








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西2月12日报道,今日,摩尔线程发文宣布旗舰级AI训推一体全功能GPU MTT S5000率先完成对GLM-5大模型的适配,并首次曝光MTT S5000的硬件参数。
MTT S5000支持FP8到FP64的全精度计算,FP8精度下单卡AI算力最高可达1000TFLOPS,配备80GB显存,显存带宽达1.6TB/s,卡间互联带宽达784GB/s。
根据业内人士消息,MTT S5000实测性能对标H100,在多模态大模型微调任务中,部分性能甚至超越H100。

MTT S5000由摩尔线程在2024年推出,专为大模型训练、推理及高性能计算而设计。
据接近测试项目的行业人士透露,S5000在产品精度上已超越H100,更接近英伟达Blackwell架构。
在近期一次数千亿参数模型的全流程训练验证中,该卡表现出了与H100集群极高的结果一致性,最终模型关键指标误差仅维持在千分之几的范围内,整体训练效果甚至实现小幅超越。
另据来自互联网厂商场景的实测信息反馈,S5000在典型端到端推理及训练任务中,性能可达竞品H20的2.5倍左右。
摩尔线程官网也已上线MTT S5000的详情页面。
产品形态上,S5000遵循OAM标准设计,提供两种计算模组形态:
- 液冷版:专为高密度绿色数据中心打造,释放极致算力密度的同时,显著降低PUE与能耗;
- 风冷版:适配标准通用服务器,部署灵活便捷,有效降低运维门槛与长期持有成本。
同时,摩尔线程推出面向AI和高性能计算的MGX 8-GPU模块化平台:8颗MTT S5000 OAM计算模组通过MTLink高速互联,可为大模型训练、推理及科学计算等应用场景提供超大规模算力。

MCCX D800 X2服务器是搭载8颗MTT S5000 OAM计算模组的一体化AI服务器,提供计算、存储、网络的高端配置,可支撑千亿、万亿参数大模型高效运行。
该服务器在散热、供电、I/O 扩展性等方面充分优化,支持风冷和液冷两种机型,可预装优化训练、推理软件栈,实现软硬件一体化交付,开箱即用。

一、基于第四代MUSA架构,原生支持FP8精度,训练性能提升30%
在大模型参数持续扩张的趋势下,FP8计算精度的支持已成为训练与推理的核心精度标准。相比传统的BF16/FP16,FP8可将数据位宽减半,显存带宽压力降低50%,理论计算吞吐量翻倍。
MTT S5000是国内最早一批原生支持FP8精度的训练GPU,配置了硬件级FP8 Tensor Core加速单元。其FP8引擎全面支持DeepSeek、Qwen等前沿架构,在实测中可提升30%以上训练性能。
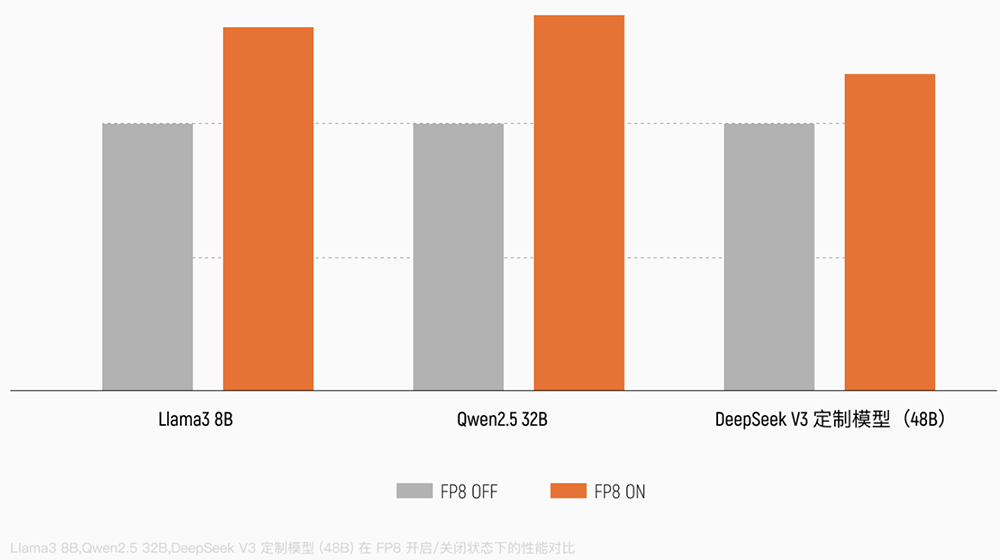
S5000采用第四代MUSA架构“平湖”,专为大规模AI训练优化,依托MUSA全栈软件平台,原生适配PyTorch、Megatron-LM、vLLM及 SGLang等主流框架,让用户能够以“零成本”完成代码迁移,兼容国际主流CUDA生态。

