








1、Meta开源实时翻译系列模型Seamless
2、Meta推出音频生成模型Audiobox
3、Meta发布多模态数据集Ego-Exo4D
4、阿里云通义千问开源720亿参数大模型
5、阿里云举办首届通义千问AI挑战赛
6、阿里国际发布3款AI设计生态工具
7、阿里推出AI动画生成框架 从静态图像生成动画
8、昆仑万维发布Agent开发平台天工SkyAgents
9、出门问问奇妙元推出奇妙助手功能
10、腾讯牵头制定全球首个金融风控大模型国际标准
11、山东:瞄准AI等七大未来产业 大力推进AI+
12、Adobe等推出DMD方法 生图速度提升30倍
13、Stable Audio新增支持上传音频生成音乐
14、基于大学知识的多模态LLM测评基准MMMU发布
15、微软未来三年向英国AI基础设施投资225亿元
1、Meta开源实时翻译系列模型Seamless
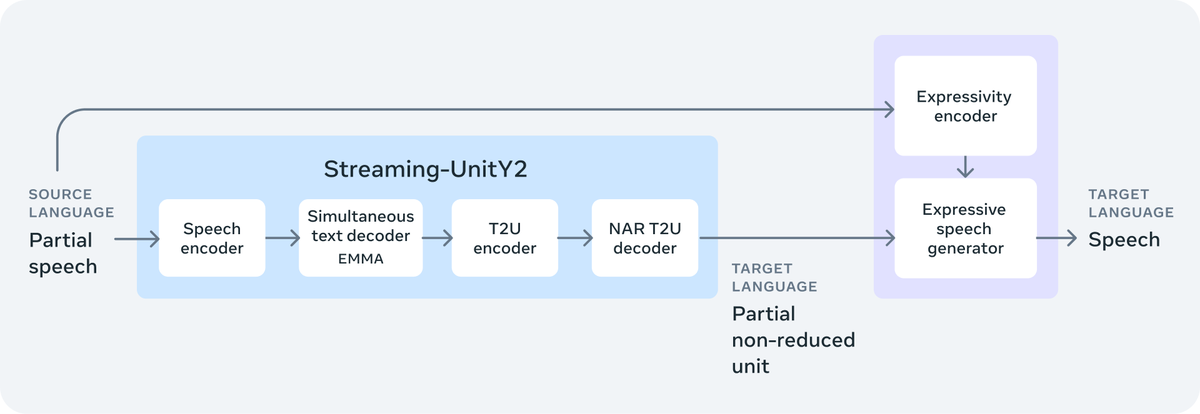
今日,Meta推出实时翻译系统Seamless。为了构建Seamless,Meta开发了一种用于保留语音到语音翻译中表达能力的模型SeamlessExpressive,以及一个流式翻译模型SeamlessStreaming,可以以几乎不到两秒的延迟提供最先进的结果。所有模型均基于Meta在8月发布的基础模型SeamlessM4T v2构建。据介绍,与之前在表达性语音研究方面的努力相比,SeamlessExpressive解决了韵律中某些尚未开发的方面,例如语速和节奏停顿,同时还保留了情感和风格。该模型目前在英语、西班牙语、德语、法语、意大利语和中文之间的语音到语音翻译中保留了这些元素。SeamlessStreaming支持近100种输入和输出语言的自动语音识别和语音到文本翻译,以及近100种输入语言和36种输出语言的语音到语音翻译。Meta开源了全部四种模型,以便研究人员在此基础上进一步研究。
