








智东西(公众号:zhidxcom)
作者 | 李水青
编辑 | 云鹏
在刚刚过去的24小时里,谷歌Gemini的一段演示视频爆火全球。
像机器人贾维斯一样,谷歌Gemini一边看着用户绘画、变魔术、放视频,一边实时对画面进行分析,并主动和用户对话交谈,让人大呼“《钢铁侠》的AI助手指日可待”。
然而,质疑声也随之而来。产业大佬如HuggingFace技术主管菲利普•施密德(Philipp Schmid)称谷歌夸大了测评成绩;爆火的谷歌Gemini宣传视频也被曝不是实时演示录制,而是精心挑选和剪辑的营销内容,不太可信。
对此,谷歌立刻甩出了Gemini演示视频的制作记录文章,大方承认视频经过了后期处理,并秀出在视觉谜题、多模态对话、逻辑与空间推理、翻译视觉效果等方面的交互过程图文解析。
▲谷歌发布了题为《如何制作:通过多模态提示与Gemini互动》的文章
今日,谷歌DeepMind研究与深度学习主管奥里奥·维尼亚尔斯(Oriol Vinyals)再度自证,在X平台上发文称:“视频中的所有用户提示和输出都是真实的,简洁起见做了缩减”,并发布了一段Gemini Pro的对应演示视频。
但原宣传视频是用Gemini Ultra演示的,因此这也招来网友质疑:“为什么不敢放出原视频?”

关于谷歌Gemini演示视频真伪的争论暂时没有定论,但Gemini的原生多模态模型的招牌已经打出,向GPT-4发起了奇袭。
一位来自谷歌DeepMind的研究人员告诉智东西,Gemini的视觉/视频理解能力,是谷歌挑战GPT-4(GPT-4V)的最强点。
不同于市面上的图文拼接的多模态模型,Gemini是一个原生的多模态大模型,是将文本、代码、图片、视频、语音合在一起放进模型里训练而来的,因此能实现更均衡的多模态输出及任意模型切换。据称,谷歌原生多模态的视觉/视频部分,与包括GPT-4在内的大模型形成了代际差。
Gemini演示视频被看作谷歌“复仇”OpenAI的力证。据谷歌称,Gemini首次在MMLU(大规模多任务语言理解)测评上超过人类专家,在32个多模态基准中取得30个SOTA(当前最优效果),全方位赶超GPT-4。《突发!谷歌深夜掀桌子,发最强大模型Gemini,跑分碾压GPT-4【附60页技术报告】》
那么谷歌Gemini到底有多牛?其在多模态及视觉能力上真实表现如何?通过逐帧解析谷歌Gemini演示视频背后的形成过程和技术原理,本文对此进行了深入探讨。
一、懂读心术、贯通文理,Gemini“暴走”竟靠提示词?
看着十分抽象的简笔画、几秒闪过的短视频,接收语焉不详的问题,Gemini却能立马明白用户的意图,给出正确的答案,并不动声色的展现出自己文理兼修的实力。
这是如何实现的?背后离不开提示词的强大“助攻”。
1、空间逻辑力了得,一眼看出天文知识Bug
“这样排序正确吗?”
“不,正确的顺序是太阳、地球、土星。”
几张简笔画,一个抽象的问题,Gemini不仅识别出了图中所画的对象是什么,还准确根据自己的天体物理知识,推断出顺序摆放不对。这让人们不得不感叹AI“成精”了。

题都没说清楚,Gemini为什么能这么对答如流?
根据谷歌昨天第一次发布的解析文件,工作人员真实输入的提示词可能不是视频中所示,而是一系列非常照顾Gemini理解的句子。
根据谷歌发布的文章,其工作人员首先给Gemini看三张按顺序摆放的天体图片时,他输入的内容是:“这是正确的顺序吗?考虑与太阳的距离并解释你的推理。”
可见图片对象、知识点和回答要求都被谷歌工作人员一一Cue到了,这就好像给考生的考题做了批注提醒。
Gemini是在理解其中含义的基础上作答的:“不,正确的顺序是太阳、地球、土星。太阳距离太阳系中心最近,其次是地球,然后是土星。”

而根据谷歌方今天发出的第二次解读,用户首先需要输入一段关于模拟专家身份的说明,然后上传图片并输入视频中简短的提示词“这是正确的顺序吗?”,Gemini就会给出正确的答案。这一提示词前置的方法本质与上述做法类似。

