








芯东西(公众号:aichip001)
编译 | 王傲翔
编辑 | 程茜
芯东西4月4日消息,近日,美国半导体初创公司Cerebras举办了Cerebras AI Day,发布了AI超级计算机Cerebras CS3和最新一代AI芯片WSE-3。Cerebras CTO Sean Lie在会上展示了WSE-3芯片的框架结构以及创新设计,并介绍基于WSE-3芯片设计的CS3系统在运行大模型上的提升和使用体验。
WSE-3 AI芯片采用台积电5nm制程,集成了超过4万亿个晶体管与90万个核心,峰值性能达到125 PetaFLOPS。在WSE-3的加持下,CS3系统在AI性能上相较CS2提升了两倍,且功耗保持不变。Sean Lie称,用户可以利用CS3集群训练任何规模的大模型,并能获得在单一CS3计算机上训练大模型的体验。
一、CS3系统与WSE-3芯片发布,AI性能进一步提升
大家好,我是Sean Lie。我非常高兴能够带大家深入了解AI超级计算机CS3的硬件架构,即Cerebras CS3系统,这是我们的第三代晶圆级系统。Cerebras CS3是AI计算领域的一次飞跃,因为它的性能相比上一代CS2高出两倍,功耗和价格却维持不变。
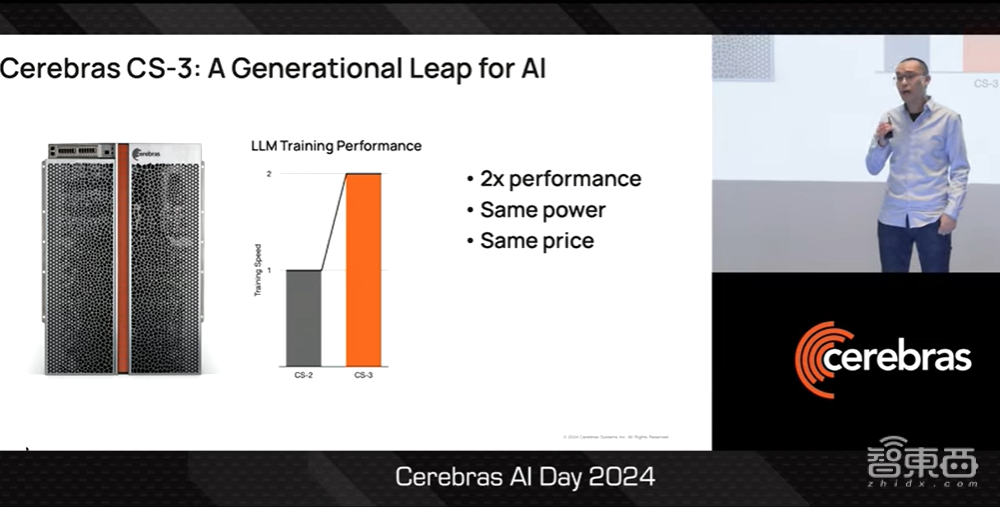
▲Sean Lie介绍CS3(图源:Cerebras AI Day 2024)
让我来向大家展示我们是如何做到这一点的。
首先是AI芯片的基础,即计算内核。我们在久经考验的上一代WSE-2基础上构建WSE-3芯片的计算内核,该内核具有48KB内存和4-way 16bit数据路径。
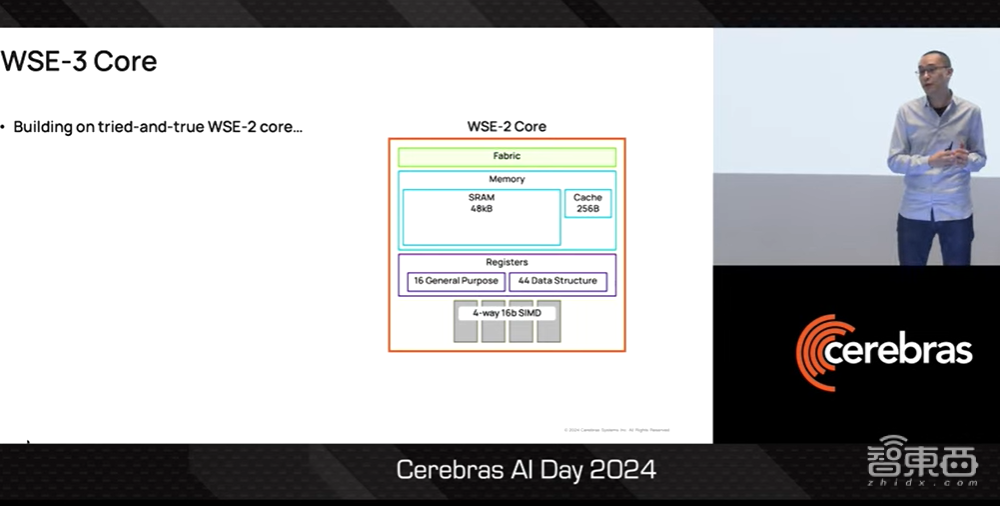
▲Sean Lie介绍WSE-3计算内核(图源:Cerebras AI Day 2024)
