








AI应用风向标(公众号:ZhidxcomAI)
作者|王欣逸
编辑|程茜
智东西11月21日消息,今天,腾讯混元大模型团队发布并开源轻量级视频生成模型HunyuanVideo 1.5。该模型基于Diffusion Transformer(DiT)架构,参数仅为8.3B,支持生成5-10秒的高清视频。

混元团队将HunyuanVideo 1.5定位为“开源小钢炮”,该模型在生成720p视频时的峰值显存需求仅为13.6GB,这意味着该模型甚至可在14G显存的消费级显卡上流畅运行。
目前,腾讯元宝最新版已上线该模型能力。用户可以直接输入文字描述,直接实现“文生视频”,或者上传图片配合文字指令,将静态图片转化为动态视频。
HunyuanVideo 1.5模型支持中英文指令输入,能维持图生视频的高度一致性,具备强指令理解与遵循能力,还可以在视频中生成中英文文字。在画质方面,该模型可以原生生成5-10秒时长的480p和720p高清视频,并可通过超分模型提升至1080p电影级画质。
官方给出了一段该模型生成的视频,从画面中来看,该模型对空间的把握很准确,动效非常稳定,生成的物品并未出现混乱,可玩性很强。

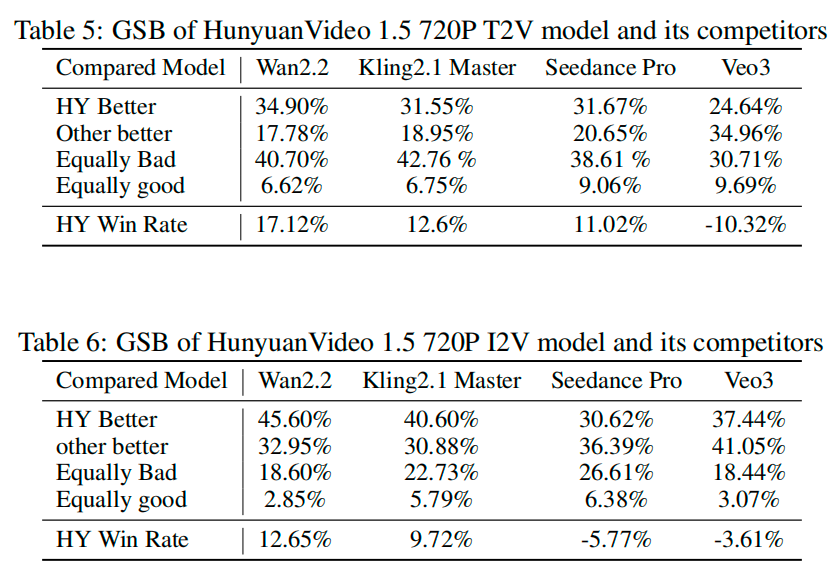
研究人员对HunyuanVideo 1.5进行了基准测试,结果显示,在和开源模型Wan 2.2、可灵2.1 Master的对比中,HunyuanVideo 1.5在结构稳定性、指令理解等多项指标处于领先地位,而与顶尖闭源模型Veo 3、Seedance Pro相比,HunyuanVideo 1.5的视觉质量以微小优势胜出。
智东西体验了HunyuanVideo 1.5模型,发现该模型在视频运镜、画质和光影上都表现不错,中英文文字生成不乱码,并且能很好表现人类情绪;在场景精细度上,该模型还有待提升。
技术报告:
https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5/blob/main/assets/HunyuanVideo_1_5.pdf
Hugging Face开源地址:
https://huggingface.co/tencent/HunyuanVideo-1.5
体验地址:
https://hunyuan.tencent.com/video/zh?tabIndex=0
一、视频生成仅需2-3分钟,运镜光影很能打,场景细节有待提升
智东西分别体验了文生视频和图生视频能力,在视频分辨率上选择了1080P(720P超分)分辨率。
智东西输入了一段文字指令,让其生成一段含场景、运镜、人物情绪的视频,以衡量其复杂指令理解与遵循能力,实测结果中,不到3分钟该模型便生成一个5s的视频,在运镜上,该模型表现不错,对空间感知能力较强,视频比较流畅,人物情绪表达到位。

提示词:在一个繁忙的城市广场上,镜头从远处的高角度俯瞰,捕捉到四周行人匆忙的步伐。镜头逐渐缓慢推进,穿过人群,最终聚焦在一个独自坐在长椅上的年轻女性身上。随着她抬起头,镜头平稳地从低角度摇摄,逐渐捕捉到她的表情变化。最后,镜头慢慢拉远,呈现出她孤独的身影与周围热闹的街道形成鲜明对比。
下面是不同风格视频的请求,智东西先用文本指令让其生成了一个宫崎骏动漫风格的视频。同样,该模型两分半钟就给出了生成的动画。在画风和内容上,生成的视频效果非常符合指令,在光影、动效的细节上也表现不错。

接着,智东西还进行了画质上的尝试,让其生成一个逼真现实的森林场景,从生成结果来看,视频中的叶子叶脉清晰可见,景深和焦点变换近乎摄像机效果。

在图生视频上,智东西上传了一张小猫的图片,并让小猫跑进一个小巷子,视频生成用时两分钟。就生成结果看,除了高处店铺招牌略显“敷衍”外,其他场景非常还原现实,生成的场景也与原图背景一致。

