








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西1月29日报道,近日,国内AI芯片创企奕行智能分享技术路线及业务进展。其研发的国内业界首款RISC-V AI算力芯片Epoch正在大规模量产出货中。
该芯片在业界率先采用RISC-V + RVV(RISC-V向量扩展)指令集架构,结合自研的VISA(虚拟指令集)技术,兼顾了AI计算的通用性与专用性。
奕行智能成立于2022年1月,专注于新一代通用AI计算的芯片设计及解决方案,在2025年完成数亿元A轮融资,累计融资已超过10亿元。
该公司已推出数款AI芯片,最新一代AI计算芯片产品Epoch于2025年启动量产,目前在头部系统厂商、互联网,数据中心及行业客户均取得商业突破,斩获巨额在手商业订单,迎来规模化量产。
据奕行智能分享,Epoch系列产品及计算平台解决方案2025年开始推向市场,反馈火爆。公司现金流健康,不断持续融资,具备很强的造血能力,较早实现规模可观的销售收入,且从2023年以来每年销售收入都以平均200%左右的速度在增长,公司资本化也在积极规划中。
一、创业受特斯拉BEV算法启发,研发类TPU架构RISC-V AI算力芯片
奕行智能管理团队创业念头的萌芽,始于2021年特斯拉AI Day上发布的BEV算法。BEV算法的底层架构就是Transformer,也就是如今红遍大江南北的大语言模型的基石。
创业后,奕行智能团队在战略上定位,一定要有自己的AI计算架构作为公司的技术灵魂,所以投入了大量的团队资源和研发力量,围绕Transformer的计算特点,构建了一套包括AI计算架构、AI编译器以及相应的软件工具链的核心技术栈。
在先后开发了两代车载AI芯片并规模化量产的同时,顺应大模型应用场景爆发式增长的趋势,奕行智能团队结合自研的AI计算架构,定义并开发了Epoch AI计算芯片。
Epoch采用了业界首款RISC-V +VISA双融合通用AI计算架构。
该架构与TPU具备较强的相似性,例如同样采用RISC-V内核,并内置了性能强大的双脉动流水矩阵运算引擎及具备复杂矩阵数据处理与变换的4D DMA引擎。
根据奕行智能分享,DeepSeek等大模型厂商对下一代AI计算芯片的很多硬件性能要求,在其芯片中都有前沿布局,例如对分块量化FP8计算的支持、对FP8累加精度达到34比特以上的精度要求的支持、在芯片中设计专门加速通信流的硬件专用单元、把硬件的纵向扩展和横向扩展统一成一套网络体系等。