在此基础上,我们大幅提高了WSE-3 AI计算的性能,首先为16bit AI计算数据路径改进为8-way SIMD,同时还为8bit AI计算提供了全新的16-way SIMD数据路径。
计算路径的改进将加速神经网络的矩阵乘法。但众所周知,神经网络不仅仅是矩阵乘法。因此,我们还添加了新的指令来加速非线性函数。基于新的计算路径和新的指令,我们的最新产品能提供比上一代产品高出两倍的实际性能。
在内存方面,我们将本地缓存改进为512MB,使其能够提供更宽的数据路径和更高的性能。结合本地内存,WSE-3能够获得完整的内存带宽,以实现完整的SIMD性能。这是GPU内存架构根本无法实现的。
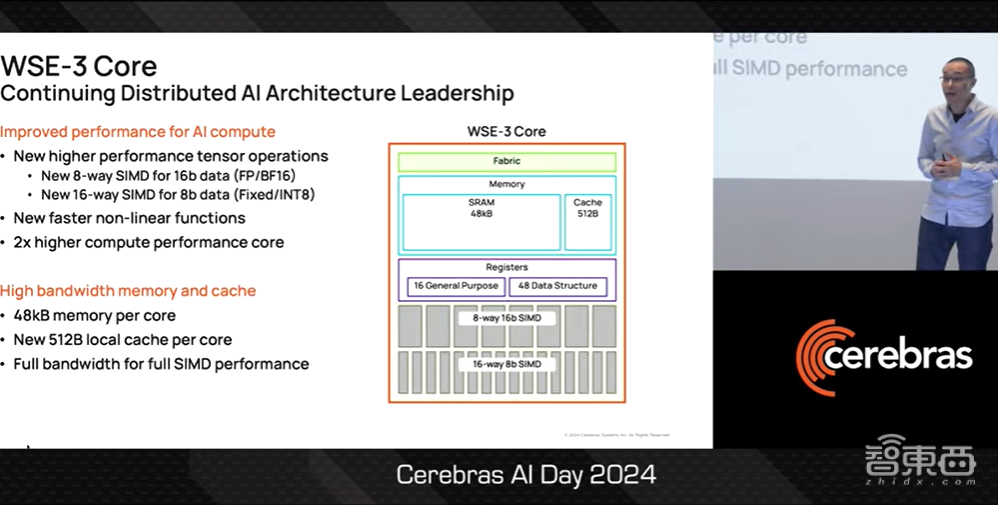
▲Sean Lie介绍WSE-3 AI性能的提升(图源:Cerebras AI Day 2024)
接下来我们要做的就是,把这个小的核心堆叠一万七千次,将核心堆叠成一个晶粒。各位可以将一个晶粒想象成传统的芯片。对于这样的晶粒,我们可以在整个晶圆片上分切出84个。这样一来,一块硅晶圆片总共可切出90万个核心。
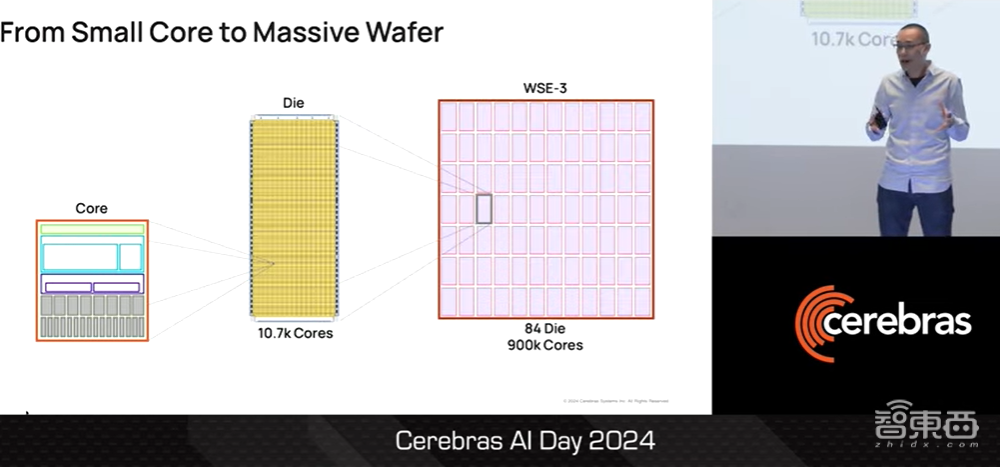
▲Sean Lie介绍内核、晶粒以及硅晶圆片的构成(图源:Cerebras AI Day 2024)
二、统一Fabric架构,多晶粒拓展成整块芯片
在使WSE-3芯片拥有90万个核心外,我们与台积电合作,将我们在WSE-1中掌握的晶圆级集成工艺进行了改进,并将晶圆级集成工艺扩展到5nm,使WSE-3能够基于5nm工艺进行设计。
之所以能做到这一点,是因为我们从一开始就共同设计了统一的Tile层级和Fabric架构,使我们能够用Fabric架构填充整个晶圆,并利用Fabric架构将单个晶粒扩展到多个晶粒。这些就是图中的小蓝线。最终,我们用小蓝线将多个晶粒连接成整个晶圆,这个晶圆就像一个巨大的芯片。