开源地址:
github.com/facebookresearch/seamless_communication
Demo地址:
seamless.metademolab.com/expressive
2、Meta推出音频生成模型Audiobox
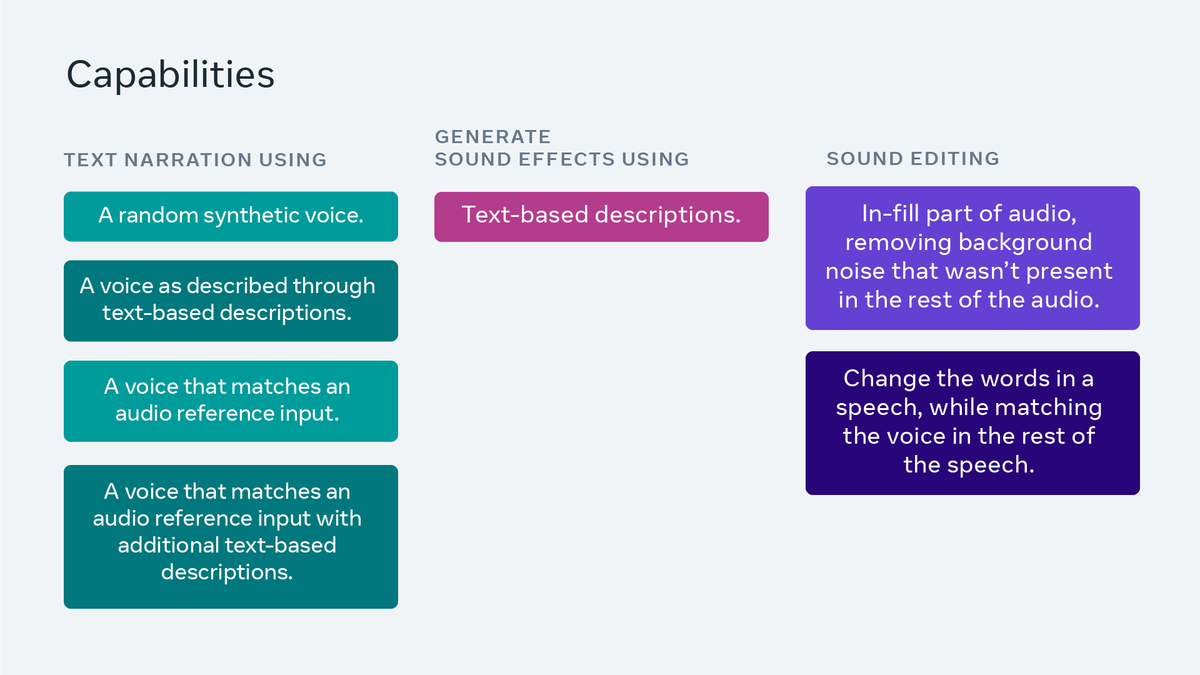
今日,Meta推出音频生成模型Audiobox,该模型可以结合使用语音输入和自然语言文本提示来生成语音和音效,从而可以轻松地为各种用例创建自定义音频。Meta称,据其所知,Audiobox是第一个支持语音和文本双输入以进行自由语音重新设计的模型。Meta将在接下来的几周内开放基于Audiobox的应用程序,以及展示Audiobox功能的交互式演示。
3、Meta发布多模态数据集Ego-Exo4D
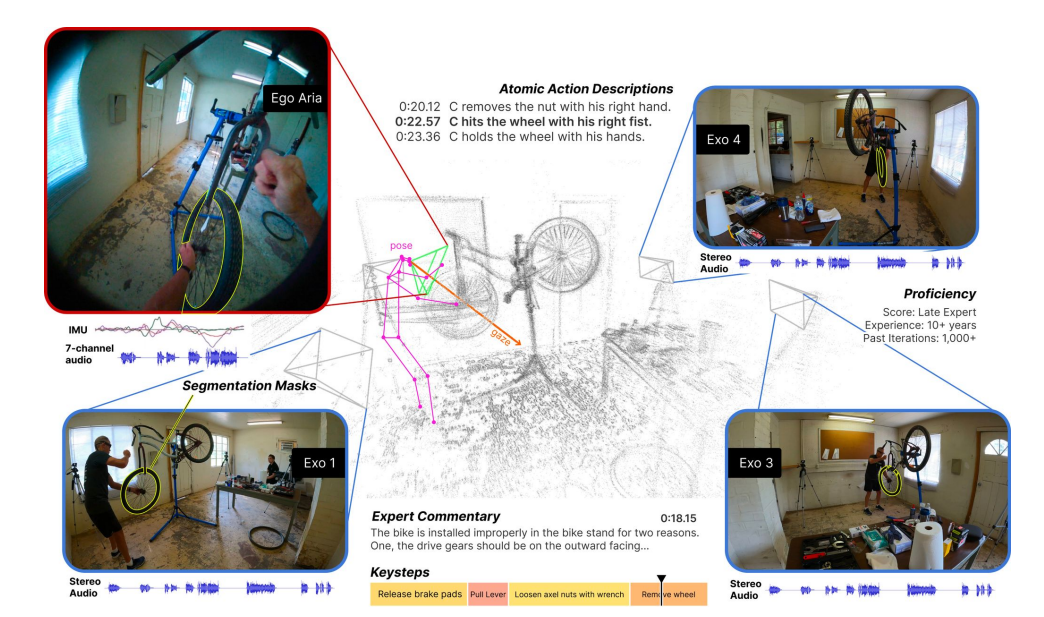
今日,Meta推出一个基础数据集和基准套件Ego-Exo4D,用于支持视频学习和多模态感知的研究。据介绍,Ego-Exo4D是Meta的FAIR(基础人工智能研究)、Aria项目和15所大学合作伙伴历时两年的研究成果。Ego-Exo4D的核心是同时捕捉参与者佩戴摄像头的第一人称(自我中心)视角和周围摄像头的多个第三人称(非自我中心)视角。两个视角相互补充,自我中心的视角揭示了参与者的视听感知,而非自我中心的视角则揭示了周围场景和上下文。研究者将在本月开源数据(包括超过1400小时的视频)和用于新基准测试任务的注释。
论文地址:
ego-exo4d-data.org/paper/ego-exo4d.pdf
项目主页:
ego-exo4d-data.org
4、阿里云通义千问开源720亿参数大模型