除了支持传统的多种浮点及整型数据类型以外,其AI芯片还支持DeepSeek所需的基于分块量化的FP8计算精度,并支持NVFP4、MXFP4、MXFP8、MXINT8等前沿的数据格式,可高效释放算力,大幅降低存储开销。
据其披露的实测产品性能,Epoch产品能和国际竞品相比均有优势。在运行ResNet-50、BERT-Base、GPT-J、Llama 2等模型时,Epoch性能比竞品高出25%~52%。
在FlashAttention-3等关键大模型融合算子,其算力利用率较竞品具有明显优势。
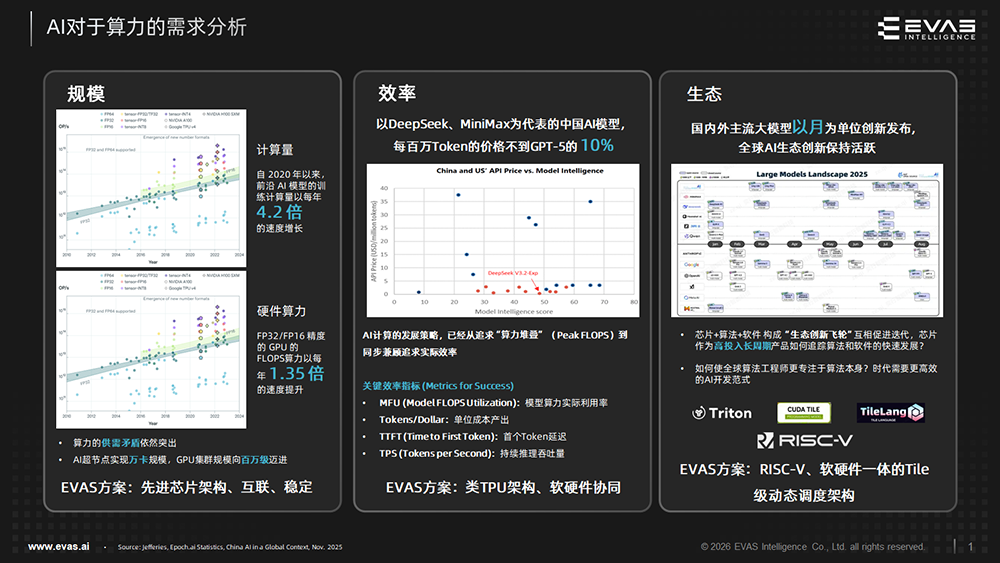
针对AI对算力的需求,奕行智能的方案有三大亮点:
- 规模化:采用先进芯片架构,实现更高算力密度,并通过ELink互联技术支持大规模扩展;
- 效率提升:采用类TPU架构,兼顾高性能与高效率,并通过深度软硬协同,提升算力使用效率;
- 生态创新:采用RISC-V + RVV开源指令集,赋予硬件灵活扩展能力,并基于软硬件一体的Tile级动态调度架构,通过Tile语义的虚拟指令集提供更友好的编程界面。
在多芯互联方面,奕行智能拥有自研的互联技术方案ELink,可支持大规模互联扩展。
ELink能与集成RoCEv2、SUE、EthLink、C-Link协议的交换设备和芯片进行无缝高效互联,支持800G/400G/200G可配置以太网标准协议,支持Scale up超大带宽与超低延迟传输需求,支持全带宽互联等多种互联拓扑,兼容内存语义与DMA语义,并能配合交换侧支持业界最前沿的在网计算功能。
二、“CUDA兼容”并非唯一答案,专用领域计算+Tile路线快速发展
现有AI计算芯片中,英伟达的GPGPU凭借SIMT架构具备强大并行计算能力,依赖强大的CUDA生态,使得GPU成为当前业界占比最高的算力硬件形态。
产业界有不少采用类GPGPU架构的厂家,希望通过CUDA兼容的方式,获得GPGPU的一部分市场份额。
但因为CUDA是英伟达深度软硬件协同的产物,就好比CUDA是把针对英伟达硬件的“钥匙”,只有用在英伟达的GPGPU上才能发挥其强大性能,所以CUDA兼容往往只能做到API层面的兼容,看上去很美,实际上却存在普遍性的水土不服。
同时因为英伟达的硬件不断往前演进,CUDA兼容可能会出现落后N卡许多年的尴尬之处。