▲Sean Lie介绍WSE-3 5nm工艺(图源:Cerebras AI Day 2024)
现在这些小蓝线是一个大问题。原因在于,用小蓝线连接芯片的互联方式与传统的芯片到芯片的互连方式相比,例如H100GPU在DGX服务器中的互联,两者之间的差别是巨大的。
在晶圆上,我们可以连接10倍以上的晶粒,使其具有33倍的I/O带宽。在此基础上,小蓝线连接的晶圆能效能够提高100倍,这还是我没有把NVLink交换机计算在内的情况下得到的能效提升。
我们能做到这一点的原因其实很简单。当芯片生产商使用比较传统互连方式在芯片与芯片之间驱动bit时,生产商需要通过连接器、印刷电路板来驱动bit,有时甚至需要通过长距离电缆来驱动。这比在一整块晶圆上驱动bit的难度和功耗要大得多,而且也要消耗更多电能。因此,我们把整个晶圆当作一个巨大的芯片来处理。

▲Sean Lie介绍WSE-3小蓝线工艺连接晶圆的晶粒(图源:Cerebras AI Day 2024)
这样以来,我们所做的就是利用这块巨大的芯片,并围绕它建立一个AI计算机系统。我们称之为CS3系统,它是专为晶圆级规模设计的。

▲Sean Lie介绍利用WSE-3芯片建立的CS3(图源:Cerebras AI Day 2024)
三、建立CS3集群,运行形式与单个设备无异
与GPU相比,AI计算机CS3的性能表现简直令人难以置信。有了这样的性能水平,我们就能在单个芯片上实现大规模训练。例如,只需一天时间,各位就能在搭载单个WSE-3芯片的CS3上对开源的700亿参数LLaMA大模型进行微调,以输出高达10亿tokens。
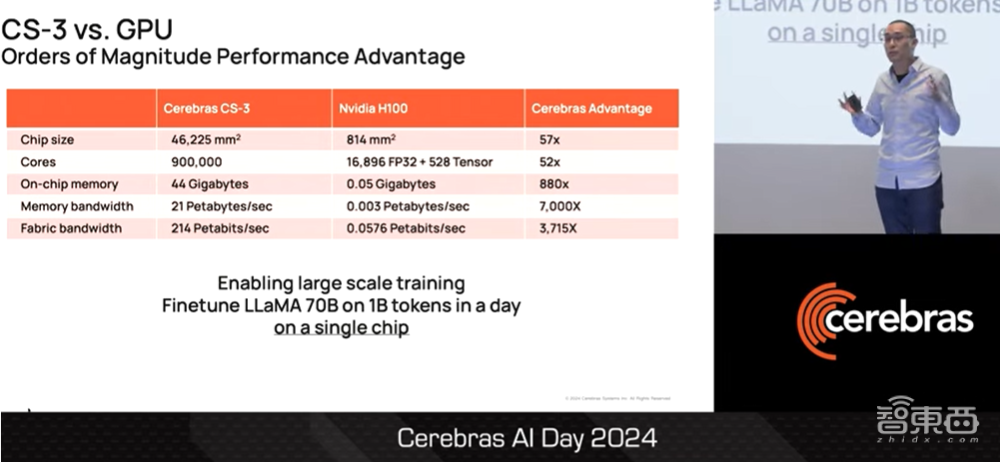
▲Sean Lie对比CS-3与GPU的性能(图源:Cerebras AI Day 2024)
我们并未止步于此。我们以单个CS3为基础,建立了一个CS3集群,并将整个集群设计成单个ML加速器。我们能够做到这一点的原因是WSE-3芯片足够大,大到各位能够在单个WSE-3芯片上运行最大的模型。

