








芯东西(公众号:aichip001)
编辑 | GACS
芯东西10月7日报道,9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在次日高效能AI芯片芯片专场上,九天睿芯副总裁袁野分享了主题为《基于6T SRAM的混合存内计算架构处理器加速多样化应用落地》的主题演讲。
袁野在演讲中介绍了AIGC和存内计算与高速互联的技术。对于AIGC,他强调了它是人类的助手而不是取代工作,指出了基于ChatGPT的应用领域和未来的发展趋势。同时,他讲到存内计算技术,包括模式混合架构和纯数字架构各自的优势。
袁野还介绍了九天睿芯开发的ADA系列芯片,针对传感器侧、SoC侧大算力需求的定位。并且列举了一些应用机会,如星光级夜视和个人智能终端。
以下为袁野的演讲实录:
非常高兴能来参加这次活动,大概给大家讲一下我们现在的一些情况,也给大家分享一下我们所畅想的一些未来。分成四个部分,第一个讲讲AIGC,第二个讲讲我们存内计算与高速互联的技术。因为在突破大算力瓶颈上,除了本身的存内计算技术是最底层的解决互联问题以外,中间相互之间的互联也是非常重要的一个板块。
第一个板块是AIGC。ChatGPT刚出来的时候,很多人在说基于这个生态可能会取代很多工作,但是在我看来AIGC一直是人类的助手,所以不要太过于把它看成一个猛虎,而是要把它看成一个伙伴,一个绝对非常好用的辅助工具跟助手。
我一直在用ChatGPT,在使用过程中发现它有自身的缺陷,包括它本身是一个逐字推理的模型,所以效率肯定不会特别高。第二,它脑洞确实比较小,因为受本身内部逻辑的限制。还有它在时空域的联想会比较差,如果前天问了它一个问题今天再去问,同一个人对它问的问题,但是得出来的结果是不一样的。
ChatGPT是一个通用大模型,当它真正做到个人模型后就可以解决相关的问题,所以真正的通用大模型未来到垂直落地场景、到个人大模型,我觉得是大趋势。
大模型可以应用的点,像教育、客服、助手、NPC这些都非常多。我是一个游戏爱好者,也是一个小说爱好者,所以网络上脑洞大开的写游戏的虚拟小说,我觉得写得非常好。通过ChatGPT和现在大算力的发展,包括存内计算的发展,那种游戏的落地在未来已经不远了。这对我个人来说是一件非常值得兴奋的事情,在我有生之年能够完善这样的游戏我就圆满了。
一、基于纯数字架构SRAM存内计算,ADA系列芯片能效、面效双提升
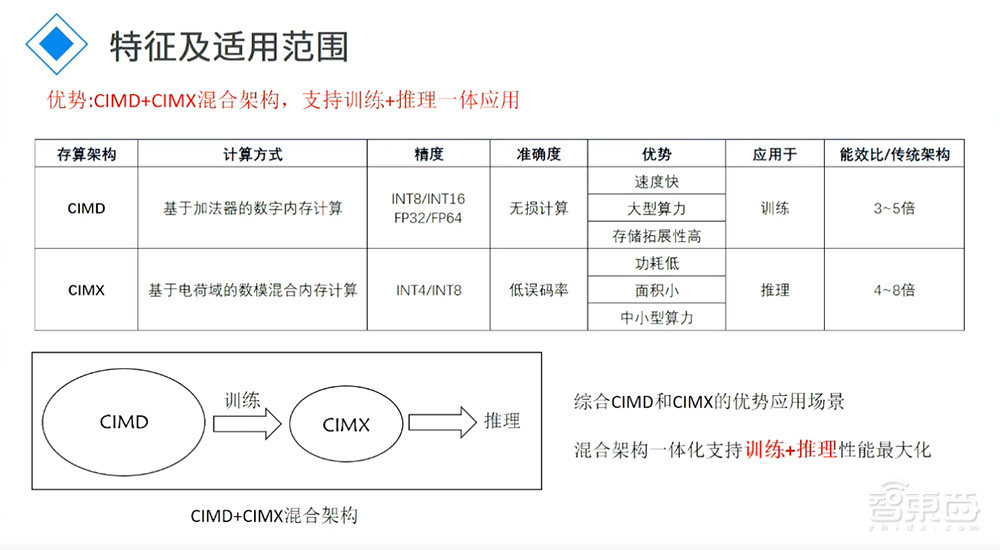
基于我们本身的存内计算给大家讲一讲。初期我们是做模式混合架构存内计算的芯片,后面同步延展了基于纯数字架构SRAM的存内计算的芯片。现在第二代ADA200芯片能效跟面效比已经非常明显了,能效比做到20TOPS/W,面效是做到10TOPS/平方,比现有纯数字架构的MPU有非常大的优势。

另外,基于数字板块架构的SRAM存内计算也在设计当中。
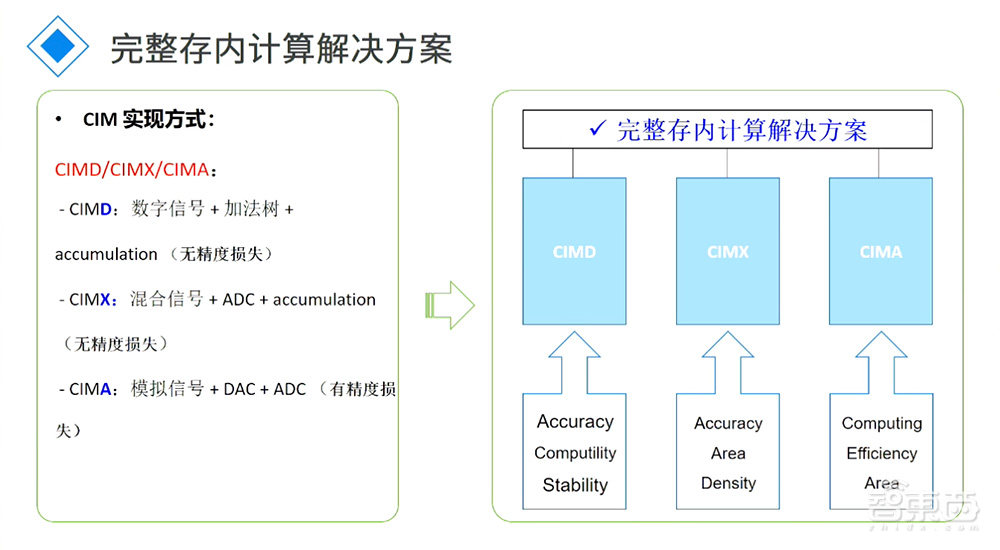
