间同步探索多条路径,再映射为后续显式推理,避免将全部中间步骤逐一展开。
其中,U2引入了可控隐空间展开(Bounded Latent Rollout)与熵感知切换(Entropy-aware Switching)机制,使模型能够根据推理过程中的不确定性动态调整思考方式:当隐式探索稳定时,模型保持高效推理;当不确定性升高、推理路径可能发散时,则及时回到显式思维链,通过确定性 Token 完成精准推导与结果收敛。
这套设计在保留多路径探索与可验证性的同时,还节省了约25%的思考Token消耗。
在任务执行层面,U2使用了Agent-Harness协同训练范式,将模型原生Agent能力提升与Harness迭代优化纳入同一训练闭环:一方面,Harness根据U2的模型特点持续优化任务执行链路;另一方面,真实任务中产生的高质量执行轨迹,又反过来强化模型的任务规划、工具调用、过程纠错和结果验收能力。
总体看下来,U2整套设计的落点非常清晰:用更小的参数、更少的Token、更低的算力,在真实业务场景中交付稳定、可靠、可验证的智能结果。
三、端云协同叠加场景深耕,云知声走出大模型商业化样本
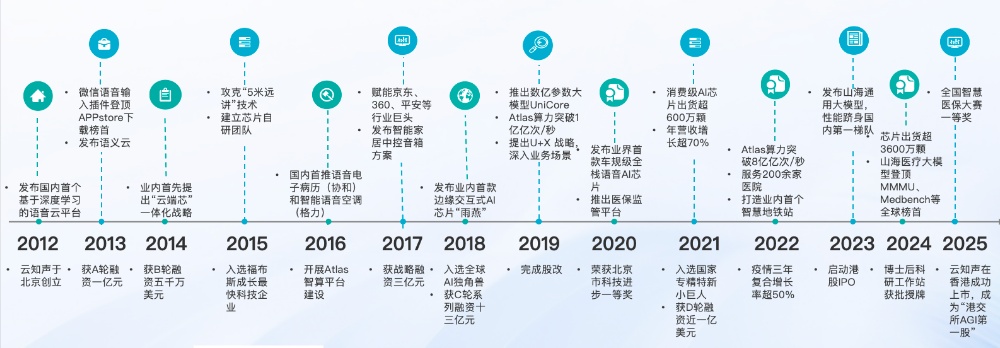
云知声自2012年创立以来,走出了一条独特的发展道路。
首先,在技术硬实力上,云知声拥有仅少数厂商才具备的全栈AI能力,其不仅能做云端,更能做端侧,实现了端云协同。不同于单纯的模型层厂商,云知声手握“芯片+算力+模型+应用”的完整链条。其自研的“蜂鸟”等系列芯片出货量已超亿颗,这使得云知声在端侧大模型的部署上拥有相当的优势。
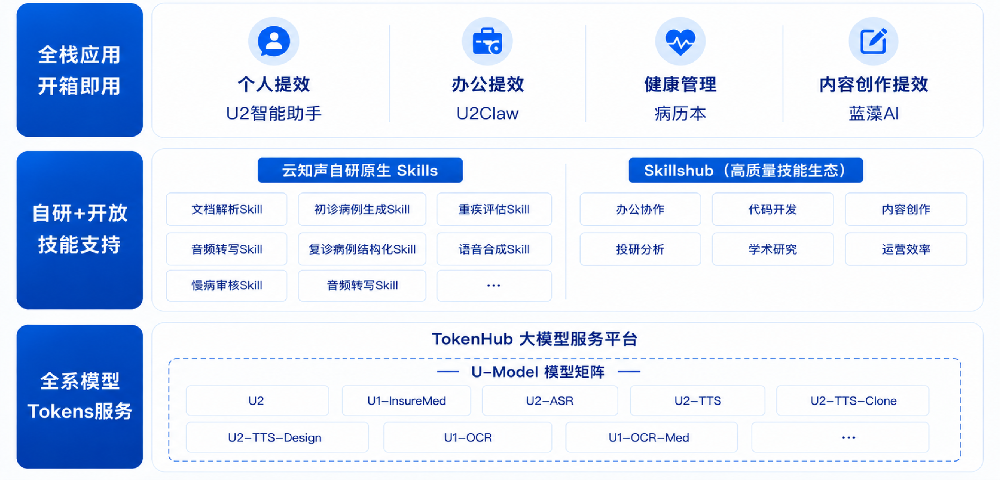
其次,在商业化壁垒上,云知声的产品已广泛落地于智慧医疗、智慧交通、智慧生活及物联网(AIoT)等多个领域。
在智慧医疗领域,其产品已在近450家医院实现规模化部署,涵盖病历生成与质控、辅助诊疗及保险和医保监管等场景;在智慧交通领域,产品应用于深圳、广州、青岛等多地地铁及航空枢纽,提供智慧客服、语音购票及智能调度等解决方案;在智慧生活与AIoT领域,通过“芯片+模型”方案,赋能智能家居、智慧座舱、智慧营销等场景,服务众多行业头部企业。
这种在高价值B端场景的扎根,让云知声成为了国产大模型公司中变现能力最强、离盈利最近的那一个。
财报数据也着实证明了这一点。今年3月26日,云知声交出了一张“硬核成绩单”:该公司2025年营收12.1亿元,同比增长29%;其中大模型相关收入达6.1亿元,同比暴涨1076%,撑起半壁江山。更值得一提的是,其亏损显著收窄,全年经调整净亏损约1.3亿元,同比下降近25%,下半年更是大幅缩窄92%,几近盈亏平衡。
受益于高质量场景Token的需求激增,云知声5月Token调用收入的ARR环比暴涨600%,预计6月将继续保持高增长,ARR达到1500万美元。
这意味着,其收入与客户AI使用强度已关联,云知声业务的规模天花板已经全面打开。
结语:跻身国产大模型第一梯队后,云知声再次捅破行业天花板
站在2026年6月的时间点回望,从2012年以语音技术起家,到2025年登陆港交所,再到如今上市一周年之际发布U2大模型,云知声用14年时间完成了从智能交互到AGI的跨越。
云知声的特殊性在于,它从未脱离过产业场景。长达十年的“云端芯”布局,云知声积累了深厚的垂直行业Know-How。U2大模型发布后,立刻就能在智慧医疗、智慧交通、智慧座舱等场景中产生化学反应,成为生产力工具。
U2的发布,不仅是其自身的一次产品迭代,更是国产大模型走向成熟化、产业化的一个缩影。