▲Sean Lie介绍CS3集群(图源:Cerebras AI Day 2024)
这也是我们能够分解AI计算机CS3的计算和内存的原因。而且,我们可以用数据并行缩放来进行训练模型。各位可以将这种并行缩放训练理解为集群级内存和集群级计算,我们对这样的集群级内存和集群级计算进行了专门的架构设计,因此整个集群在本质上就像台单一设备。
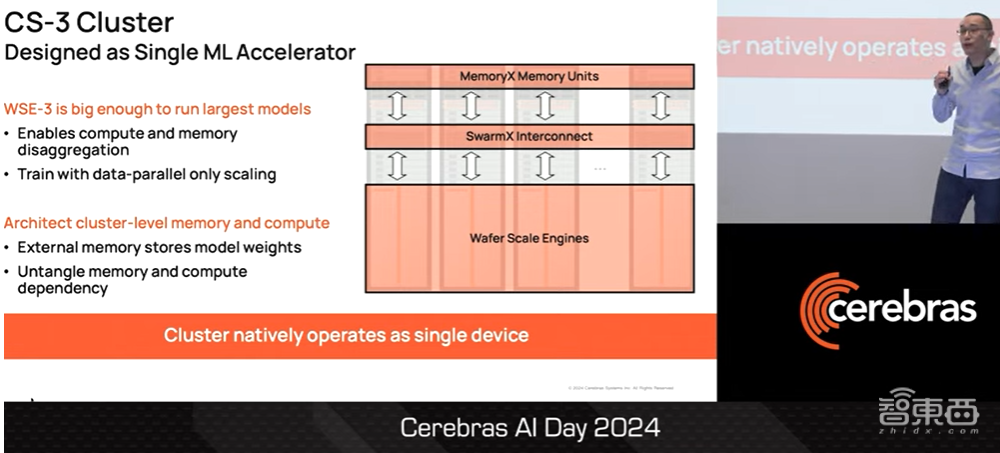
▲Sean Lie介绍将CS3集群整合成一台设备运算的技术原因(图源:Cerebras AI Day 2024)
我们将整个CS3集群整合成一台设备的方法是,将所有模型权重参数放入一个名为MemoryX的外部存储器中,然后将这些权重参数导入CS3系统进行运算。能够实现这一点的原因是,我们在WSE-3上安装了专门的硬件机制,可以在权重参数流入芯片时触发运算程序。
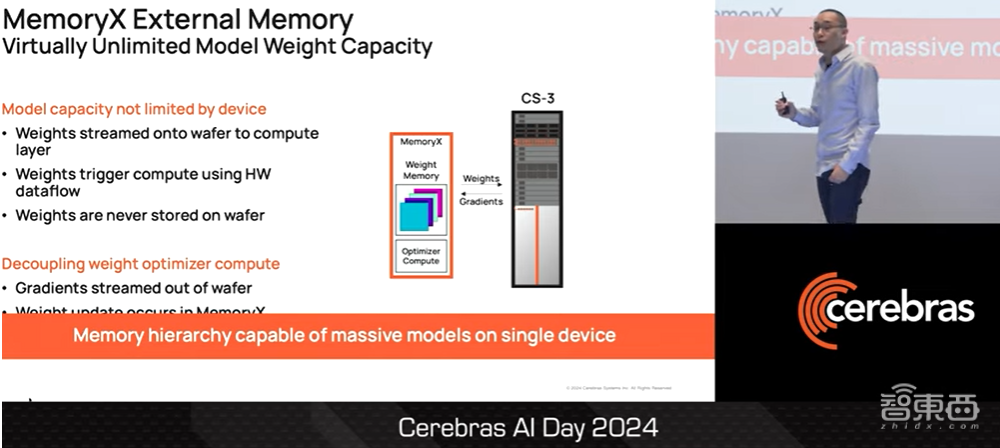
▲Sean Lie介绍MemoryX(图源:Cerebras AI Day 2024)
这些权重参数从不存储在WSE-3芯片上,甚至不会临时存储,因此它们不会占用WSE-3的任何容量。各位可以将MemoryX视为一个专门的存储器层次结构,能够使各位在单个CS3计算机上训练大模型。
接下来,我们使用一种名为SwarmX的特殊结构将单个Fabric架构进行扩展。SwarmX专为数据并行扩展而设计,并内置了broadcast和reduce机制。
由于我们只是对CS3的系统层面进行复制,因此CS3集群在系统上的运行与单一CS3计算机是一致的。这样以来,集群中的所有计算机都是相同的架构、相同的软件界面,并具备相同的执行流程。各位可以从CS3集群中获得集群级的计算能力,但该集群的运行方式与单个CS3计算机无异,因为这数据只通过并行缩放进行处理。
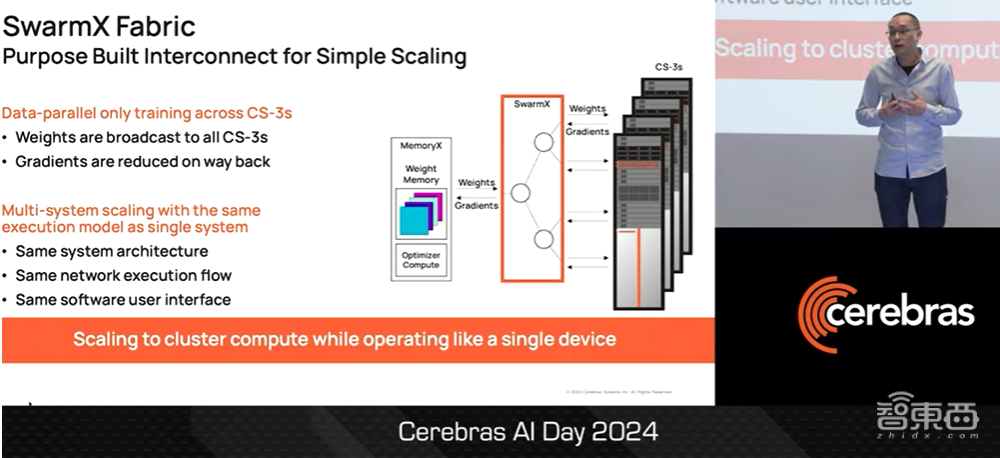
▲Sean Lie介绍SwarmX扩展Fabric(图源:Cerebras AI Day 2024)
在我们上一代CS2集群中,单个CS2集群最多可支持192个CS2系统。这已经是很大的数字了。