另一方面,以谷歌TPU为代表的ASIC芯片采用SIMD架构,内置针对矩阵运算等AI范式的专用加速单元,在性能与能效上具有比GPGPU更大的优势,但其过去的挑战主要在于生态适配成本。
相较于已发展近20年的CUDA生态,如何吸引开发者在专用硬件上进行高效编程,成为多数ASIC厂商面临的共同问题。
而包括谷歌在内的头部ASIC厂商通过长期投入,已在生态适配方面取得显著突破。
以TPU为例,其通过XLA编译技术,不仅支持谷歌系的TensorFlow和JAX框架,也能适配主流开源框架PyTorch(该框架在全球机器学习开发应用中占比超过80%),从而有效降低了生态迁移门槛。

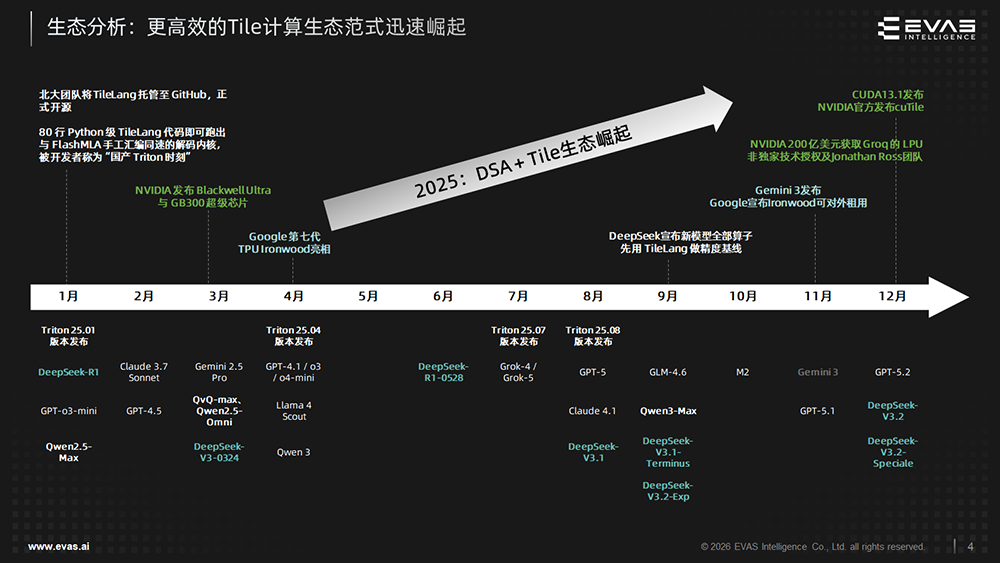
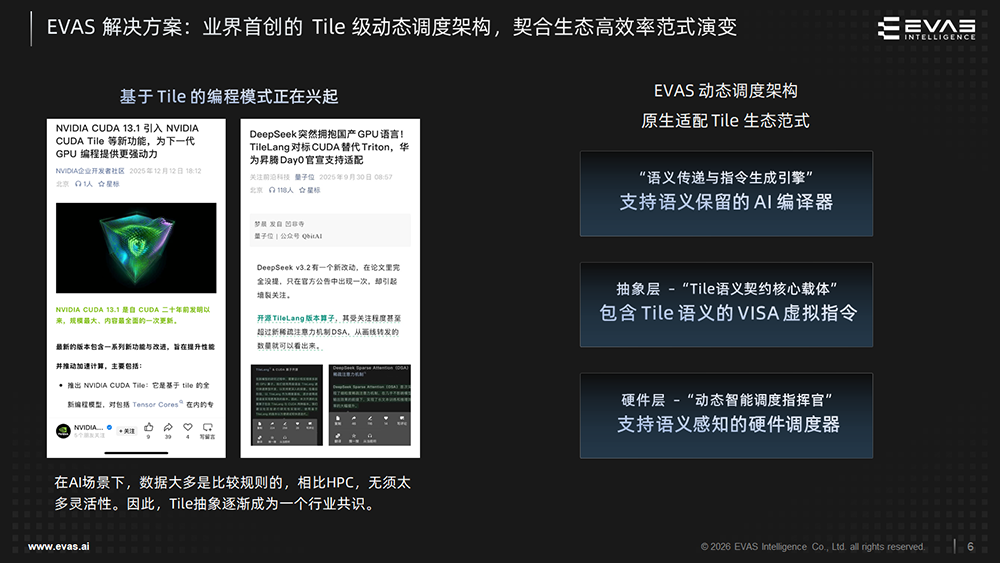
另一条提升编程友好性和开发效率的路径,在于近年来兴起的Tile(数据分块)计算范式。AI计算中的数据往往具有规整性,基于Tile的编程模式更贴合这类计算特征,能够提供更友好的编程接口,提升算子开发效率。
例如,DeepSeek已采用北大团队开源的TileLang构建算子,并在新模型中以其作为精度基准;甚至英伟达也在CUDA 13.1中推出了基于Tile编程范式的编程界面CUDA Tile。
在TPU以极致能耗比抢占市场的同时,专用领域架构(DSA)设计思想也体现在GPU的迭代中。
英伟达在GPGPU中持续提升DSA的比例,从Volta架构首次引入Tensor Core,到Blackwell架构进一步扩大张量核心规模并加入针对Transformer的优化引擎,体现出向领域定制化演进的趋势。2025年12月,英伟达吸纳AI推理芯片创企Groq的核心团队,进一步加强在大模型推理定制化方面的布局。
国外巨头积极布局,体现出DSA(ASIC)+Tile编程范式的兴起会成为未来在算力领域的一种重要生态和力量,软硬协同带来的效率优势在AGI时代具有广阔市场空间。
DSA与Tile编程范式的结合,也正是奕行智能产品的重要特点和重点布局卡位的技术方向。
三、3项核心技术创新:充分挖掘硬件算力,简化软件复杂度
奕行智能的解决方案采用业界首款RISC-V + VISA双融合类TPU通用AI计算架构EVAMIND,兼顾高性能与高效率,实现算力密度与吞吐率双重提升,原生支持卷积指令,契合深度学习演进趋势。
区别于传统的GPGPU和NPU架构,其解决方案拥有3项核心技术创新:
