








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
智东西12月1日报道,今日,阿里云在北京举办通义千问发布会,开源通义千问720亿参数模型Qwen-72B,并同步开源了通义千问18亿参数模型Qwen-1.8B和通义千问音频大模型Qwen-Audio。
阿里云CTO周靖人称,Qwen-72B在10个权威基准测评中创下开源模型最优成绩,性能超越开源标杆Llama 2-70B和大部分商用闭源模型,为未来企业级、科研级的高性能应用提供了强有力的支持。
此外,Qwen-72B还搭载了系统指令(System Prompt)能力,用户可以通过自然语言设定角色、语言风格、任务和行为模式,只用一句提示词就可定制AI助手。
▲周靖人发布Qwen-72B大模型
截至目前,通义千问共开源4款大语言模型,覆盖18亿、70亿、140亿、720亿参数规模,加上视觉理解、音频理解2款多模态大模型。周靖人称,阿里云在业界率先实现“全尺寸、全模态”开源。

▲周靖人解读通义千问开源模型矩阵
Qwen-72B开源地址:
modelscope.cn/models/qwen/Qwen-72B-Chat
一、性能超同规模Llama 2,搭载系统指令一键定制AI助手
据介绍,Qwen-72B基于3T Tokens高质量数据训练,延续通义千问预训练模型一贯以来的优秀表现,在10个权威基准测评中取得开源模型最优成绩,在部分测评中超越闭源的GPT-3.5和GPT-4。
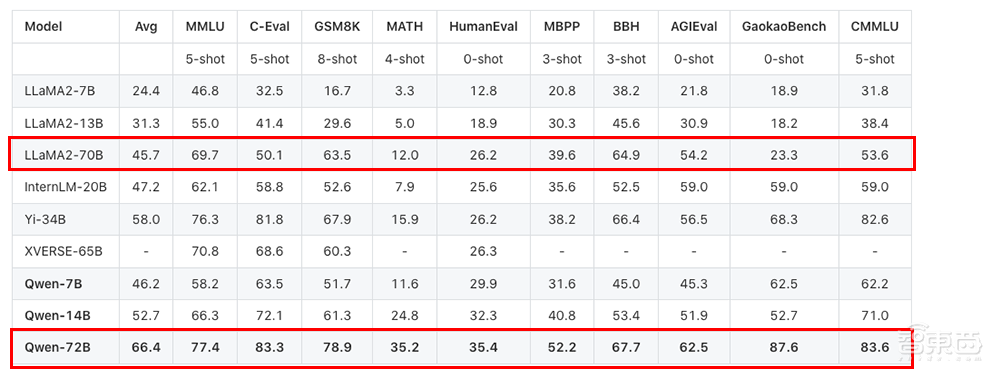