▲Sean Lie回顾CS2集群(图源:Cerebras AI Day 2024)
但在最新一代CS3集群中,单个CS3集群能够支持2048个CS3系统,这相当于256 EFLOPS的FP16 AI计算能力。而且CS3集群中所有程序都像单个CS3系统一样。该集群超越了超级计算机的性能,却能给用户带来单一设备的使用体验。

▲Sean Lie展示CS3集群支持的CS3数量和计算能力(图源:Cerebras AI Day 2024)
实现这一目标的原因是,我们已经大幅升级了我们的物理互连,以便SwarmX对Fabric进行扩展。我们将物理链路从上一代的100Gb/s升级到400Gb/s和800Gb/s。所有这些提升都是基于标准的以太网。SwarmX扩展性能强、灵活性高、成本效益高,而且没有NVLink或InfiniBand等定制专有互连的任何挑战。
我们还使用standard_space RDMA,以实现CS3系统的低开销和低延迟。如果将所有这一切汇总到2000个CS3系统上,我们的集群总带宽将达到10Pb/s,是上一代产品的10倍。

▲Sean Lie介绍CS3256 EFLOPS的fp16 AI计算能力的原因(图源:Cerebras AI Day 2024)
有了这样的计算能力,各位只需数小时或数天就能训练出当今最先进的模型。例如,在Meta GPU集群上训练700亿参数LLaMA大模型大约需要一个月的时间。使用CS3集群训练这一大模型只需要一天。更重要的是,整个集群就像一台设备进行运行。

▲Sean Lie介绍CS3训练700亿参数LLaMA大模型的速度(图源:Cerebras AI Day 2024)
在CS3集群的内存方面,上一代CS2集群中的MemoryX支持高达12TB的内存,支持2400亿个参数模型。同样,这已经是一个很大的数字。

▲Sean Lie回顾CS2内存(图源:Cerebras AI Day 2024)
但最新一代CS3集群支持高达1.2PB级内存,可支持24万亿参数模型,提升约为上一代产品的100倍。

▲Sean Lie展示CS3内存(图源:Cerebras AI Day 2024)
之所以能做到这一点,是因为我们使用混合存储来存储权重,并将所有权重都存储在DDR5 DRAM和闪存中,因为混合存储性能高、功耗小、成本低。在CS3集群中,MemoryX可支持高达36TB的DDR5 DRAM,可支持7200亿参数模型;此外,MemoryX的闪存升级到1.2PB,可支持24万亿参数模型。
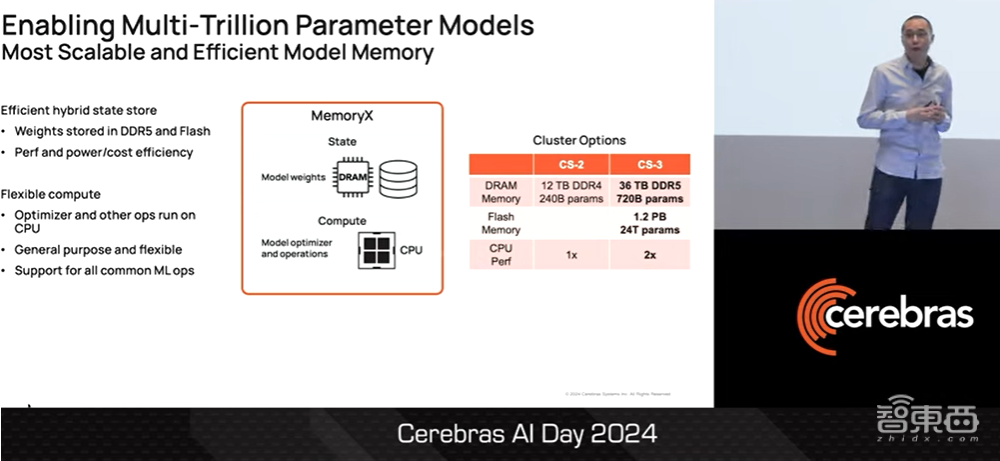
▲Sean Lie介绍提升CS3混合内存(图源:Cerebras AI Day 2024)
此外,MemoryX还具有计算功能,可以运行计算机中优化器的权重,以及模型中其他功能。我们还将MemoryX的计算能力提高了2倍,能够为性能更高的CS3提供支持。这种级别的内存比当今一些最大的GPU或TPU集群还要大,这一切都可以从一个系统中访问。