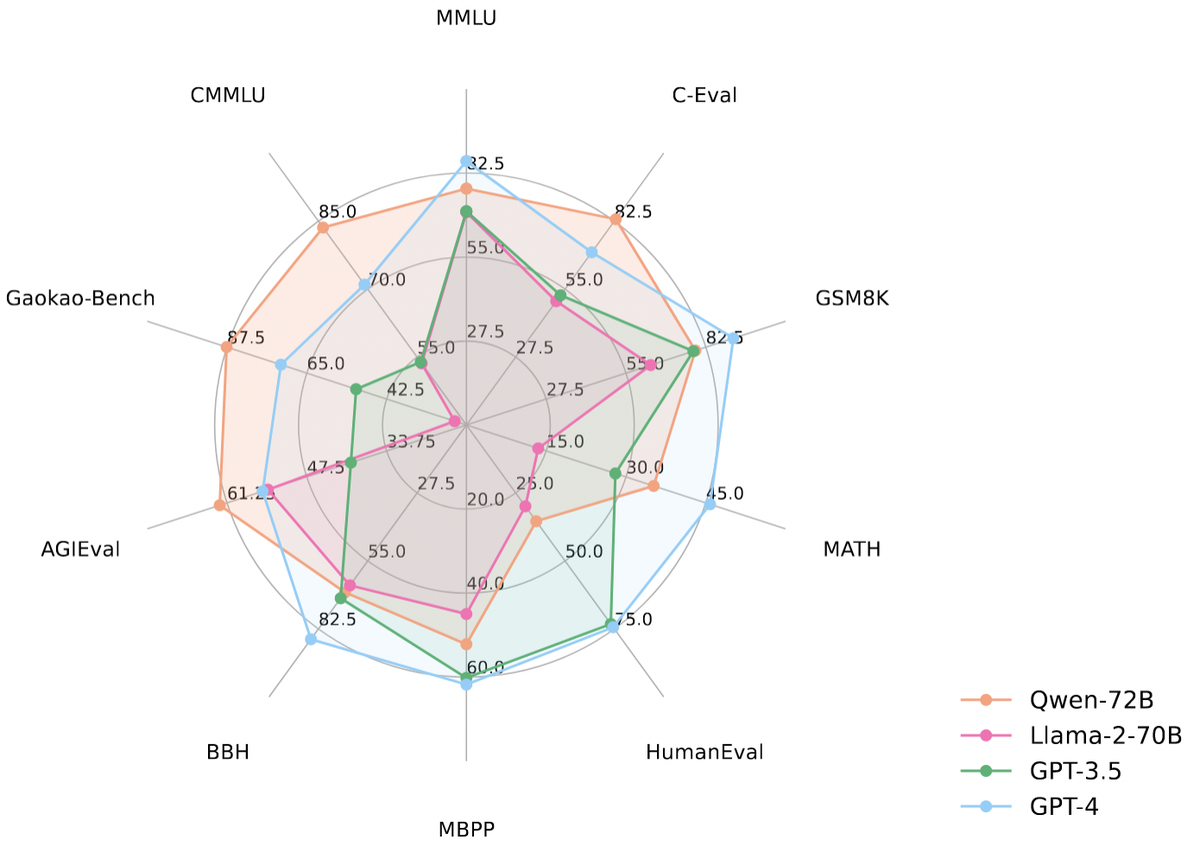
今日,阿里云在京举办通义千问发布会,开源通义千问720亿参数模型Qwen-72B。据介绍,Qwen-72B在10个权威基准测评创下开源模型最优成绩,性能超越开源标杆Llama 2-70B和大部分商用闭源模型,可适配企业级、科研级的高性能应用。通义千问当天还开源了18亿参数模型Qwen-1.8B和音频大模型Qwen-Audio,在业界率先实现“全尺寸、全模态”开源。
5、阿里云举办首届通义千问AI挑战赛
今日,在通义千问发布会上,阿里云宣布首届“通义千问AI挑战赛”开赛,参赛者可免费使用通义开源模型家族,包括刚刚发布的720亿参数模型Qwen-72B。赛事分为算法和Agent两大赛道,前者针对通义千问大模型的微调训练,希望通过高质量的数据探索开源模型的代码能力上限;后者针对基于通义千问大模型和魔搭社区的Agent-Builder框架开发新一代AI应用,促进大模型在各行各业的落地应用。即日起,开发者可通过天池平台报名参赛,主办方将为参赛者提供价值50万元的免费云上算力和奖金。
6、阿里国际发布3款AI设计生态工具
据环球网报道,今日,在第六届中国国际工业设计博览会上,阿里国际数字商业集团发布了3款设计生态工具:堆友、Pic Copilot、鹿班AI,覆盖AI绘画、AI模型创作、AI图像和视频处理等功能。据悉,这3款产品目前已经服务数十万商家、覆盖50万设计师。此外,工信部国际经济技术合作中心还与阿里国际设计签署了框架协议,共同促进数智设计的发展。
7、阿里推出AI动画生成框架 从静态图像生成动画