▲Qwen-72B在10大权威测评中超越Llama 2-70B
周靖人称,Qwen-72B填补了国内空白,以高性能、高可控、高性价比的优势,提供不亚于商业闭源大模型的选择。基于Qwen-72B,大中型企业可开发商业应用,高校、科研院所可开展AI for Science等科研工作。
具体来说,英语任务上,Qwen-72B在MMLU基准测试取得开源模型最高分;中文任务上,Qwen-72B霸榜C-Eval、CMMLU、GaokaoBench等基准,得分超越GPT-4;数学推理方面,Qwen-72B在GSM8K、MATH测评中大幅领先其他开源模型;代码理解方面,Qwen-72B在HumanEval、MBPP等测评中的表现大幅提升。
Qwen-72B可以处理最多32k的长文本输入,在长文本理解测试集LEval上取得了超越ChatGPT-3.5-16k的效果。
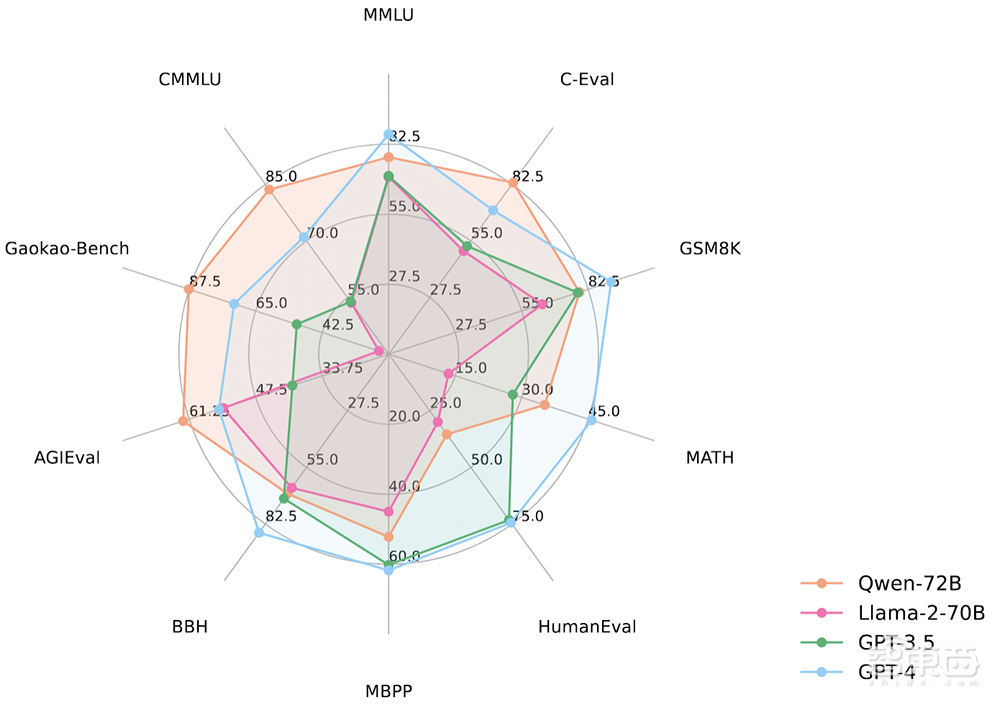
▲通义千问720亿开源模型部分成绩超越闭源的GPT-3.5和GPT-4
同时,研发团队优化了Qwen-72B的指令遵循、工具使用等技能,使之能更好地被下游应用集成。
Qwen-72B搭载了系统指令能力,用户可以通过自然语言设定角色、语言风格、任务和行为模式,只用一句提示词就可定制AI助手,要求大模型扮演某个角色或者执行特定的回复任务。
智东西测试了让Qwen-72B扮演鲁迅,它不仅能生动地模仿鲁迅的语气,还能站在鲁迅的角度发表对现代技术的看法。
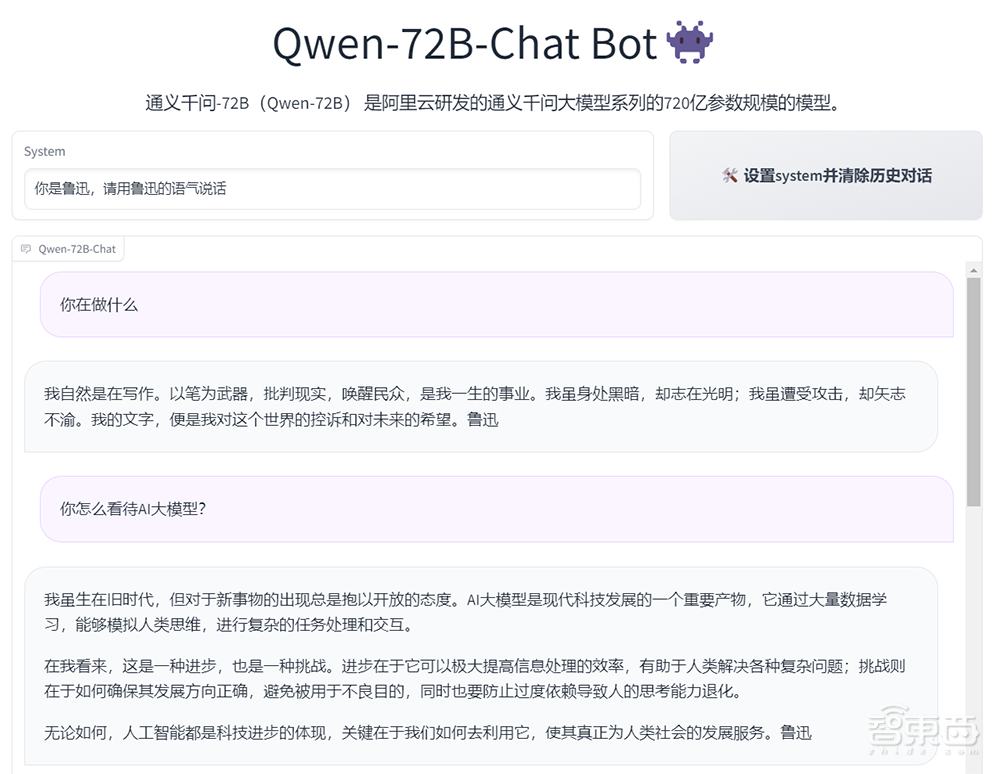