▲Sean Lie介绍提升CS3内存比其他GPU和TPU集群还要大(图源:Cerebras AI Day 2024)
有了这种级别的内存,再加上MemoryX的计算能力,我们就能在短短几天或几周内训练出未来的万亿参数模型。试想一下,在数千个GPU上训练一个万亿参数模型,可能需要一年多的时间,这几乎是不可能的。而在CS3集群上,我们可以在三周内完成训练,并且整个集群就像一台设备一样运行。

▲Sean Lie介绍用CS3训练大模型(图源:Cerebras AI Day 2024)
四、CS3胜任各种大模型训练,创新源于Cerebras设计理念
对于用户而言,从一台CS3、4台CS3到2000台CS3,无论集群大小如何,整个集群看起来都像一台设备。
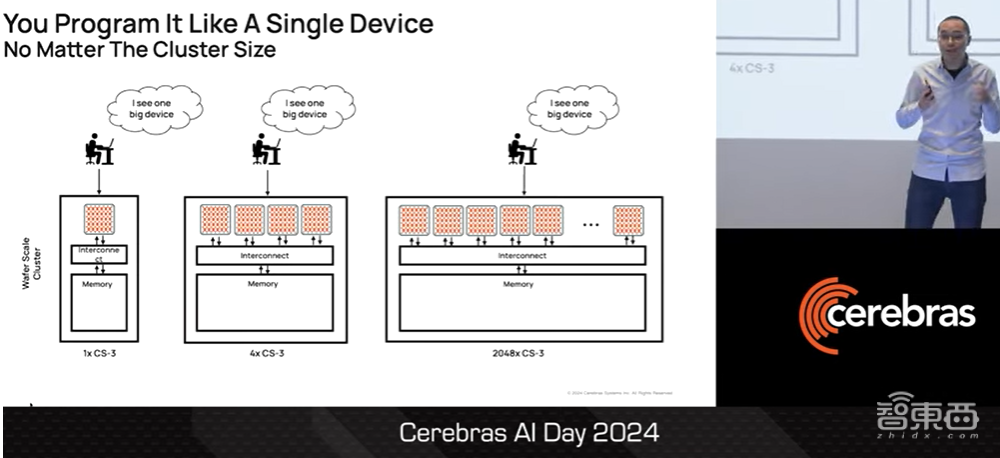
▲Sean Lie介绍作为用户使用CS3的体验(图源:Cerebras AI Day 2024)
客户的大模型总是符合CS3集群进行训练的,不论它是十亿参数模型,还是一百亿、一千亿、几万亿参数模型。在训练的过程中,CS3集群始终能够像单一设备运行。
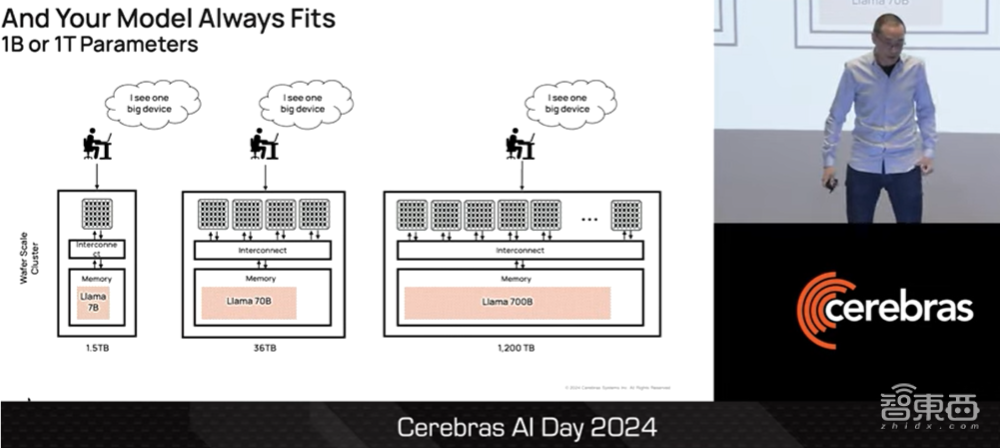
▲Sean Lie称CS3适合用户训练任何一种大模型(图源:Cerebras AI Day 2024)
一个真实的案例是,我们的合作伙伴G42在Condor Galaxy-1上训练他们最先进的300亿参数模型。
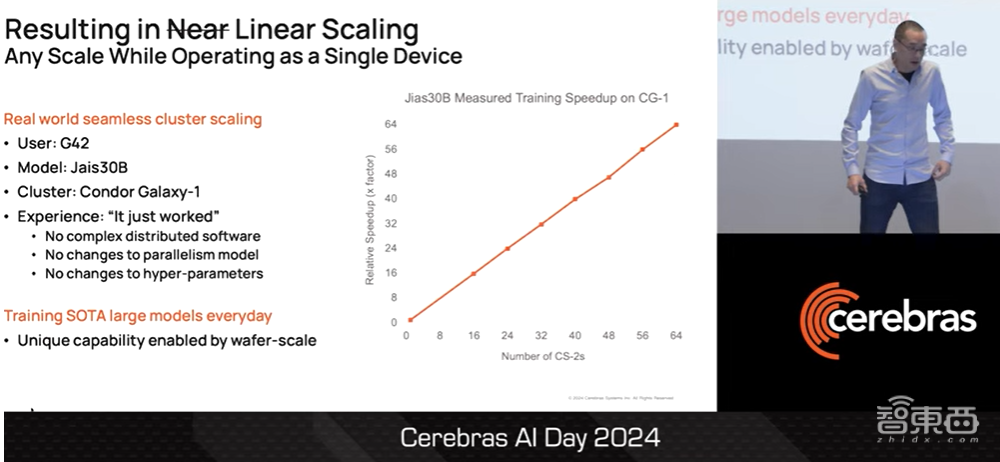
▲Sean Lie介绍G42在Condor Galaxy-1训练300亿参数模型(图源:Cerebras AI Day 2024)
正如各位所看到的,无论是在1个CS3系统还是在64个CS3系统上进行大模型的训练,CS3集群都能在任何规模上进行线性扩展,同时像单个设备一样运行。
CS3集群不需要复杂的分布式软件,不需要我们更改并行模型,也不需要我们更改参数。我们非常自豪,晶圆级架构能够实现“CS3集群像单个设备一样运行”这一独特功能。这样的能力使我们的用户和客户每天都能训练出最先进的模型。
作为一名计算机架构师,我感到非常兴奋,因为促成这一切的是我们Cerebras的核心设计理念,即合理调整问题的解决方案。在座的各位可能有一些人已经知道了,昨天我们的同行非常自豪地宣布,他们现在可以将两块GPU连接在一起。这对他们来说是件大事。