为什么还去做一个纯数字的?因为模式混合的架构在支持INT8、INT4、INT2这样有效精度计算时候是非常好的,但是在做更高精度的比如16甚至32精度计算的时候表现就没有那么好。所以做了纯数字架构SRAM的东西以后,纯数字的可以做更高精度的计算,模式混合的可以做低精度的计算。整个芯片做好融合以后,在推理跟训练的时候都可以用到,这就类似于GPU的核心功能。
这是我们一个完整的实现方式,数字的就是数字信号+加法树+无精度损失,好处是无精度损失。模式混合的架构的好处是在面效跟能效上表现上会更高,但是会有一定精度损失。现在我们自己测试下来,精度损失差不多在百万分之二,在大模型或者大量AI运算上基本是可以忽略不计的损失。
另外一种方式是CIMA,用纯模拟的架构做,它更好的支持类似于INT4、INT2更低精度的运算。在未来大模型量化过后,CIMA也是很好的方向。我们跟很多做AIGC的大厂、做大模型大厂沟通的时候,他们现在还是基于INT8、INT16级别在做。往更低层次的量化,他们有在研究但是还没有做。
我们也得到了其它的消息,现在AIGC算法或者大模型的算法未来会往什么方向走还是不定性的,而且国内的牌照未来可能还会重新洗牌,到底哪些厂商有资格去做大模型现在还没有定论。
所以在做这个芯片的时候,无论是选择CIMD还是CIMX架构,我们更多思考的是怎么把底层对Transformer一些算子的支持、把互联做好,而不是现在就去做一颗SoC。如果现阶段就去做SoC,可能在某个阶段等真真正正大模型定下来以后到底适不适用,还是一个非常大的问题。现在更多的精力是跟很多的大厂做沟通或者基于存内计算定制开发的合作。这里讲了CIMD、CIMX的优势。
我们定位的几个事情:第一,针对传感器侧,已经量产的ADA100芯片系列是完全针对传感器侧AI的运算。AI的东西应该是无处不在的,从最初的传感器端开始就可以带一定的AI处理,帮助压缩传到后端的数据量或者是更准确的数据传到后端的核心功能,所以第一代芯片中非常小算力的部分主要是针对边缘侧传感器的AI。
ADA200系列差不多4T左右,而且4T-20T范围内的AI芯片就是针对SoC侧的算力补充。SoC侧的算力想覆盖所有应用是非常难的,现在很多产品对AI需求会越来越大,但是SoC要重新设计或者做更大的NPU难度是非常大的。我们就去做了这样的NPU来帮助做算力支撑,算是SoC侧的一个协处理器。ADA300更多是针对更大算力需求,比如100T-1000T范围的算力支撑,我们也是针对算力支撑而没有做完整的SoC。
为什么做这样的东西,或者ADA300为什么做呢?跟国内做笔电、手机大厂沟通的时候发现,他们想把AIGC直接落地在平板、电脑上,形成个人的AI智能终端。这样的AI智能终端对算力的需求很大,而且对功耗方面的要求很高,所以存内计算在这个阶段可以发挥非常好的作用,这是我们为什么要做这个产品的原因,待会儿有具体的应用跟大家分享。
二、高速互联接口,打通CPU、算力、存储的次级搬运墙