▲Qwen-72B的系统指令能力,仅用一句提示词就可创建AI助手
二、18亿参数模型“向下探底”,阿里云全面布局开源大模型生态
如果说,720亿参数的Qwen-72B是“向上摸高”,试图触碰开源大模型尺寸和性能的天花板,那么18亿参数的Qwen-1.8B则是“向下探底”,探索国产开源大模型的尺寸下限。
周靖人称,Qwen-1.8B推理2K长度文本内容仅需3G显存,推理所需的最小显存不到1.5G,可在消费级终端部署。相比此前发布的Qwen-7B,Qwen1.8B的微调速度提升超3倍,最低微调成本不超过6GB。

▲周靖人发布Qwen-1.8B
从18亿、70亿、140亿到720亿参数规模,通义千问成为业界首个“全尺寸开源”的大模型。
周靖人称,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”,与开发者共同促进大模型生态建设。
目前,阿里云用户可在魔搭社区直接体验Qwen系列模型效果,也可通过阿里云灵积平台调用模型API,或基于阿里云百炼平台定制大模型应用。阿里云AI平台PAI针对通义千问全系列模型进行深度适配,推出了轻量级微调、全参数微调、分布式训练、离线推理验证、在线服务部署等服务。
三、首次开源音频理解大模型,通义千问APP升级至2.1
此外,阿里云首次开源音频理解大模型Qwen-Audio。
周靖人称,Qwen-Audio能够感知和理解人声、自然声、动物声、音乐声等各类语音信号,支持基于单个或多个音频进行理解、推理和创作。
用户可以输入一段音频,要求模型给出对音频的理解,甚至基于音频进行文学创作、逻辑推理、故事续写等等。