11月29日,来自阿里的研究团队发布论文,利用扩散模型的能力,提出了一个专门针对角色动画的新框架Animate Anyone,可从静态图像AI生成动态视频,从而将任意角色动画化。为了保持参考图像中复杂外观特征的一致性,作者改进了ReferenceNet算法,通过空间注意力融合详细特征。为了确保可控性和连贯性,作者引入了一个高效的姿势指导器来指导角色的动作,并采用了一种有效的时间建模方法,确保视频帧之间的平滑过渡。
论文地址:
arxiv.org/pdf/2311.17117

8、昆仑万维发布Agent开发平台天工SkyAgents
据昆仑万维集团微信公众号发文,今日,昆仑万维正式发布天工SkyAgents平台。据介绍,天工SkyAgents是国内领先的AI Agent开发平台,基于昆仑万维天工大模型打造,具备从感知到决策,从决策到执行的自主学习和独立思考能力。用户可以通过自然语言构建自己的单个或多个“私人助理”,并将不同任务模块化,通过操作系统模块的方式,实现执行包括问题预设、指定回复、知识库创建与检索、意图识别、文本提取、http请求等任务。对于企业用户而言,天工SkyAgents则可以按需拼装成企业IT、智能客服、企业培训、HR、法律顾问等众多个性化的应用,并支持一键服务部署,确保其在不同业务系统中的无缝接入。
内测申请地址:agentspro.cn
9、出门问问奇妙元推出奇妙助手功能
据出门问问微信公众号发文,昨日,出门问问旗下AI数字人视频创作平台奇妙元全面升级,推出奇妙助手功能。据介绍,奇妙助手能快速生成制作视频所需要的素材,为短视频生成高质量图片,内置8种风格、3种尺寸比例;基于大模型能力智能生成文本,内置中英双语和多种语言情绪;上传PPT一键生成讲解视频,搭载智能解析,重点提炼;一站式生成数字人视频,提供海量模板素材;一键提取视频台词,支持在线视频链接和本地视频上传,准确率达99%;数字人商店上新33+形象,模板商店上新海量剪辑模板素材。
10、腾讯牵头制定全球首个金融风控大模型国际标准
