








智东西(公众号:zhidxcom)
作者 | 王涵
编辑 | 漠影
2026年,AI专用HBM内存价格暴涨超165%,显存/HBM正在成为模型扩展最昂贵、最稀缺的资源之一,模型公司的核心推理成本居高不下;
而另一边,高端AI芯片对华出口管制反复横跳,让国产算力生态在面临高昂过路费与供应链安全风险的夹缝中艰难求生。
两件事叠加,指向同一个问题:在硬件受限的情况下,国产模型厂商,该怎么继续做模型?
智东西5月25日报道,在2026年5月23日的华为昇腾开发者大会上,面壁智能联合清华大学、OpenBMB开源社区,正式发布了BitCPM-CANN——全球首个完全基于国产华为昇腾平台训练并开源的三值(1.58-bit)大模型。0.5B到8B全尺寸开源,推理显存节省5/6。
BitCPM-CANN有什么不同?它的亮相意味着什么?国产芯片训练的路,又能不能走通呢?
一、1.58-bit三值权重如何跑通昇腾,省下6倍显存?
BitCPM-CANN是全球首个完全基于国产算力平台(华为昇腾)训练并开源的三值(1.58-bit)大模型。
那什么是三值?普通大模型的参数通常用16位或8位浮点数表示,而BitCPM-CANN每个参数只能取三个值:-1、0、+1。理论上,其每个参数平均只需1.58 bit来存储。
为了节省显存,业界的传统思路一般是把32位精度降到8位,这样确实会损失一些精度,但能换来4倍的显存节省。而BitCPM-CANN路线不太一样:团队认为压缩后的每一个比特,都应该尽可能多地学进知识,而不是白白浪费掉。
所以,虽然BitCPM-CANN只有1.58 bit,但是它的信息密度其实非常高,不是“牺牲精度换内存”的妥协。这个特点,在HBM紧缺、长上下文处理、MoE扩展这类特别吃显存的场景里,尤其能发挥价值。
那BitCPM-CANN是怎么做到的?其技术路线可以划分为三个关键步骤:
第一步:把1.58-bit三值权重跑进训练算子。
研发团队采用STE(直通估计器)方案,在训练阶段保留全精度残差用于梯度更新,在导出阶段则输出严格的三值权重,从而将离散权重真正嵌入华为昇腾的训练算子中。
第二步:用完整QAT加后训练蒸馏守住模型能力。
团队在昇腾上完整部署了量化感知训练(QAT)与后训练蒸馏流程,在保证模型效果不下降的前提下,将训练吞吐量的损失控制在仅5%的水平。
第三步:把低比特能力沉淀为MindSpeed训练基础设施。
团队还基于Megatron‑LM框架嵌入可插拔的QAT并行线性层,统一了checkpoint格式并支持32K长序列训练,使低比特训练能力成为昇腾平台上可复用、可扩展的公共底座。
二、60B入终端:BitCPM-CANN撬动端侧AI落地
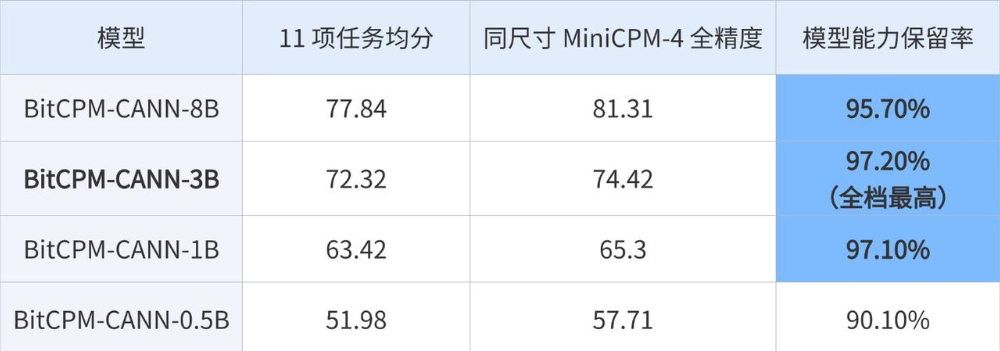
目前,BitCPM-CANN已开源0.5B到8B的全尺寸版本,在1B、3B、8B三个规格上,模型均保留了全精度版本95.7%以上的能力,其中3B版本达到97.2%。即使在数学、代码等高敏感任务上,3B版本的表现也已进入接近全精度的区间。
这些数据意味着1.58-bit已经具备面向真实模型族、真实评测集、真实训练栈的工程说服力。
端侧,这是BitCPM-CANN价值最容易被感知到的地方,因为端侧的用户最多,场景也最广。
拿8B模型来说,传统BF16格式要占大约16GB显存,这个数字已经超过绝大多数手机的内存容量了,更别提还要留给其他应用空间。
BitCPM-CANN把它压缩到2-3GB,手机内存就能轻松跑起来。手机厂商不需要为了跑大模型去堆昂贵的超大内存,普通旗舰机就能流畅运行8B级别的对话模型。
