








以往大家习惯将 AI 能力依赖于公有云服务,而随着 OpenClaw 等智能体工具的快速普及,不管是个人开发者还是企业更需要一个 7×24 小时运行在本地、可直接响应指令的 “数字员工”。但云端方案存在的数据隐私风险与持续高昂的 API、Token 成本,让工业级智能体在规模化落地时面临瓶颈,独立部署大模型服务已成为企业构建自主可控 AI 能力的必然选择。
众智FlagOS 是一款完全开源的 AI 系统软件栈,支持多款异构 AI 芯片,可让 AI 模型与智能体轻松实现快速部署。本次 FlagOS 联合腾讯云 HAI(面向AI和科学计算的容器镜像中心),将 Qwen3-4B-hygon-flagos 模型镜像正式上线腾讯云 HAI 社区,开发者可直接拉取使用。基于该镜像,可快速在加速卡上运行FlagOS + OpenClaw,实现小模型驱动智能体执行,为企业和开发者从公有云 API 转向自建本地 AI 服务提供了可落地的实践方案。
安装及测试过程
基于 FlagOS 系统软件栈的跨芯能力,众智 FlagOS 社区把 Qwen3-4B 适配至多款GPU硬件。以下内容重点介绍如何部署与配置 FlagOS 版 Qwen3-4B的过程,仅用于复现实验结果,不影响对 Agent 能力的判断。
1.安装Qwen3-4B-hygon-flagos
- 首先,从 HAI 社区平台找到 Qwen3-4B-hygon-FlagOS,根据md拉取模型并启动服务。
以 ModelScope为例,下载模型权重
|
- 点击【部署当前镜像】获取镜像拉取命令,从 HAI 社区拉取镜像
|
- 通过下面的代码,启动容器。
这段代码可直接复制使用,也可以根据需要修改容器名,即在第4行–name=flagos对 name 进行修改。
|
- 进入容器(如果上一步修改了容器名,这里要将flagos对 name 进行修改。
|
- 启动服务
|
2.安装配置OpenClaw
安装过程: 参见:https://github.com/openclaw/openclaw?spm=5176.28103460.0.0.696675514ZMILC , 通过源码方式,安装 OpenClaw。
|
配置过程:
- 访问链接以下链接:https://cloud.tencent.com/developer/article/2625144,文中有给出通用的”模型配置”文件格式,可以直接套用,套用后命令如下。
需要注意的是,配置本地模型时,厂商一定是加速推理工具如vllm。
|
执行之后出现如下信息提示: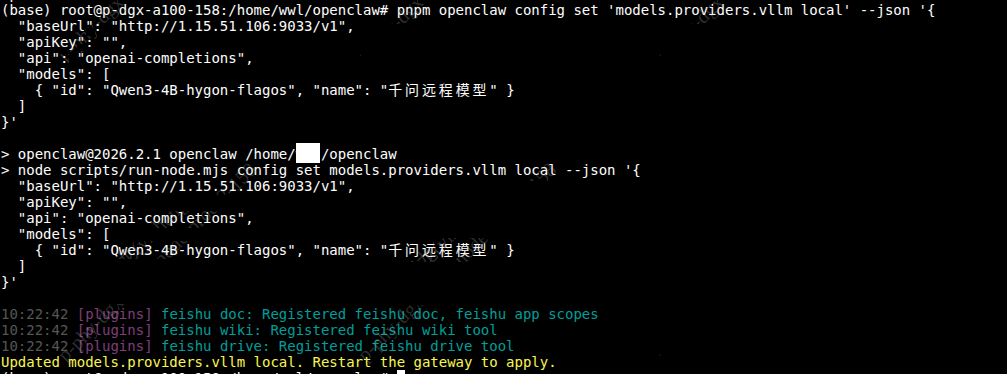