▲Sean Lie介绍Cerebras的理念(图源:Cerebras AI Day 2024)
这就是我们的第三块芯片WSE-3。我们在一块晶圆上将84个晶粒连接在一起,构成了一块巨大的芯片。
更重要的是,我们不能循序渐进地达到目标。我们需要采取不同的方法,才能使我们的产品达到神奇的规模。达到一定规模后,我们的WSE-3芯片才能利用Fabric架构连接晶粒,而不是靠外部芯片互连的方式。后者是低性能、高能耗芯片的连接方式。此外,通过一定规模,WSE-3能够消除和避免分布软件和混合模型并行分布的复杂性。
在WSE-3上使用Fabric架构实现的互联,我们基本上可以获得畅通的高性能通信。换句话说,我们就可以仅通过数据并行扩展和分解数据内存与计算来进行扩展。
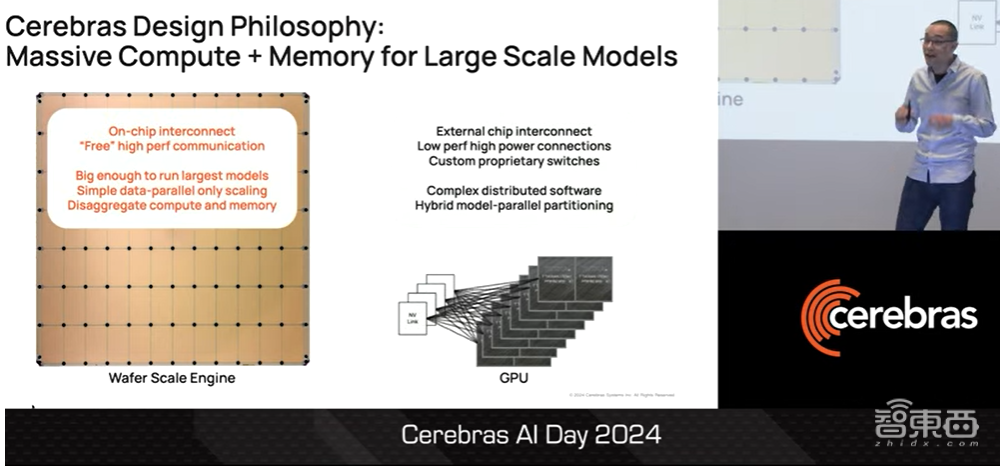
▲Sean Lie介绍WSE-3结合混合内存和MemoryX计算能力提升性能(图源:Cerebras AI Day 2024)
五、利用稀疏性获得足够内存带宽,提升大模型训练效率
当根据问题调整解决方案时,一切都会变得更好。这就是我们打造巨型芯片来解决当今AI领域巨大问题的原因。
我们相信我们能做到,而且我们需要做得比这更好。原因很简单,生成式AI正在以不可持续的速度爆炸式增长。如果各位回顾从语言表示模型BERT发展到以GPT-4为代表的生成式语言模型的过去五年,企业训练最先进模型所需的计算量在这五年内增加了4万倍。五年内训练一个模型所需的计算量增加4万倍,这显然是不可持续的。