▲谷歌DeepMind研究与深度学习主管发出Gemini Pro演示视频
谷歌本次宣布了Gemini三个版本:适用于高度复杂任务的Gemini Ultra、适用于各种任务的最佳模型Gemini Pro以及适用于端侧设备的Gemini Nano。目前,接入Bard的为Gemini Pro,与GPT-3.5是一个能力层级。
智东西测评发现,Bard对上文提到的两种提示词方式都会给出同一正确答案。
2、联想空气动力学知识,一秒选出更快的赛车设计
在第二道题中,谷歌员工给到两张小车的图片让Gemini做松木赛车挑战,其实也是给了比较详细的提示词。
在演示视频中,Gemini只是被问了“从设计上看,哪个车会跑得更快”。
Gemini立刻回复:“右边的车更快,它更符合空气动力学。”
既要识别左右两辆车,又得自己联系空气动力学知识点,Gemini看起来确实有点神。

但实际上,这也似乎不是仅靠原有提示词触发的效果。
按照谷歌发布文章的解读,谷歌工作人员输入的内容是:“这些汽车中哪一辆更具空气动力学性能?左边那个还是右边那个?使用具体的视觉细节解释原因。”
Gemini答:“右边的车更符合空气动力学。它具有更低的轮廓和更流线型的形状。左边的汽车轮廓更高,形状更四四方方,这使得它的空气动力学性能较差。”
可见,问题限的比较死,因此Gemini的回应也比较严丝合缝。

也就是说,Gemini是具备空间推理和专业知识能力的,但这离不开提示词的帮助。
通过提供图片空间信息和背后知识点线索,提示词工程师和Gemini一起完成了挑战。
3、兼具文化素养,轻松识别模仿的电影桥段
“他们在演什么电影?”
“我想他们是在表演《黑客帝国》中,著名的“子弹时间镜头。”
通过一段几秒钟的视频,Geminij就推断出了这出自哪一部电影,并且还给出了具体涉及的剧情桥段。这可能是很多人都做不到的事。

但按照谷歌的解析文件,这个例子背后制作过程却不是视频呈现的那么简单,而是更详细的提示词做支持。
当谷歌工作人员向Gemini展示视频的几帧静止画面,让它猜电影:“猜猜我在演什么电影。”

Gemini回答:“黑客帝国。”
工作人员进一步说:“好了!但具体是哪一部分呢?看我的身体动作。”
Gemini回答:“尼奥躲避子弹的部分。”
可以看到,谷歌解析文件里介绍的Gemini并不是视频里呈现的“贾维斯”,或许更像一个需要老师循循善诱的“小朋友”。
二、一眼看穿经典魔术,Gemini强在“时间线推理能力”
Gemini的酷炫演示效果离不开提示词的助攻,但不能抹去核心逻辑推理能力的功劳。
比如Gemini拆解经典魔术的功力也让很多人惊掉下巴,大呼“魔术师要失业了”,这绝不仅仅是靠输入策略实现的。
在这个例子的演示中,谷歌工作人员先展示了握在右手心里的硬币,然后双手翻转,手心向下。
还没等工作人员发话,Gemini就迫不及待地说:“硬币应该在右手下面。”

然后工作人员并没有说话,而是拿起右手,只见右手下根本没有硬币。
Gemini对此连忙回应:“嗯……我不知道……硬币在左手下面。你运用了一些手法,使硬币看起来好像消失了。”

工作人员啥也没说,Gemini就像一个人似的知道这是在变魔术,并根据手势变化给出了一波猜测,这实在让人匪夷所思。
Gemini为什么能不被“唤醒”就明白了工作人员想问什么?又为什么能看穿这个魔术?
前者很可能是一个剪辑后的效果,幕后演示应该是先有提示词。同时,Gemini对这一魔术的破解,也是在工作人员一步步的提示推动下完成的。
按照谷歌公开的制作过程,谷歌工作人员先输入一张照片说:“解释一下我在做什么。”
Gemini回答:“你右手拿着一枚硬币。”

紧接着,工作人员紧接着按下硬币,问:“你认为硬币在哪里?”
Gemini回答:“硬币在你的右手。”

 这是一个合乎逻辑的答案,但工作人员向Gemini展示下一张图片时玩了点花招:他打开右手,并没看到硬币。
这是一个合乎逻辑的答案,但工作人员向Gemini展示下一张图片时玩了点花招:他打开右手,并没看到硬币。
并说:“看看这里,发生了什么?”
Gemini回答:“硬币不见了。”