我们公司2018年成立,中间有做了两代、三代存内计算,今年开始做互联。为什么做互联?存内计算所形成的算力芯片并不大,单个存内计算芯片算力基本上是堆到4T,再往上走是通过互联通过叠加的形式实现更大算力的模式,所以互联在整个AI或者存内计算中起到的作用是非常核心的,这是我们为什么做互联的原因。
在芯片内部或者芯片外部,互联技术已经非常多了,基本上是把整个行业做了一个串联,从最初传感器到端侧的SoC,通过低速接口做连接。
SoC内部CPU、GPU之间的互相通信也是有自己的通信技术。存储跟CPU之间的通信不用说,SATA是最早的,但是现在PCIe的东西越来越多,特别是服务器级类似这样的芯片越来越多。存储又跟传输中心、算力中心互连,中间有非常多的互连技术。典型代表,现在比较火的类似于英特尔提的CXL,基于PCIe5、PCIe6、NVlink这样一些互连技术,包括上面总线内部的互联就是我们现在所做的核心,一切是为了实现大算力做准备。
我们自定义的技术就不详细讲了。一个是片内的,一个是片间的。这两块互联技术本身是围绕未来大算力需求或者是中算力需求而去做准备的。

三、算法+系统+底层硬件支持,AI技术升级加速应用落地
最后我想说的是迎接智能时代。
英伟达不用说了,它本身的生态搭建得很完整。新一代应对于推理侧的芯片也出来了,而且它跟很多行业内大厂已经开始向做下一代个人智能终端设备的趋势走了。他们最早也是做协处理器,英伟达最早是做游戏显卡起家,但是到下一代智能PC阶段,基本上超过英特尔成为主控了,英特尔CPU反而可以说是一个协处理器、控制器的概念。我们还是很看好AI的未来,希望顺着这条路走出国内的发展。
我列举了一些应用的机会,现在可以看到无论是手机、PC还是智能终端的设备,有越来越多AI升级的机会,所以最终会带来新的终端设备、新的行业设备、新的芯片架构包括整个新的生态逻辑,是非常庞大的一个新的市场。在座的各位如果还有心思,可以仔细想一想在中间能够找到什么样的机会。
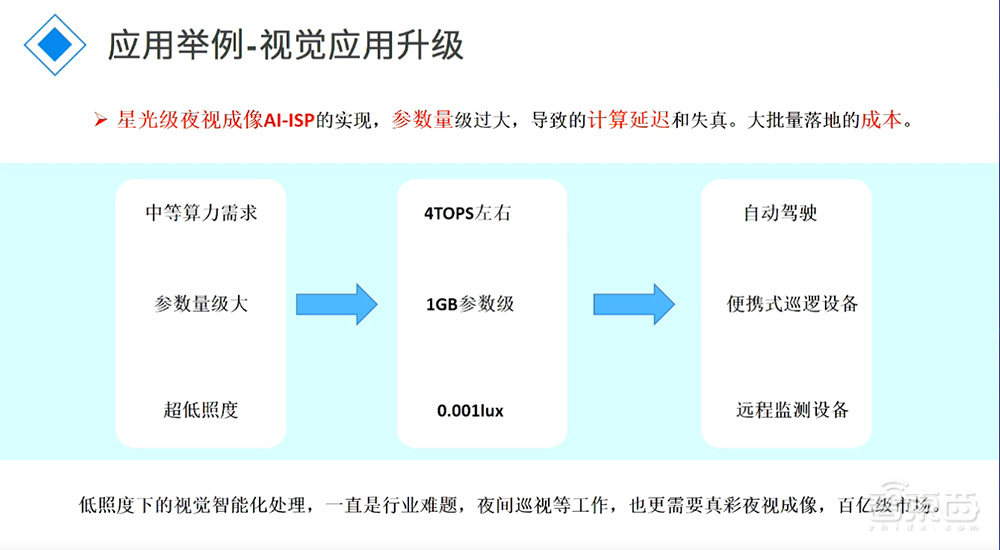
这边列举了一些应用。第一个,星光级夜视。这是我朋友公司做的技术,他们可以在只有0.001lux的前提下做到真彩成像,这是非常牛的一个技术。它的算力是不高,但参数量非常大,怎么样把它量化、跑起来是非常难的事情,所以现在用传统的SoC跑延时就非常严重,而且成像效果并不佳。他的想法是基于存内可不可以把这个东西做得更好?这是存内的应用点,类似这样的算法在未来会越来越多。怎么支持这样的算法把AI落地得更好?这是我们要做的事情。
第二个,个人智能终端,这是畅想型的东西。所有ChatGPT或者AIGC的东西越来越成熟后,我们想把这些AI算力布置到各个终端上,包括手持式终端、便携式终端,最终形成的是真正的自动化助手。其中的生意机会也非常多。
总的来说,我们公司是提供支撑算力平台的公司,我们想把它从传感器侧、到SOC侧、到未来个人平台侧一些算力做更好的支撑,感谢大家!
以上是袁野演讲内容的完整整理。