这款AI计算卡深度优化了Prefill阶段的处理效率,在超长序列输入场景下,能显著加速Prompt预处理过程,提供更快的上下文理解与首Token响应速度,有效解决大规模知识库检索及长文档分析中的延迟瓶颈。
在16k长序列输入测试中,S5000单卡Prefill吞吐量是H20的2.5倍。这意味着在处理长文本Prompt时,国产算力具备更快的上下文理解速度。
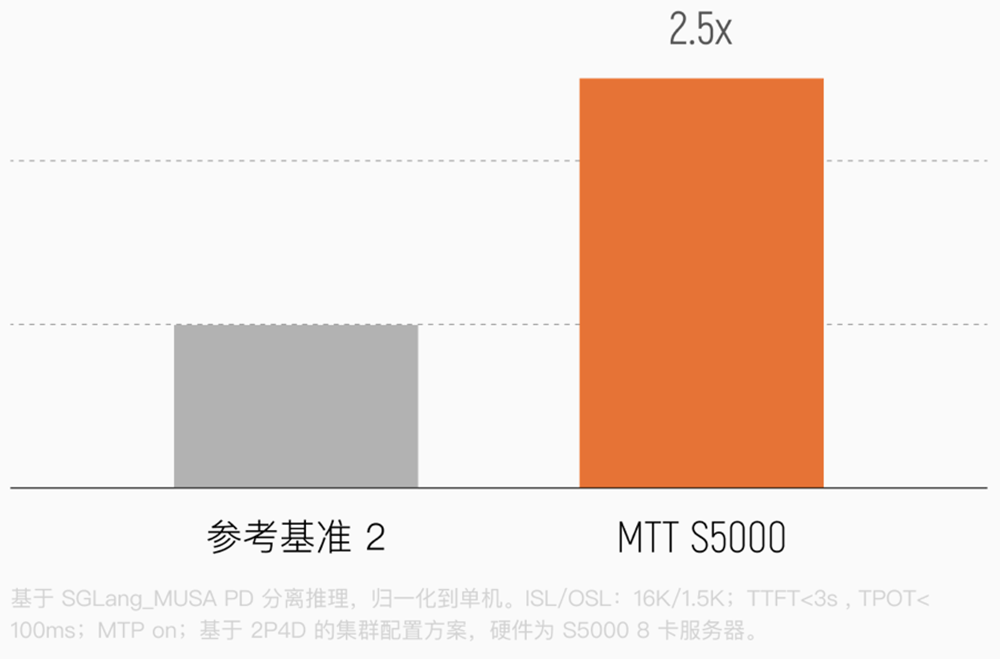
这主要得益于其高达1000TFLOPS的单卡算力。在绝大多数计算密集型场景中,该卡不仅能提供更强劲的算力输出,也在整体性价比上展现出显著优势。
基于FSDP2框架,MTT S5000已率先完成Wan2.1视频生成全模型训练验证,2节点16卡配置下训练吞吐量达61.83samples/s,模型算力利用率(MFU)达51%,生成效果在视频逻辑、画质细腻度、动态一致性上均对齐行业基准。

