








机器人前瞻(公众号:robot_pro)
作者 | 江宇
编辑 | 漠影
机器人前瞻12月19日报道,今年4月,北京人形机器人创新中心(以下简称“北京人形”)的“具身天工Ultra”机器人凭借自主完赛,拿下了全球首个人形机器人半程马拉松冠军,成为“最能跑”的人形机器人。而在不久后的8月,具身天工Ultra和天轶2.0再次凭借全自主的方式斩获2金6银2铜,证明了机器人不仅能跑,还能“干活”。
可以看出,北京人形真正聚焦的目标,一直在于让机器人在现实场景里做到“能干活、会干活”。
在北京人形机器人创新中心,具身天工机器人已经以全自主、无遥操的方式上岗执行导览任务,并依靠北京人形打造的“慧思开物”平台实现了导览过程中的多机协同和全局调度,整个过程无需人工干预。

如今,围绕让机器人“能干活、会干活”这一目标,更底层的模型与数据训练能力也正式对外开源。12月18日,北京人形宣布XR-1具身VLA模型,以及配套的数据基础RoboMIND 2.0、ArtVIP最新版正式开源,XR-1 模型是目前首个且唯一一个通过具身智能国标多维度测试的VLA模型。
开源XR-1的背后,北京人形正在努力解答一个核心问题:为什么机器人看得懂却做不好?
为此,机器人前瞻采访了XR-1跨本体VLA模型研发负责人伍堃,从模型设计、训练体系到真实落地三个层面,复原XR-1走出实验室、走向实干的路径。
一、从“看得见”到“做得对”,XR-1补上机器人最难的一课
当AI能写诗、能生成视频,机器人却连“拿稳一杯水”都难?核心问题在于视觉感知与动作执行的割裂。
很多传统机器人更像“死记硬背的学徒”,很难将高维度的图像输入映射到低纬度的机器人控制信号,只要物体位置变了、角度变了、环境多了干扰,就容易抓不稳、捏碎、甚至直接失败。
为修复这道断层,北京人形团队独创并研发了Unified Vision-Motion Codes(UVMC)多模态视动统一表征。
它可以被理解成机器人的“拼音系统”:先把视觉信息与动作经验压缩成可复用的“动作代码”,通过模型,从看到的画面中获得一个初步的动作趋势信号,类似于条件反射,再进一步生成更加精确的底层机器人控制信号,使得机器人做到知行合一。
这样即便遇到没见过的场景,机器人也能够以更接近“条件反射”地给出合理动作。比如当机器人看到杯子倾倒,它会自动生成对应的“动作代码”,再进一步预测关节角度与3D坐标,完成扶正动作。
UVMC之外,XR-1的“实干能力”由三项特性顺势撑起来。
第一是跨数据源学习:面对真机数据采集成本高、量级有限的问题,XR-1不仅学习机器人数据,还能读懂互联网上海量的人类第一视角视频,让学习素材呈指数级增长。
第二是跨模态对齐:借助“拼音系统”(UVMC)将视觉信息与动作关节配对,让模型建立“画面—动作”的对应关系,把“知”更稳定地转成“行”。
第三是跨本体控制:通过可变维度输入与去本体化抽象表征提升迁移能力,使同一个“大脑”能适配不同构型机器人。
目前,XR-1已在至少6种完全不同的机器人上完成测试并实现适配。