据腾讯云智能微信公众号发文,昨日,IEEE金融风控大模型标准启动会在深圳召开。该标准由腾讯主导发起,是全球范围内首个金融风险控制领域的大模型国际标准,旨在为金融机构风控建模环节中应用AI大模型技术提供参考和指引,使金融机构能够在日益复杂和数据驱动的金融环境中高效预测、衡量和管理业务风险。该标准适用于金融零售信贷场景的风险控制管理,帮助金融机构在运用AI技术生成金融风控大模型的过程中提供参考,包括应用场景、基本条件、模型创建以及迭代等环节。启动会现场明确了标准的研制方案,并计划于明年9月正式发布。
11、山东:瞄准AI等七大未来产业 大力推进AI+
据工信微报报道,昨日上午,山东省新型工业化推进大会在济南召开。山东省委书记林武强调,要扎实做好新型工业化各项工作,全面加快新型工业化进程。聚焦高端化发展,在布局未来产业上持续加力,重点瞄准元宇宙、人工智能(AI)、生命科学、未来网络、量子科技、人形机器人、深海空天七大未来产业,加强前瞻性研究布局,建好未来产业先导区。聚焦智能化发展,着力推进数实深度融合。要更大力度促进AI应用,统筹布局通用大模型和垂直大模型,丰富算力资源,培育一批高水平智能技术和产品,大力推进“AI+”。
12、Adobe等推出DMD方法 生图速度提升30倍
今日,Adobe和麻省理工学院的研究人员共同发布论文,介绍一种分布匹配蒸馏(Distribution Matching Distillation,DMD)方法,可在速度提升30倍的情况下生成与Stable Diffusion v1.5相当的图像质量。论文的核心思想是训练两个扩散模型,不仅估计目标真实分布的评分函数,还估计伪造分布的评分函数。方法类似于生成对抗网络(GANs),即通过同时训练评论家和生成器来最小化真实分布和伪造分布之间的差异,但不同之处在于训练不涉及可能导致不稳定的对抗博弈,并且评论家模型可以充分利用预训练扩散模型的权重。