二、10EFLOPS万卡集群已落地,下游任务评测得分优于H100
基于S5000构建的夸娥万卡集群已经落地,其浮点运算能力达到10EFLOPS,在Dense模型训练中MFU达60%,在MoE模型中维持在40%左右,有效训练时间占比超过90%,训练线性扩展效率达95%。
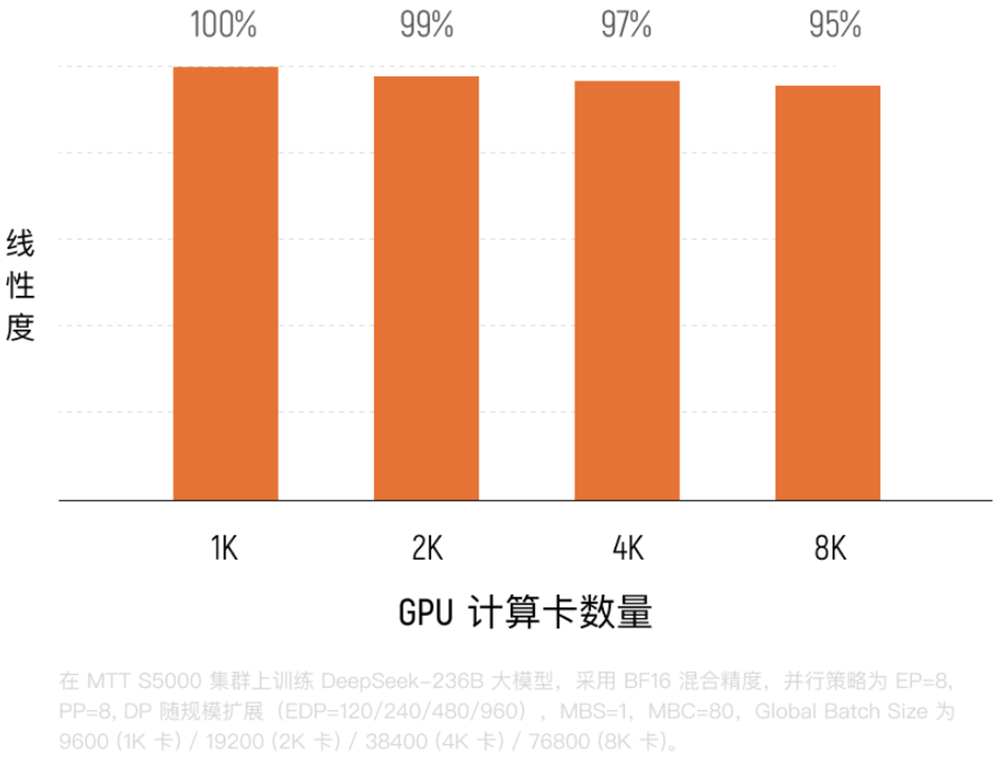
依托原生FP8能力,它能够完整复现顶尖大模型的训练流程,其中Flash Attention算力利用率超过95%,多项关键指标均达到国际主流水平。
在集群通信层面,S5000采用独创的ACE技术,将复杂通信任务从计算核心卸载,实现计算与通信的零冲突并行,大幅提升MFU。
实测显示,从64卡扩展至1024卡,其系统保持90%以上的线性扩展效率,训练速度随算力增加几乎同步倍增。
第三方验证方面,2026年1月,智源研究院基于S5000千卡集群,完成了前沿具身大脑模型RoboBrain 2.5的端到端训练与对齐验证。
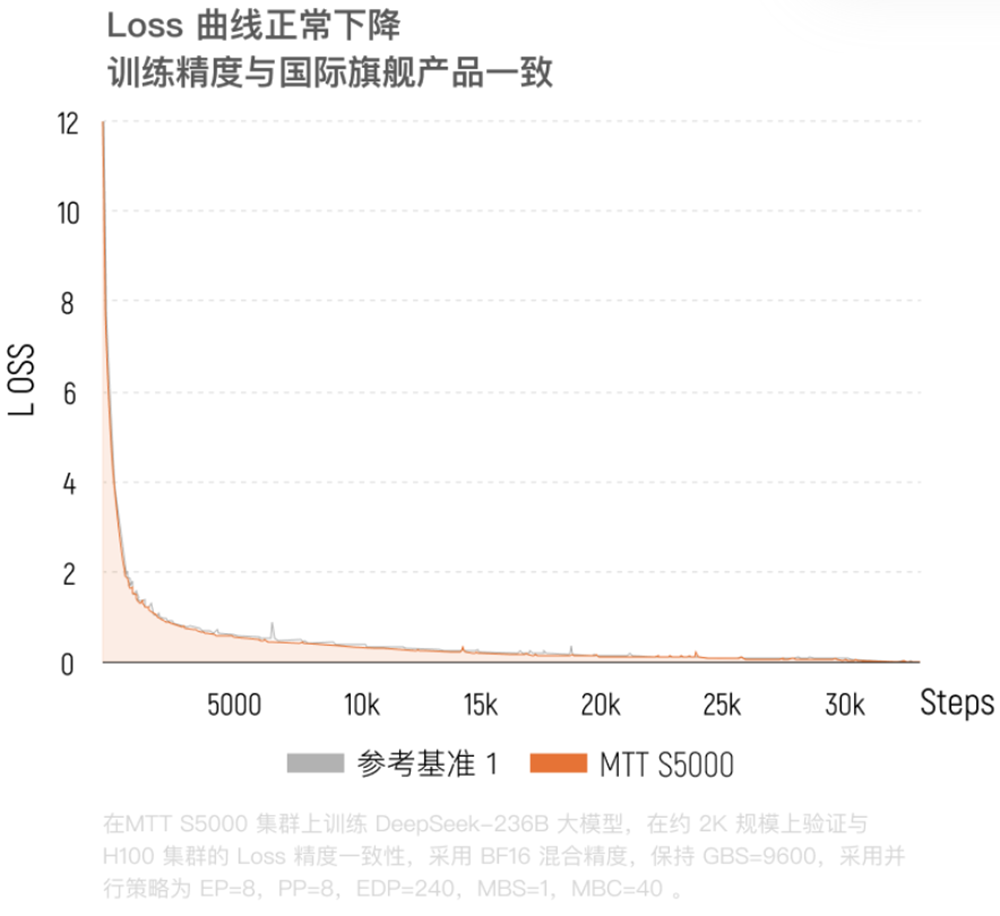
结果显示,与英伟达H100集群的训练结果高度重合,训练损失值(loss)差异仅为0.62%。
根据摩尔线程官网,在S5000集群上训练DeepSeek-236B,前3万步训练过程中,Loss曲线与H100集群的相对精度误差仅为0.6%。同等数据量下,其下游任务评测得分优于H100,验证了万卡集群的高精度。
GPU集群的可靠性、可用性和可维护性(RAS)是支撑大规模AI训练任务持续稳定运行的核心基础设施能力。
S5000从芯片级到系统级构建了完整的RAS体系,支持故障感知、上报与错误隔离,可快速定位并替换故障节点、慢节点及静默数据损坏节点,并具备主动检测与修复功能,长期守护集群健康,确保性能稳定与结果正确。
三、刷新国产GPU大模型推理纪录,科学计算性能完胜H100
S5000在推理场景同样表现优异。2025年12月,摩尔线程联合硅基流动,基于S5000完成对DeepSeek-V3 671B满血版的深度适配与性能测试,实测单卡Prefill吞吐超4000tokens/s,Decode吞吐超1000tokens/s,刷新了国产GPU的推理纪录。