此外,为了把这套能力练成可迁移的“基本功”,XR-1还采用三段式训练范式。
先做视动统一表征训练,融合机器人数据与互联网视频,形成可调用的“动作字典”,再进行跨本体数据强化训练,强化对通用物理规律与动作模式的掌握。最后,针对具体场景做少量微调,把通用能力运用到真实的任务场景中。
性能对比上,XR-1相较国际先进VLA模型在多类复杂任务中成功率领先,部分高难度任务可达到其他头部模型两倍水平。
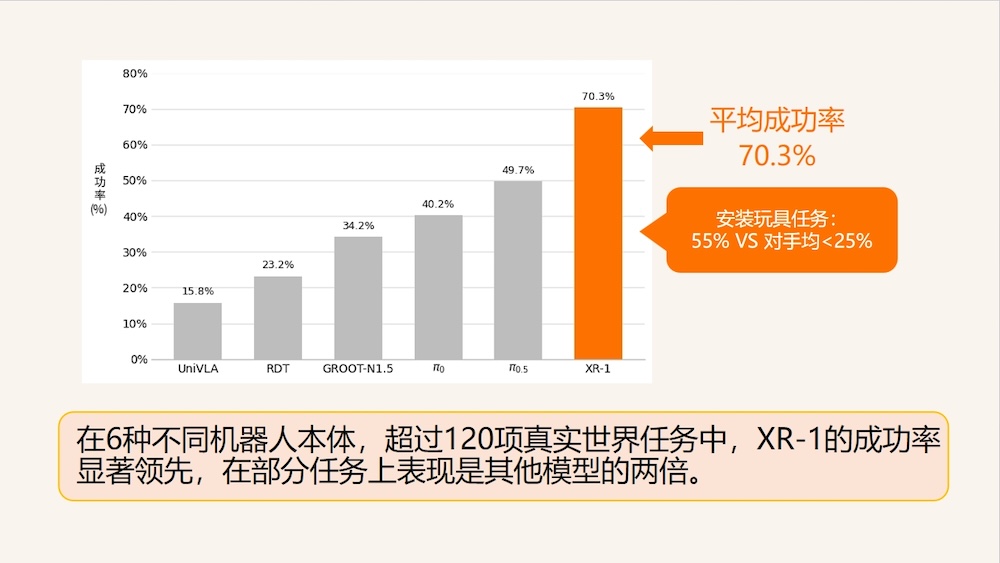
这套从感知到动作的模型路径,使机器人在面对环境变化时不再频繁“失手”,而是能够维持任务连续性,为真实场景中的长期运行创造条件。
二、实战加上仿真,把机器人“训练营”搭起来
让机器人“干好活”不只靠模型,更离不开大量高质量、可控的数据。在这套开源组合里,XR-1负责“学会怎么做”,RoboMIND 2.0是XR-1的重要数据来源,提供海量真实机器人操作数据与仿真模拟数据。ArtVIP则是北京人形开源的仿真资产库,为RoboMIND补齐高质量仿真数据与可交互环境,把“虚拟特训”和“真实实战”接到一起。
具体到RoboMIND 2.0本身,相比1.0版本,它在数据规模和类型上都做了扩展。
多本体双臂操作轨迹从10+万条升级到30+万条,覆盖具身天工等6种机器人本体,多场景多任务从5大场景、479个任务、38种技能,扩展到10+场景、739项任务、129种技能。

▲RoboMIND数据集包含的部分任务样例
最关键的是,RoboMIND2.0新增了1.2万条带触觉的真机操作数据,这部分触觉数据的引入可让模型成功率平均提升约30%。
而ArtVIP也并非“泛泛的仿真素材包”,而是面向复杂铰接物体的高精度虚拟资产库,覆盖26类共206种高精度可动物件(如橱柜、烤箱、折叠椅、抽屉、电风扇、剪刀等),在还原视觉外观的同时,以高保真方式复现物理特性。

北京人形也一并开源了6个支持全场景交互的虚拟机器人训练场(包含中式客厅、厨房、卧室、起居室等常见环境),让模型能在遵循物理法则的“数字孪生演练场”里反复练习复杂物体的灵巧操作,从而显著降低真机采集与试错成本。

RoboMIND 2.0和ArtVIP在一定程度上缓解了具身智能在训练中高质量数据稀缺的问题:一边用真实轨迹提供动作边界与细节,一边用高保真虚拟资产扩展覆盖面,让XR-1的训练不再被“少量昂贵样本”锁死,而是更接近可规模化、可组合的数据供给。
三、从实验室走向应用现场,XR-1的“实干表现”开始显露
技术的价值终要靠应用检验,XR-1及其配套体系已在多个真实场景中完成“实干”试炼。
在北京昌平的福田康明斯工厂,具身天工机器人和天轶机器人被应用到物料搬运线上。轮式底盘的天轶机器人滑行到物料箱前后,机械臂能够稳定扣住箱体两侧,再把箱子放入指定层架,整套动作连贯顺畅。

▲天轶机器人正在搬运物料箱
双足底盘的具身天工则更考验稳定性,把箱子往高处放置时重心会变化,机器人也同时兼顾下肢电机扭矩与机械臂关节的灵活控制。

▲具身天工机器人正在搬运物料箱
面向更高风险、精细化要求更强的场景,北京人形也把具身能力推进到电力巡检与检修环节,通过与中国电科院的合作,北京人形以机器人代替人类进行高危电力巡检工作。
在李宁运动科学实验室,具身天工机器人也能穿上李宁跑鞋与运动服饰完成奔跑,进行长时间高强度的运动装备测试,并实时反馈装备数据信息。

▲具身天工机器人穿上跑鞋与运动服饰正在进行奔跑测试
开源后,这些经过实战验证的技术方案将对外开放,助力企业、科研机构、高校快速适配国标要求,避免重复造轮子,加速全行业机器人实用化进程。
从这些落地的应用案例可以看到,XR-1所具备的可迁移、可复用的能力,已经为机器人行业的规模化部署提供了可行性样本演示。
结语:开源给行业搭桥,让机器人能干活、更好用
当具身智能进入更复杂、更多样的真实场景,机器人能否在真实环境中把活持续干下来,并在可接受的成本下反复复用,成为新的衡量维度。
开源方案降低了起点门槛,也缩短了试错路径。对于正处在走向规模化前夜的具身智能行业而言,北京人形这类围绕具身智能全栈技术的开源方式,能让更多人更快把机器人用起来,也让“能干活、会干活”的机器人更快来到所有人身边。