如果再往前走一步,结合MoE架构——每次只激活一部分参数——未来甚至有望把60B级别的模型塞进笔记本电脑、平板,甚至高端手机里。
硬件这边也在同步推进。高通的8850/8397等新一代端侧芯片,已经原生支持2-bit以下的低比特推理。芯片厂商早就把跑道铺好了,就差一个好模型。BitCPM-CANN刚好提供1.58-bit的权重,跟硬件能力完美匹配。
更值得关注的是,BitCPM-CANN全都基于华为昇腾芯片搭建,实现了全链路原生适配国产算力,跟英伟达CUDA生态没有依赖关系。
这意味着其整个训练流程——前向计算、反向传播、量化算子的实现、分布式训练的调度——全部在昇腾上原生完成,中间不需要去CUDA上跑一遍验证再搬回来。
这是昇腾平台上第一个完整跑通1.58-bit训练,并且做了全精度对标评测的公开成果,模型规模直接推到了8B量级,不是几百兆的小模型演示。
国产NPU在大规模三值量化训练这个方向上,之前几乎没有公开的系统化成果,BitCPM-CANN算是把这块空白补上了。
未来,昇腾生态里的低比特模型研发,都可以依托这套底座往前走。环境层、长序列支持、并行策略、融合算子、调试工具,一套链路已经沉淀下来了。后续其他团队想在昇腾上做低比特训练,不需要再从零开始踩坑。
国产芯片、国产模型、国产训练框架一体化的自主产业链条,正在一点点变成现实。
三、四年深耕,全栈自研:面壁智能如何掌握端侧AI话语权?
BitCPM-CANN并非凭空出现,而是面壁智能在端侧AI这条路线上长期深耕的自然结果。
针对端侧AI,面壁已形成自己的模型矩阵——“小钢炮”系列(MiniCPM)。顾名思义,这是参数虽小、能力却强的一系列模型。MiniCPM在GitHub上累计收获超3万星标,Hugging Face开源总下载量超过3000万,成为中国端侧AI领域最受欢迎的开源模型家族之一。
但把时间拨回面壁成立之初,情况远没有这么乐观。2022年,国产芯片在训练大模型上尚不成熟,国内AI基础设施与国外差距明显。也正因如此,绝大多数公司选择了最省事的路径——直接依赖英伟达CUDA生态。
然而,面壁智能却做了一个截然不同的决定:自己写框架,自己搭底座。面壁智能从一开始就不绑定CUDA,换句话说,面壁智能的工程师从头就已经在亲手解决那些底层问题,例如显存怎么分配、通信怎么优化、算子怎么融合。
更重要的是,这个起点引发了一连串的技术积累。此后,他们自研了一套训练框架,取名BM-Train(Big Model Train)。
从稀疏架构InfLLM到低比特量化方法BitCPM、推理框架CPM.cu,面壁智能逐步构建起覆盖训练到推理的全栈端侧技术体系。正是这些积累,让面壁智能能够把验证成熟的1.58-bit训练方法,完整地搬到昇腾平台上,做出BitCPM-CANN,从底层算子到训练框架,全链路在昇腾原生跑通。
更难得的是,他们在国产芯片生态上的积累远不止昇腾一家。此前,面壁智能曾参与协助华为昇腾、鲲鹏,以及寒武纪、天数智芯等国产芯片构建和优化软件栈。这些经历让面壁智能建立起了对国产芯片生态的独特认知:知道坑在哪,也知道怎么绕过去。
端侧大模型的性能释放,离不开模型厂商与芯片厂商的共同投入。在这个赛道上,面壁智能追求的从来不只是参与,而是成为推动者与构建者。
结语:硬件受限,模型效率先行
过去两年,行业把Scaling Law奉为圭臬,算力成了唯一的门槛。
而BitCPM-CANN代表了另一条路线:在硬件给定的前提下,把模型的信息密度推向极限。更重要的是,BitCPM-CANN证明了这条路线可以在国产算力上完整跑通。
回到最开头的那个问题“在硬件受限的情况下,国产模型厂商,该怎么继续做大模型?”
面壁智能用BitCPM-CANN给出了答案:当硬件追赶需要时间,模型效率可以先行。
