








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在首日的AI芯片架构创新专场上,珠海芯动力创始人及首席执行官李原分享了主题为《RPP芯片架构给AI芯片带来的发展前景及机遇》的主题演讲。
李原在演讲中介绍了珠海市芯动力科技的背景和研发原因,提出并行计算有很大爆发区间。他对芯片效率进行了定义并提出计算方式:算法复杂度÷处理器核心复杂度,同时讲出芯片中通用性与效率的平衡问题、人工智能的发展历程,以及CUDA语言在并行计算中的应用。
李原还通过动画演示了RPP架构的芯片设计与实现过程,包括数据流处理方式、环状结构和内部SRAM的优化等。RPP架构具备全方位兼容CUDA的特性,意味着开发者可以直接使用CUDA编程语言编写程序,无需进行复杂的代码转换。目前,芯动力首款基于可重构架构的GPGPU芯片RPP-R8已经流片成功,实现小规模量产。未来,珠海市芯动力科技可能采用Chiplet和I/O die连接的方式开发下一代产品。
以下为李原的演讲实录:
各位嘉宾好,各位老师好,非常感谢有机会跟大家分享,今天我看到了很多可重构的主题,我们也正好是做可重构架构的公司,也分享一下在我们研发过程中看到了什么事情。
我们是珠海市芯动力科技,2017年就回到了中国,开始研发新的芯片,我们称之为RPP。我们开发的原因,是在2011年开始就看到了有巨大的并行计算的前景,其实并不是和AI有什么关系,而是看到并行计算将来是很大的爆发区间。
譬如,英伟达这家公司的市值之前比英特尔低了很多,大家都知道最近英伟达的市值远远超过了英特尔,以前是英特尔雄踞榜首多年。我们认为这个趋势表示了并行计算对市场的巨大需求,市场也认可并行计算的巨大空间。
当时在2011年看到的是什么呢?如果把数字芯片做一下分类,起码有通用性、性能两个维度进行分类。CPU、GPU是比较通用性的芯片,它们是一类做处理器的工程师来主导的方向。我们以前在做通讯行业,做的主要方向是ASIC,也用不少FPGA,这种专用芯片占了很大的市场。
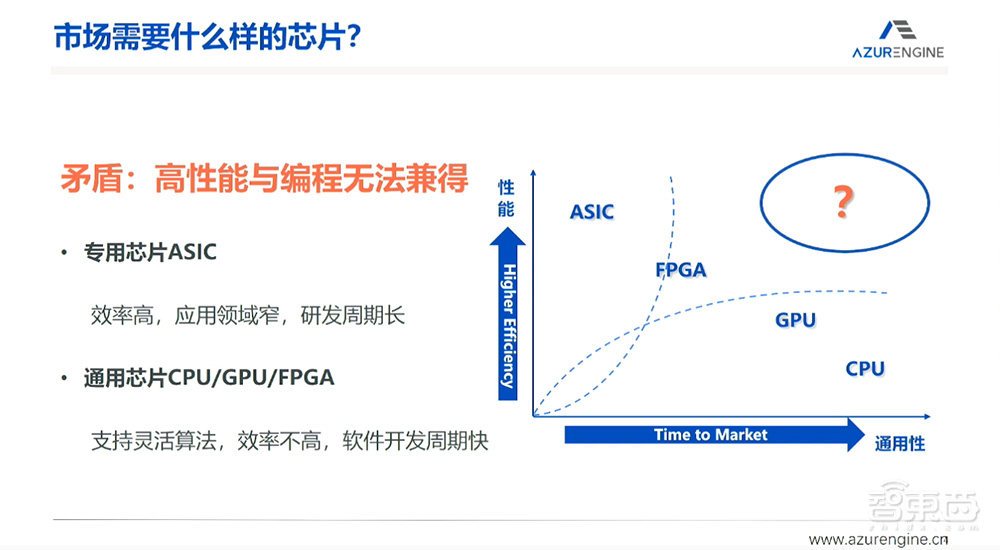
但我们看到一个很大的空白区间,也就是可通用性的软件,还有性能非常高的芯片、专用芯片的性能,是否有可能成为同时存在的一种架构。这种芯片在2011年左右是不曾存在的,我们认为,如果有这样的芯片存在,市场需求肯定是巨大的。
一、什么是最优电路设计?给计算效率制定评估标准
首先当时必须要知道什么是芯片的效率。以前谈论了很多,有各种各样的说法,比如芯片的功耗是多少、芯片的面积里面放了多少、能计算多少东西等等,实际上都很不量化。但去给它一个比较严格的量化定义的时候,我们才有可能评估什么是芯片的效率。
对于一个应用,可以把它分解成各种各样的指令,在最基本的指令完成整个计算的时候,它所消耗的晶体管的数量,还有所消耗的时间,就是它的资源。可以对这个算法的复杂度去进行这样比较量化的定义。
处理器有一个核心,它是一种计算的方式,完成这个算法,使用了多少晶体管,再乘耗费的周期数,就是处理器的复杂度。这两个东西如果进行相比,就可以得到大约的芯片的面积效率,芯片面积效率和芯片的功耗效率是息息相关的。
简单地说,因为在这个场合我们也没有必要推理一个比较复杂的数学公式,大约是计算单元占处理器核心面积的百分比。