随后,智东西让其按照这只小猫生成一个骑自行车的趣味视频,该模型花了2分钟生成如下效果。可以看出,视频中的背景细节处理较差,画面逻辑和精细度有待提升,在没有更细节的提示词的情况下,墙上的灯牌和路边的小摊糊成一团。

在中英文字生成上,智东西还对其进行了测试,生成了水墨风和剪纸风两种效果的字体,中英文均表现良好。


二、吊打开源赶超闭源,推理速度快1.87倍,消费级GPU就能跑
研究人员对HunyuanVideo 1.5进行了基准评估,该模型在结构稳定性、指令理解等多项指标上达到了开源模型的领先水平,在视觉质量等维度上展现出和顶尖闭源模型竞争的实力。
在文生视频上,HunyuanVideo 1.5的结构稳定性获得了79.75分,大幅领先所有对比模型;HunyuanVideo 1.5的指令跟随指标得分61.57,明显优于Wan 2.2、可灵 2.1 Master等模型。这表明,HunyuanVideo 1.5生成的视频画面更稳定,其对提示词的理解和遵循能力也表现较好。

在图生视频上,HunyuanVideo 1.5的视觉质量与顶尖闭源模型Veo 3、Seedance Pro分数相近,并以微小优势胜出。

在GSB(Good/Same/Bad 人工评估指标,关键指标为胜率)人工对比结果中,HunyuanVideo 1.5与开源模型的直接对比全部为正,意味着HunyuanVideo 1.5在直接对比中更受评估者的偏爱。在T2V(文生视频)的表现上,HunyuanVideo 1.5已经超越了闭源模型Seedance Pro;在I2V(图生视频)上,HunyuanVideo 1.5与Seedance Pro和Veo3差距不大。
此外,在推理效率上,SSTA实现了模型的推理加速。启用SSTA后,该模型在最具挑战性的720p 241帧场景下,完成每次任务的时间从 5.50秒降至2.94秒,加速了约1.87倍,完成50次任务的总时间从96.78秒降至58.39秒。

而关于GPU内存的需求,HunyuanVideo 1.5在生成720p视频时,峰值显存需求仅为13.6GB,这意味着用户仅需一张像RTX 4090这样的消费级显卡即可进行本地部署。
三、采用8.3B DiT架构,提出SSTA机制,兼顾高性能和高效
目前,视频生成领域还存在几个关键挑战:顶尖模型多为闭源,限制了开发者社区的研究与创新;高性能模型(如Wan 2.2的MoE架构)参数庞大,难以在消费级硬件上运行;现有的模型在生成长视频的运动稳定性、细节和整体美学质量上存在不足;在复杂指令理解上质量不高;此外,Transformer框架在处理长视频序列时,推理速度慢,资源消耗大。
为此,腾讯混元团队推出了HunyuanVideo 1.5,核心目标是填补开源社区在高性能与高效率视频生成模型之间的空白。
在基础模型设计上,研究人员提出了用于高保真视频合成的两阶段框架:第一步,采用了一个具有83亿参数的扩散变换器模型,专为多任务学习设计;第二步,利用视频超分辨率网络进一步提升视觉质量。
其核心技术包括以下几个方面:
首先,HunyuanVideo 1.5采用了轻量化高性能的架构,通过8.3B参数的DiT架构与3D因果VAE编解码器,实现空间16倍、时间4倍的高效压缩。

第二,为了突破长视频生成瓶颈,研究人员提出了SSTA(Selective and Sliding Tile Attention,选择性滑动分块注意力)机制,通过动态剪枝冗余时空数据块,降低视频长序列生成的计算开销,实现推理加速。
第三,研究人员还采用了双通道文本编码器:用视觉语言模型Qwen2.5-VL深度理解复杂的场景描述和动作要求,实现精准的双语语义理解;用字形编码器Glyph-ByT5对文本OCR进行独立编码,强化模型在视频中生成准确文本的能力。
此外,在端到端的训练上,研究人员采用了多阶段渐进式训练策略,覆盖预训练至后训练全流程,分为两个阶段:第一阶段是渐进式预训练,从文本到图像的基础训练,再引入视频混合训练;第二阶段是精细化的后训练,结合Moun优化器加速模型收敛,全面优化运动连贯性、美学质量及人类偏好对齐。研究人员还为第二阶段训练提供了画质增强板块,提供高效少步数视频超分网络,将生成结果上采样至1080p,在增强画面锐度的同时有效修复画面畸变,实现细节增强与质感提升。

最后,在推理上,研究人员还集成了模型蒸馏、Cache优化等关键技术,提升了推理效率,降低推理资源消耗。
结语:加速AI视频生成普惠化
在基准测试和实际测试中,HunyuanVideo 1.5都表现出了媲美闭源模型的能力,开源、轻量化、高性能,或成为开发者优先选择的关键选项。
腾讯的大模型以混元为中心,推出了语言模型、语音模型、视觉理解和视觉生成矩阵,并开源了数十个包括语言和生图、视频、3D在内的大模型。HunyuanVideo 1.5的发布并开源,是腾讯在多模态战略的又一落子。