启用并设置为默认模型
|
|
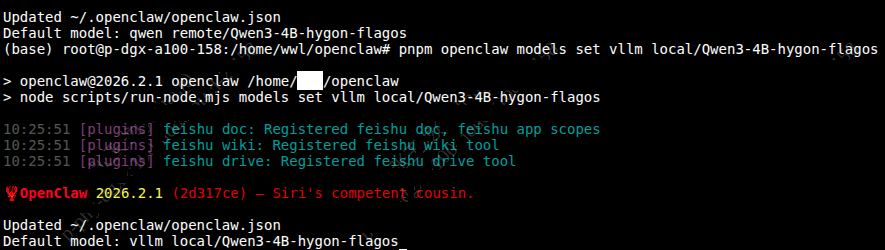
可以看到当前默认模型已经切换为 Qwen3-4B-hygon-flagos。
- 执行下面代码,可以看到模型已经切换完成。
|
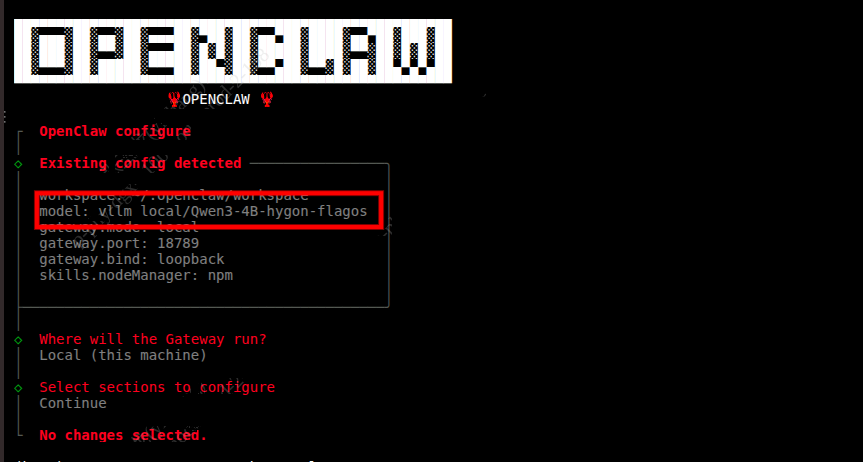
可以看到模型已经切换完成。
3、配置 channel 为QQ
参考文档: https://cloud.tencent.com/developer/article/2626045,这部分需要替换为自己的ID和secret。配置完成后,进行以下操作:
- 启动openclaw网关, 命令如下:
| Plain Text pnpm openclaw gateway |
- 启动成功后,您可以在QQ软件中尝试和已经打通OpenClaw的QQ机器人进行单独聊天,或者在群里与QQ机器人进行对话。如果QQ机器人能够以AI的方式对话,则说明您已经成功完成OpenClaw应用接入QQ机器人。
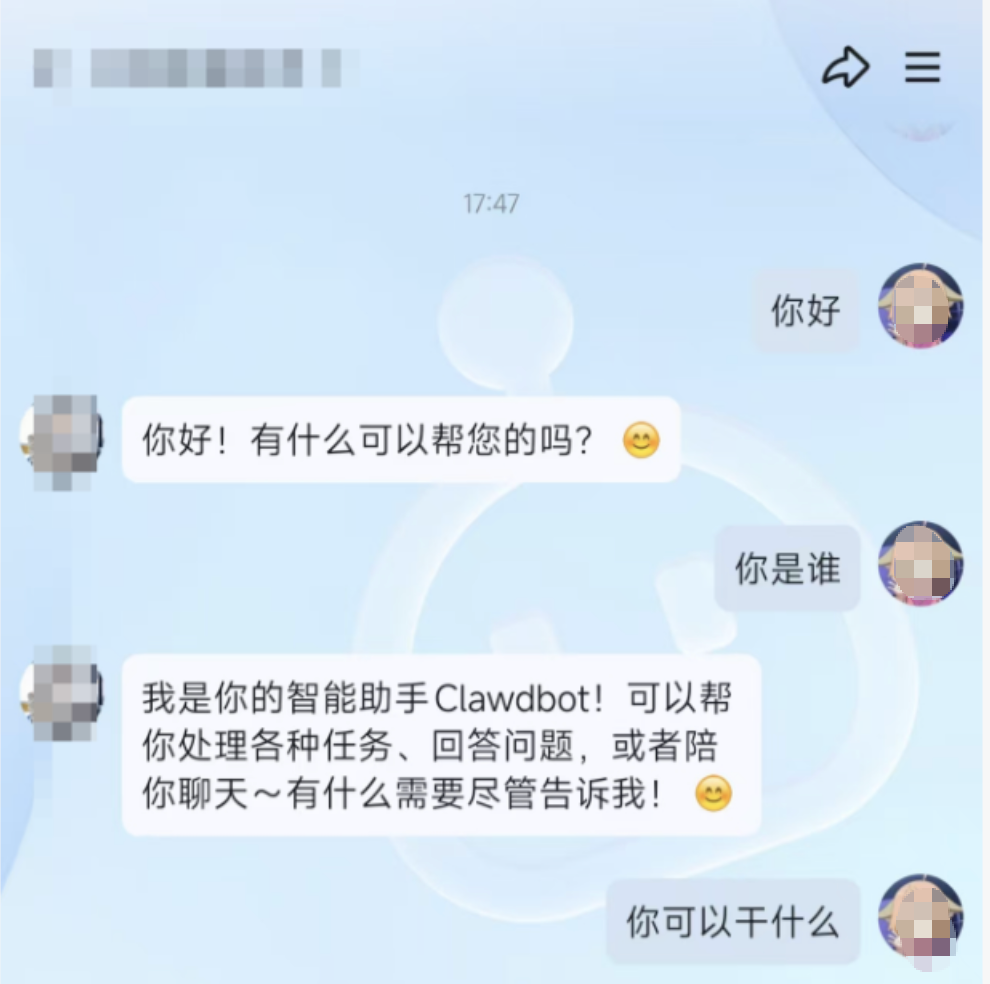

接下来您就可以开始进一步探索OpenClaw接入QQ机器人之后的更多使用场景。
趋势展望
这次在 OpenClaw 连接QQ的场景中对 Qwen3-4B-hygon-flagos 进行了测试,发现Agent 的能力边界正在发生转移。
| 关键信号:
•小模型开始进入 Agent 执行层 •真正的瓶颈不在模型,而在系统 如果你要的是一个能在本地跑、能调工具、能接企业系统的 Agent 内核, Less is More, FlagOS is the Key! |
| 关于众智 FlagOS 社区
众智FlagOS是一款专为异构AI芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。 社区官网:https://flagos.io GitHub地址:https://github.com/flagos-ai GitCode地址:https://gitcode.com/flagos-ai |
| 关于HAI
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 AI 、科学计算的 GPU 应用服务产品,提供即插即用的澎湃算力与常见环境,助力中小企业及开发者快速部署 LLM。 而HAI社区是一款面向AI和科学计算等GPU环境的容器镜像中心,提供丰富的官方与社区维护的开发资源。助力企业和开发者快速部署AIGC大模型、计算机视觉、自然语言处理、数据科学等容器,原生集成开发工具与组件。 |