针对Agent间的高频通讯与复杂代码块的瞬时生成需求,S5000在DeepSeek等前沿模型的推理实测中,实现了远超行业基准的token生成速率。
S5000针对文生视频模型进行了深度优化,基于原生FP8硬件加速能力,在大幅提升推理速度的同时,确保生成内容精度无损,单机性能达到H100的64%-79%,兼顾高性能输出与高投入产出比(ROI)。

同时,S5000凭借原生FP64双精度计算能力,通过与国家级实验室的深度合作与调优,在关键科学计算领域实现性能提升。在SPONGE模拟引擎中,其性能达到H100的1.7倍;在分子对接工具DSDP的实测中,其计算效能展现出压倒性优势,性能达到H100的8.1倍。

此外,作为一款全功能GPU,S5000集成了高性能的多媒体编解码引擎,硬件原生支持H264、H265、VP9、AV1、AVS2、AVS+、VP8等格式。

结语:国产GPU已经扛起大模型训练的重任
根据摩尔线程官网披露信息,无论是构建万卡级超大规模训练集群,还是部署高并发、低延迟的在线推理服务,MTT S5000均展现出对标国际主流旗舰产品的卓越性能与稳定性。
作为目前国内少数具备完整大模型训练能力的AI计算卡之一,MTT S5000提供了一套可行的国产算力替代方案,从FP8精度支持、单卡1000EFLOPS算力等参数到经过万卡集群实训、第三方机构验证的实战成绩,都证明了国产GPU不仅能做好推理,而且已经能支撑起大规模模型训练的计算需求。