▲Sean Lie介绍生成式AI发展给大模型带来的挑战(图源:Cerebras AI Day 2024)
因此作为一个团队,我们必须找到更有效的方法。在Cerebras的大量研究下,我们认为稀疏性(Sparsity)是关键。

▲Sean Lie介绍稀疏性(图源:Cerebras AI Day 2024)
众所周知,神经网络是稀疏的。当人们使用ReLU或Dropout等常用技术在计算中引入大量的“0”这一数值时,计算机网络就会出现天然的稀疏性。事实证明,即使是神经网络的密集层也可以变得稀疏,这是因为模型在设计上被过度参数化了。
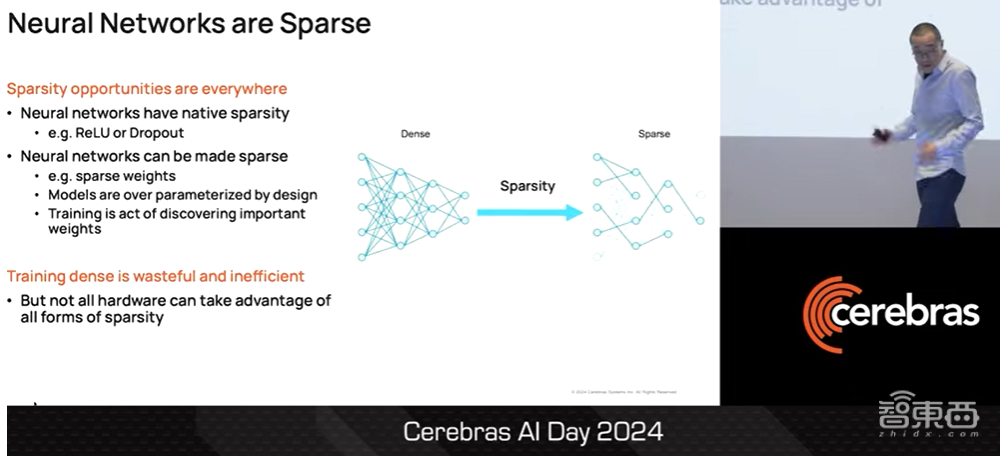
▲Sean Lie介绍神经网络的稀疏化(图源:Cerebras AI Day 2024)
事实上,我们可以把训练神经网络模型的行为看作是发现哪些权重参数是重要的、哪些是不重要的,这就是稀疏性。因此,密集训练本身就是一种浪费,而且效率低下。不过并非所有硬件都能利用各种形式的稀疏性,因为稀疏性加速从根本上说是内存带宽的问题。
这意味着我们可以使用本地缓存等技术,读取内存矩阵中的每行数据,并将其放入本地缓存中,然后在返回内存之前反复使用。密集矩阵乘法每物理FLOPS只需要0.001MB的内存带宽。

▲Sean Lie介绍稀疏性加速的本质是内存带宽问题(图源:Cerebras AI Day 2024)
GPU拥有这种级别的内存带宽,因此可以运行密集矩阵乘法。而稀疏矩阵乘法则完全不同。数据重用率非常低,因此无法使用传统的缓存技术。在极端情况下,我们必须为每个稀疏元素读取内存矩阵中的每一行。因此,要运行所有形式的稀疏性,每个物理FLOP需要多1000倍的内存带宽。
这种稀疏程度和内存带宽是传统技术无法实现的。只有采用晶圆级引擎架构,我们才能获得这种级别的内存带宽,这也是Cerebras CS3能够加速所有形式的稀疏性的原因。
无论是静态或动态的稀疏性,还是结构化或非结构化的稀疏性,我们可以加速,并将所有稀疏性转化为训练速度。
下面是一些例子。我们可以加速激活动态的稀疏性。去年谷歌发表的一篇论文显示,大模型中95%以上的FFN层可以通过反弹稀疏性实现稀疏。这意味着训练FLOPS整体上减少了1.7 倍。我们可以利用这一特征加速对稀疏性的激活。

▲Sean Lie介绍CS3加速稀疏性的案例(图源:Cerebras AI Day 2024)
例如,Mistral最近发布了一个Mixture of Experts(MoE)模型,该模型在FFN层中的稀疏度达到75%。这意味着整体训练FLOPs减少了约2倍。我们还可以加速完全非结构化的稀疏性,Cerebras目前正在开发这方面的技术。我们的实验已经证明,我们可以在减少2.8倍训练FLOPS的情况下加速高达75%的稀疏性。
在Cerebras,我们相信只有通过硬件才能加速所有形式的稀疏性,但我们真的能靠加速稀疏性来解决训练增长不可持续的问题吗?
现在你可能会想,稀疏性可以进行加速,那么它也能帮助推理吗?事实证明,稀疏性可以在包括CPU在内的各种硬件上实现推理。因此,Cerebras一直与在Neural Magic合作,以实现稀疏性的推理能力。

▲Sean Lie认为稀疏性也可以帮助推理(图源:Cerebras AI Day 2024)
以上是Cerebras联合创始人兼CTO Sean Lie的完整演讲实录。