Gemini注意到硬币不见了,但它能概括出刚刚发生了什么事吗?
于是工作人员说:“从第一张图片开始,逐步总结可能发生的情况。”
这一步十分关键,Gemini回答: “1. 一开始,你右手拿着一枚硬币。2. 然后你用手做了一个动作,硬币就消失了。3. 然后你表明硬币不见了。”
可见,Gemini正在利用这次对话的整个背景,包括文本和图像,来总结它的答案。
最后工作人员再问道:“你能解释一下它是如何消失的吗?”
Gemini回答:“硬币被捧在手里。”
所以说,Gemini是在工作人员一步步的引导下,完成了时间线的推理,从而看透了这个“魔术”。
而这种时间线推理能力,意味着对事情的先后有明确的判断,懂得事情发生的因果(而不仅是规律),这是Gemini令人赞叹的地方。
当然,也有博主将Gemini的这一能力与GPT-4对比,发现后者也能完成一些类似任务,比如猜出东西在三只杯子的哪一个里面。
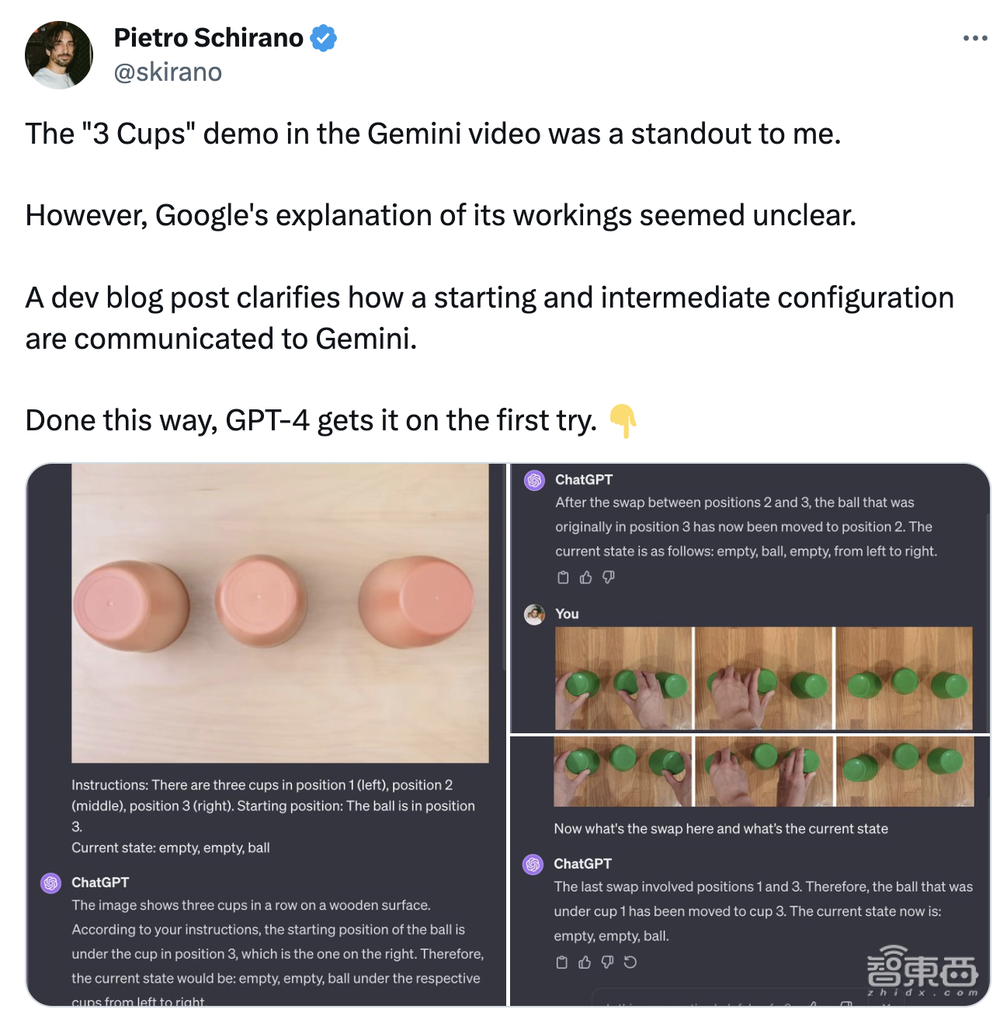
▲开发者彼得罗·斯基拉诺(Pietro Schirano)称用GPT-4复现了“三个杯子”案例
三、自创游戏师出有门,Gemini强在视觉理解能力
很多人对Gemini创作的“你指我猜”游戏印象深刻。但Gemini并不是天生游戏高手,而是先经过了求师学艺。
这是怎么回事?先来回顾下Gemini的神操作。
谷歌工作人员给到Gemini一张海洋地图称:“根据你所看到的,想一条游戏创意,并加入表情符号。”
Gemini立马回复:“这样如何?我们来玩‘猜国家’游戏。”