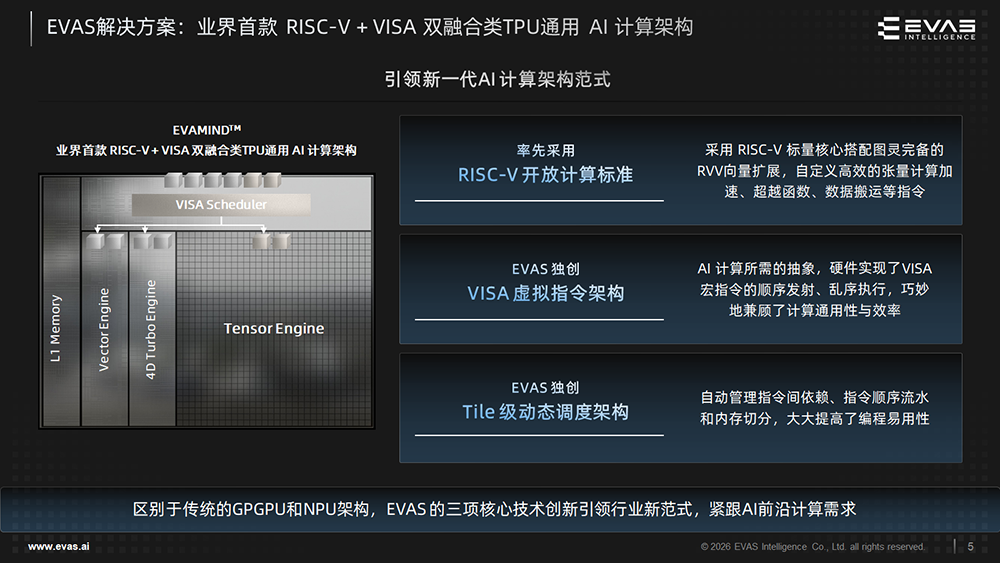
1、RISC-V开放计算标准
奕行智能率先采用RISC-V+RVV(RISC-V向量扩展)构建AI芯片架构。
RISC-V指令集图灵完备,保障了通用计算能力,同时其模块化设计允许厂商自由扩展专用AI计算指令,自定义高效的张量计算加速、超越函数、数据搬运等指令。
RVV原生支持复杂向量计算,支持多种数据类型的混合精度计算。
RISC-V有全球生态基础,支持RVV 1.0全球标准。谷歌从TPUv5开始采用RISC-V指令集,高通、Meta均收购高性能RISC-V芯片企业,反映出发展RISC-V已成为科技巨头的共识。
奕行智能团队认为,RISC-V是当前最适合构建AI处理器的指令集架构。其特点包括:
- 开放的图灵完备指令:天然支持复杂控制流,可避免NPU的灵活性短板;
- RVV向量优势:天然契合AI张量计算,掩码操作原生支持稀疏矩阵;
- 成熟生态借力:GCC/LLVM主流编译器已完全支持,主流AI框架正在积极适配;
- 定制化潜力:允许在标准之上扩展专用指令,完美平衡通用性与专用性。
Epoch芯片中的EVAMIND AI内核集成多组RISC-V高性能核:
- RISC-V标量计算引擎负责核内计算和控制,支持双发射核内的VISA指令发射及调度运行;
- RISC-V向量加速引擎中,图灵完备的高性能RVV向量加速RV核,超宽的D-length及I-Length利用RVV扩展技术对AI常用的超越函数硬件指令化,大幅提升AI计算性能。
在SoC顶层,其芯片集成多组片上RISC-V高性能核,拥有芯片级的调度和控制,以及专用的通信流加速CPU Cluster。
2、VISA虚拟指令架构
奕行智能独创的虚拟指令(VISA)技术在软件与硬件之间建立中间抽象层,让上层的算子及AI编译器软件建立在VISA之上,硬件实现了VISA宏指令的顺序发射、乱序执行,从而隔离硬件变化对上层软件的冲击,有效解决软件兼容与适配性挑战,巧妙地兼顾了计算通用性与效率,满足了AI计算所需的抽象。
同时,VISA抽象也降低了AI编译器与算子的实现难度,提供额外的性能优化空间。
该架构可解决三大行业痼疾:
(1)隔离硬件迭代差异:不同代际芯片存在指令增减、计算单元大小变化、缓存层次及容量变化,为软件兼容与适配性带来挑战。VISA作为中间抽象层可以让上层算子及编译器建立在此抽象上,隔离硬件变化对上层软件带来的冲击。