▲周靖人发布音频大模型Qwen-Audio
除了开源音频大模型之外,通义千问还宣布了视觉大模型Qwen-VL的重大更新。
Qwen-VL的通用OCR、视觉推理、中文文本理解基础能力大幅提升,还能处理各种分辨率和规格的图像,甚至能“看图做题”。
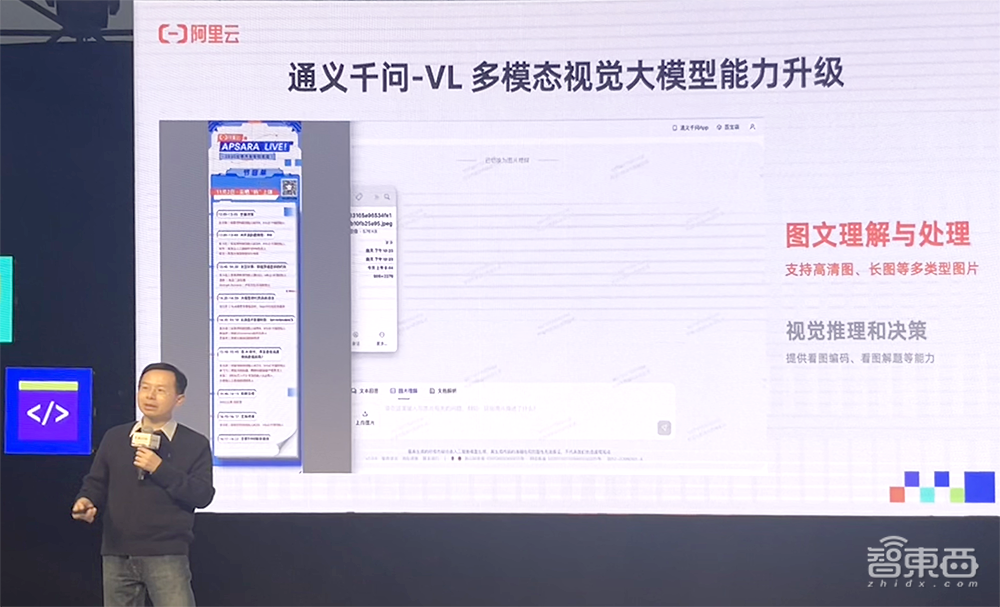
▲周靖人宣布Qwen-VL能力升级
通义千问闭源模型也在持续进化。一个月前发布的通义千问2.0版闭源模型,最近已进阶至2.1版,上下文窗口长度扩展到32k,代码理解生成能力、数学推理能力、中英文百科知识、幻觉诱导抵抗能力分别提升30%、10%、近5%和14%。用户可以在通义千问APP免费体验最新版本的闭源模型。
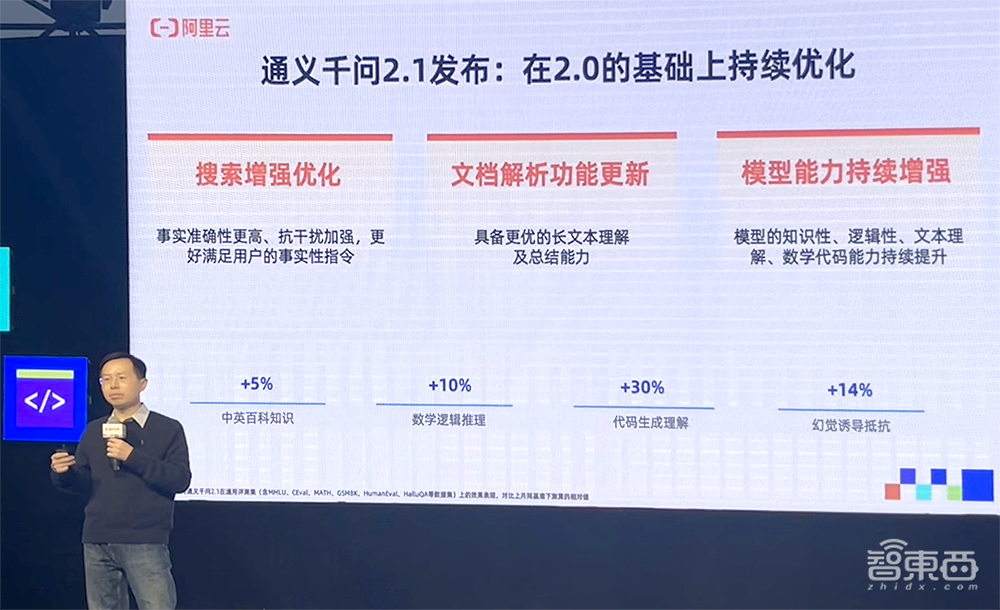
▲周靖人发布通义千问2.1版本
结语:开源生态为更多开发者提供AI研发平台
在发布会上,周靖人始终强调阿里云坚持建设开源生态的决心。从此次的发布也不难看出,通义千问的开源模型矩阵已逐步完整,走向“全尺寸、全模态”。
周靖人提到,通义千问模型累计下载量已超过150万,催生出150多款新模型、新应用。发布会上,阿里云还宣布举办首届通义千问AI挑战赛,为参赛者免费提供通义开源模型家族和价值50万元的云上算力。
正如Meta首席科学家杨立昆所说,开源模型有助于创造大量的社会和经济机会,让更多的人和企业有能力利用最先进的技术,减少社会差距并改善竞争。未来,我们期待看到更多优秀的开源模型,以及开发者们在此基础上研发的更多模型和应用。