工作人员说:“可以,我们开始吧。”
于是Gemini就给出了一个提示:“这个国家是袋鼠、考拉和大堡礁的故乡”
工作人员说:“哦,这太简单了!”随即,他指出了地图上澳大利亚的位置。
Gemini回复:“正确。”

这种几秒中之内想出一个复杂交互的游戏,令很多人赞叹。这是因为,Gemini在之前得到了特别的“紧急训练”:
首先,工作人员向Gemini提示这个游戏的核心思想:
说明:我们来玩一个游戏。想想一个国家并给我一个线索。线索必须足够具体,只有一个正确的国家/地区。我会尝试在地图上指出该国家/地区。
接下来,工作人员为Gemini提供了一个游戏玩法示例,以此展示它被期待如何处理错误和正确答案:
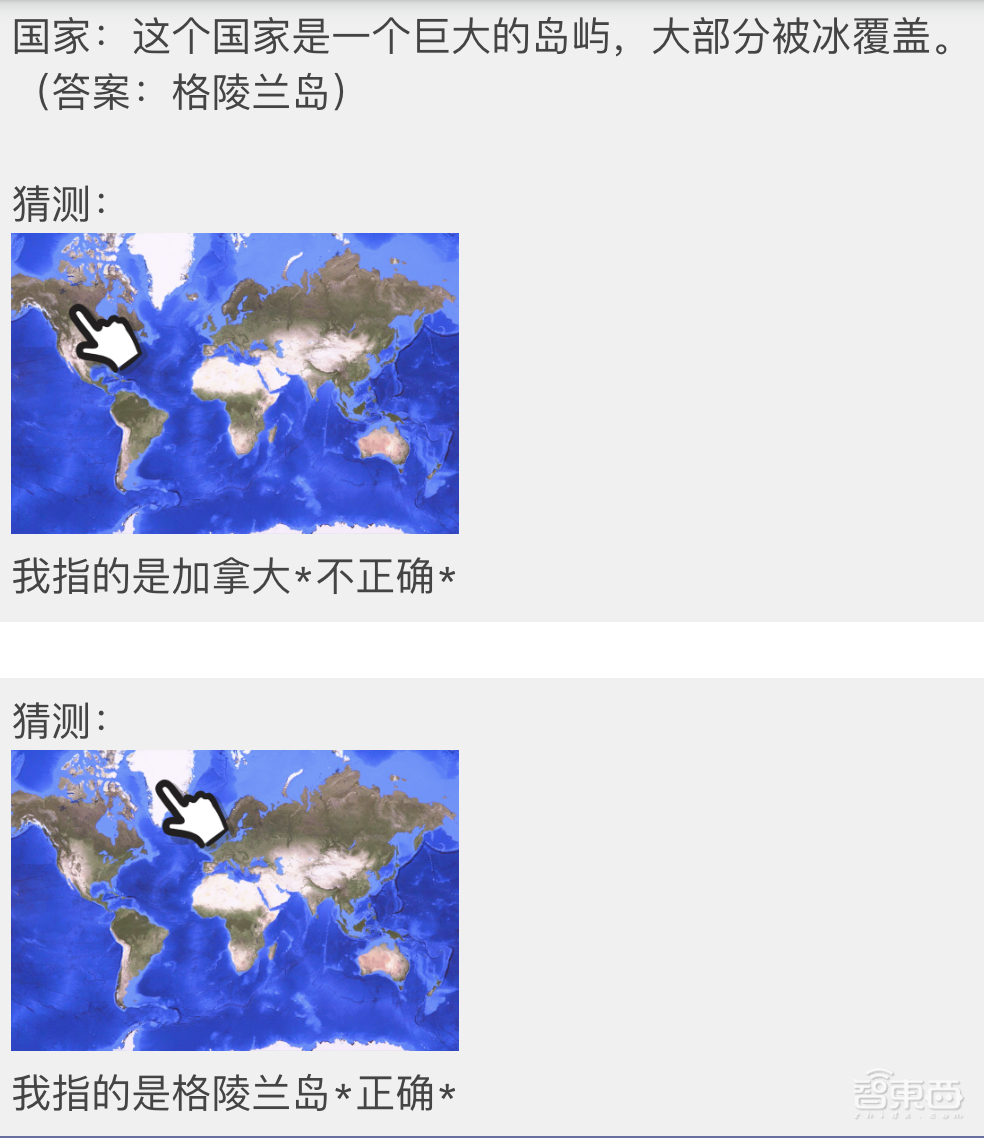
接下来,工作人员对Gemini的学习情况进行测试:
他先试了一道题:这个国家以其独特的野生动物而闻名,包括袋鼠和考拉。(答案:澳大利亚)
工作人员首先尝试指向错误的地方:

Gemini猜测:一个人用右手食指指着世界地图上的巴西,因为该地图包括蓝色的海洋和没有国家边界的绿色大陆。因此不正确。
Gemini的推断是正确的,接下来工作人员指向地图上的正确位置澳大利亚:
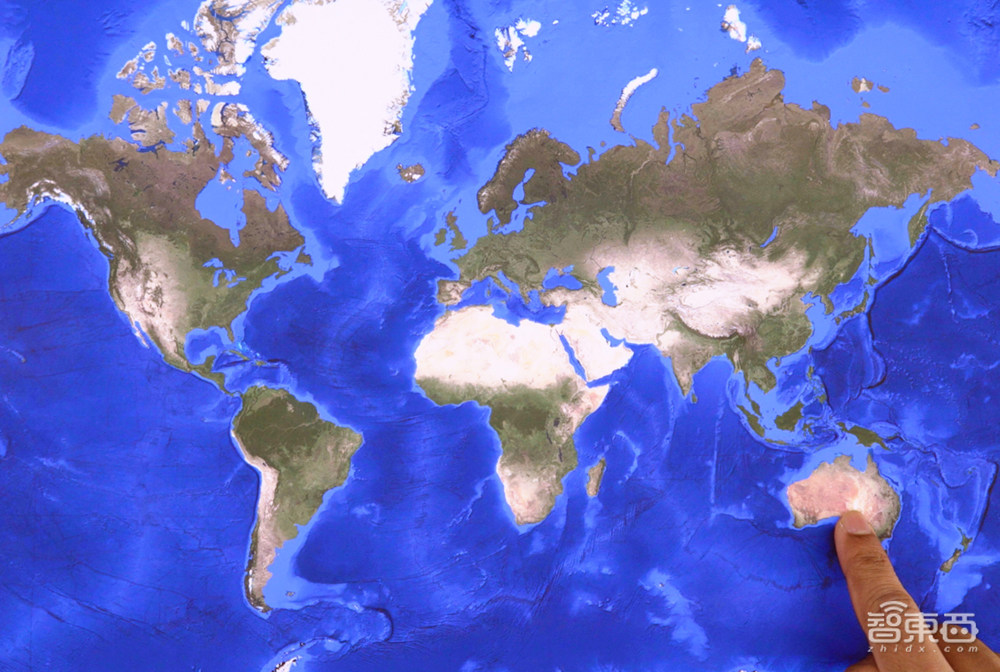
Gemini给出判定:正确。
可以看到,Gemini之所以能够创作游戏,是工作人员提前告诉了它存在这样一个游戏,相当于一个更复杂的提示文段。
虽然Gemini并不是天生能设计出这个游戏,但却展现出了极强的图文多模态理解能力。仅仅通过举例,具体说是通过例子里的插图,Gemini就学会了一个复杂游戏逻辑,这可能就比很多人要强。
不同于市面同行将视觉和文本模型拼接的做法,Gemini是业内少有的从头开始构建的多模态大模型,它可以同时识别和理解文本、图像、音频、视频和代码五种信息。这意味着用户可以自然地交错输入:说几句话,添加图像、文本,或是短视频。同样,模型也会自然地交错文本和图像作为输出。
四、看毛线团给创作建议,“交错图文生成”能力或成杀手锏
Gemini还可以用图文结合的方式回应用户需求,具备“交错文本和图像生成”能力,这或许也是它的一个“杀手锏”。
在演示视频中,当谷歌工作人员让Gemini帮他想想这些材料可以做什么时,Gemini随即给出了“编织的火龙果和生日蛋糕”的建议。
如下图所示,Gemini给的答案不仅有文字建议,还有对应的图片示意。