项目地址:
tianweiy.github.io/dmd
论文地址:
tianweiy.github.io/dmd/dmd_highres.pdf

13、Stable Audio新增支持上传音频生成音乐
今日,AI独角兽Stability AI旗下的音乐生成产品Stable Audio宣布推出一系列新功能,包括支持输入音频来指导生成音乐,增加更多参数来提升创作体验,新增链接分享、视频下载功能,内置风格提示库等。
14、基于大学知识的多模态LLM测评基准MMMU发布
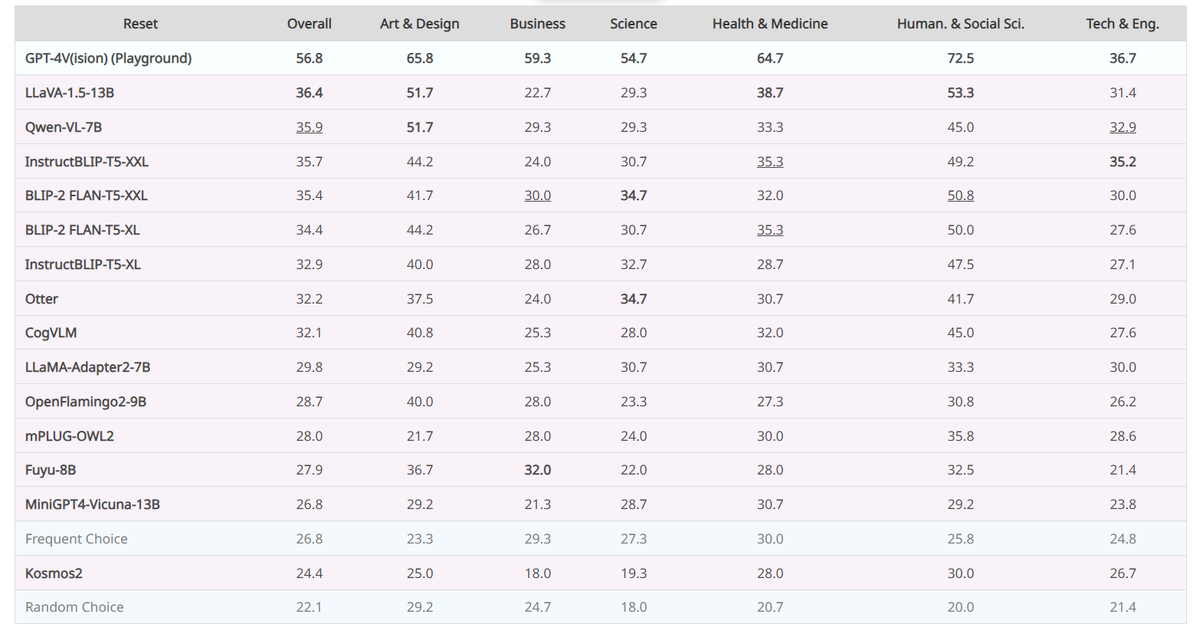
11月29日,据论文作者、美国俄亥俄州立大学(OSU)博士岳翔于社交平台X发文,其与来自7个机构的20多名研究人员共同发表论文,推出了MMMU基准测试。该测试收集了11.5K来自大学考试、测验和教科书的多模态问题,横跨艺术设计、商业、科学、健康与医学、人文社科、技术与工程等30个科目和183个子领域,覆盖图表、图表、地图、表格、乐谱和化学结构等30种异构图像类型,专注于利用特定领域知识进行高级感知和推理。论文测试了14个开源大模型以及GPT-4V,测评显示,即使是先进的GPT-4V也只能达到56%的准确率。论文对GPT-4V的150个错误案例进行的错误分析表明,35%的错误是感性的,29%是由于缺乏知识,26%是由于推理过程中的缺陷。
论文地址:
arxiv.org/abs/2311.16502
项目主页:
mmmu-benchmark.github.io
15、微软未来三年向英国AI基础设施投资225亿元
据路透社今日报道,微软计划在未来三年内向英国投资25亿英镑(约合人民币225亿元),以支持AI的增长,这是该公司迄今在英国的最大单笔投资。投资将用于使微软在英国的数据中心面积增加一倍以上,为新的AI模型提供关键的基础设施。