(2)计算的扩展能力:软件算法持续更新迭代,对架构计算的可扩展能力是很大的挑战。EVAS架构在硬件层面通过RVV的向量定制指令提供硬件扩展能力,同时VSA将细粒度指令封装并优化成性能高的微内核,提供了软件层面的向量计算扩展能力,这样一套软硬结合的方式解决了通用与效率的兼顾。
(3)解决AI编译的陡降问题:在AI计算中,将高级的Tensor操作直接编译到底层SIMD指令时,由于两者抽象层级差距巨大,会导致严重的编译困难,性能损失。VISA通过使用软流水、循环展开方式进行极致优化,编译器及算子实现只需关注到这个层级,简化了实现难度。
3、Tile级动态调度架构
在AI场景下,数据大多是比较规则的,无需太多灵活性。因此,基于Tile的编程模式逐渐兴起。
奕行智能独创的Tile级动态调度架构由Tile级虚拟指令集、智能编译器和硬件调度器组成,原生适配Tile生态范式,能够实时适配硬件行为,充分挖掘并行潜力,突破静态优化的天花板,编程也更为干净简洁。
该架构的自动管理指令间依赖、指令顺序流水和内存切分,大大提高了编程易用性。
结语:软件平台兼容主流AI框架,正与Triton社区推进重要RISC-V合作
从技术路线来看,奕行智能与现有主流AI芯片的设计思路,既有与专用AI芯片架构的共通之处,又不乏差异点。
最显著的差异当属采用RISC-V指令集架构来设计AI芯片,并基于前文所述的3项核心技术创新以及软件工具链,来探索一种追求极致TCO的新型高性能AI加速方案。
奕行智能正在持续完善软件栈及生态。
其软件开发平台采用了自研基础软件栈ETK+业界开源AI框架的方式提供的开放兼容解决方案,全面兼容主流AI框架,提供丰富的深度优化高性能算子,并通过独创的Tile级动态调度架构,突破传统静态调度模式的性能瓶颈,提高编程易用性。
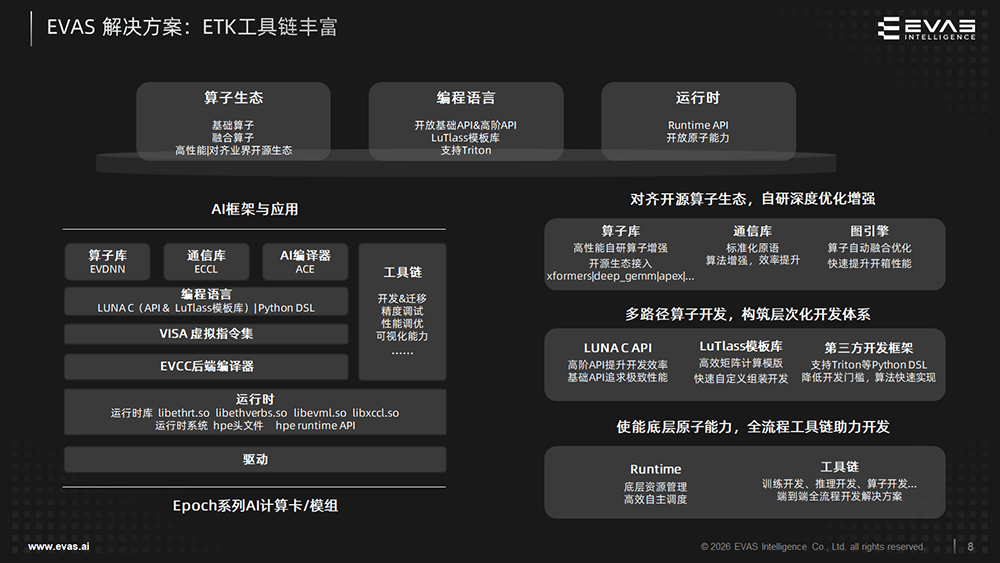
生态方面,奕行智能正在积极与全球开源社区互动,也在与Triton国际社区构建一个重量级合作,把Triton编译导流到RISC-V DSA后端,并将开源其虚拟指令集,合力打造针对RISC-V DSA的CUDA生态,这对于RISC-V DSA整个产业的发展具有重要的战略意义。
以TPU为代表的专用领域AI计算架构,以突出的能效比取得了市场成功。奕行智能的Epoch芯片,基于类TPU芯片架构,在国内AI芯片的激烈竞争中,有望在这个领域中实现突破。