当工作人员将绿色的毛线换了一团蓝色的,并要求Gemini帮他想一些动物造型之后,Gemini立马给出了编织的小猪、章鱼和兔子三个建议,并给出了如下所示的示意图。

这是如何实现的?谷歌的图文交错生成模式在业内还比较少有,当然也离不开提示词的配合。
首先,谷歌工作人员给Gemini提供了一个交互示例:



然后谷歌人员告诉Gemini的核心互动规则:
“我会给两个毛线球拍一张照片,我希望你(Gemini)都能想出一个我可以制作的东西的想法,并生成它的图像。”
紧接着,谷歌人员向Gemini展示了一对它尚未见过的新纱线颜色,看看它是否可以概括:
“给我三个关于我可以用这两种颜色制作的钩针作品的想法。”

随后,Gemini立马给出了三个建议:


可以看到,Gemini正确地识别了新颜色,并给出了比较合适的建议。
虽然提示词功劳不小,但这个应用还是牛在背后的“交错文本和图像生成”能力。
谷歌创意总监亚历山大·陈(Alexander Chen)称,Gemini的图文输出从根本上有别于今天市面上的文生图模型。因为,它不仅是将指令传递给单独的文生图模型,还能看到木桌上的实际图像,真正对文本和图像进行多模态推理。
不过,陈也坦言这个功能在Gemini初版本中还没开放,只是放出来给大家看一眼。
五、图音画无缝翻译,Gemini秀出应用联动能力
“画图触发BGM(背景音乐)”是谷歌Gemini本次演示的另一神来之笔,展现出其插件扩展方面的野心。
当谷歌员工画出一把吉他的简笔画,Gemini立马说“我看到你正在画吉他”,并随即播放了一首吉他相关的曲子。

当画面上多了一个类似音箱的图像,Gemini称“你给吉他加了一个扬声器……我们现在可以放点更响亮的音乐了。”于是,音乐立马被切换成一首更响亮的交响曲。

随着画布上增加了“鼓”,Gemini主动将音乐切换成了带鼓点的音乐。

当画布上增加的“椰树”,Gemini则主动切换了一首更加惬意的音乐。

由前面的解析可知,要实现这些效果,Gemini大概率也是需要谷歌员工先发出提示词触发的。
根据陈的解读,当谷歌工作人员输入以下图片及文字,Gemini就能“看图搜索音乐”。
“步骤1.观察这幅图画,描述其中的所有内容,并针对良好的音乐配乐流派、情绪或配乐提出有趣且具体的想法。
步骤2.通过以下形式提供搜索查询:‘搜索[插入查询]’”

Gemini对此回应:
“该图画的是吉他、鼓和扩音器。还有一棵棕榈树。气氛有趣、乐观、充满热带风情。流派是雷鬼音乐。该配乐可用于以热带地区为背景的电影或电视节目。
搜索‘热带度假的雷鬼音乐’”
可见,图片理解和插件操作一气呵成。
Gemini通过“画图搜索音乐”的应用,实际上是为了展现其图像理解与应用插件结合的能力,那就是:Gemini会对其所看到的内容进行推理,然后生成一个搜索查询,进而搜索到所需的配套应用插件。
从这一过程来看,Gemini强调的是一种多模态“翻译”能力。
这不是语言的翻译,而是从绘画、音乐到思维、插件应用的多种模态翻译。通过多模态提示,用户可以使用Gemini在不同输入和输出之间,发明自己的全新“翻译”特效。
结语:谷歌与OpenAI竞赛打响
通过深扒谷歌Gemini的演示过程,我们发现,谷歌Gemini确实没有宣传视频里看起来厉害,但其在多模态对话、多模态生成、逻辑与空间推理、翻译视觉效果、文化理解等方面确实拿出了实力,向OpenAI发起了强力挑战。落地情况如何,还要等Gemini Ultra发布之后看真实效果。
可以预测,谷歌Gemini与OpenAI GPT两大阵营竞赛即将打响,将在模型能力、应用家族及生态方面展开更深入比拼,而开源大模型与头部玩家的差距或许会变大,行业的头部效应将更加明显。