举几个例子来看,去评比一下各种各样的处理器,比如说GPU、CPU、DSP、FPGA,甚至ASIC都可以比较,它们的效率很不一样。
比如这是NVIDIA Jetson Xavier这个芯片,用台积电12纳米,GPU的面积大概是90平方毫米,大概能够算出来是占了760M Gates,如果做INT8矩阵计算,它相当于12.8M Gates的矩阵计算。这样算一下可以很容易得出来计算效率并不高。这是比较先进的架构了,但实际上只有这个GPU的芯片面积的1.6%用于真正的整数计算,效率是不太高的。
再看一下2016年谷歌提出来的TPU,当时是28纳米,矩阵计算Unit、Accumulation Unit、Activation Unit这三个部分都是参与计算的,其他部分都是辅助单元。把这部分面积算出来,相当于397M Gates,能够操作的INT8 MAC数量64k,换算出来它的面积效率的确比较高,是21%。其实我们用同样的方法,CPU、FPGA、DSP、ASIC都可以算出来。
二、芯片通用性,重在成本与生态
ASIC是效率很高的东西,我们以前都是做ASIC的,可以做到尽量让它接近百分之百,但是通用性同时又损失了。如果说我们要达到通用性,同时也要达到高的效率的时候,应该怎么做?
首先要回答什么是通用性。
我认为通用性没有一个量化的回答,但是我在英特尔工作的时候得到一个教诲。英特尔做的工作是什么呢?给客户带来的价值就是Time-to-Market(产品上市速度),在客户使用它的时候能多快进入市场,它是为客户节省时间的,这是英特尔内部成功的定义。

英特尔、Arm都是非常典型的成功的CPU公司,是通用计算公司,他们使用通用的编程语言而且一代代可以复用,使得客户在这里面长期的投资可以得到保存。
英伟达也是,英伟达使用GPU,开放了CUDA语言以后很多客户在这方面积累了很多的开源代码,也有客户自己写的代码。英伟达开发了非常多的计算库,使得客户非常好地使用起来,这也是英伟达在GPU领域能够得到非常多客户的原因。
但包含德州仪器、ADI等公司在内,现在都几乎停止了DSP的研发,DSP也算是比较有方向感的处理器,但因为DSP由于过分地追求效率,暴露了很多汇编语言,客户使用汇编语言的时候就不方便,而且一代代更新的时候,汇编语言就不能继承,所以失去了市场,代码也不能复用。
ASIC更加糟糕,往往ASIC在开发的时候就把应用程序写到这里面去,比如NPU在作为计算的时候,ASIC可以认为只是做矩阵计算、卷积计算,其实在生态上还是难以形成。
我们认为AI是并行计算的代表,看它是怎么发展的。1950年左右,图灵发表论文思考机器出现,1970年机器推理系统出现,1980年专家系统出现,1990年神经网络出现,2010年深度学习出现,2017年Transformer提出,2023年AIGC出现。从这些变化可以看到,从最初到现在,它的算法程序都在不停地变化。
CUDA语言是通用并行计算语言,基本成为了行业的标准。从2016年,我们是第一家除了英伟达以外的公司,首次采用CUDA语言作为芯片架构的设计方向。英伟达的CUDA语言是非常成熟的,它不停地在研发前进的同时也开创了很多的市场。目前主流的计算平台都是以CUDA语言来进行开发的。
另外一个方向,要看一下芯片的发展规律。在座的各位都是这方面的专家,但是随着摩尔定律的增加,工艺不停地进步,复杂度不停地提升,设计的复杂度也提升,使得计算能力在提升的同时,带来的问题也很明显,关键就是成本。
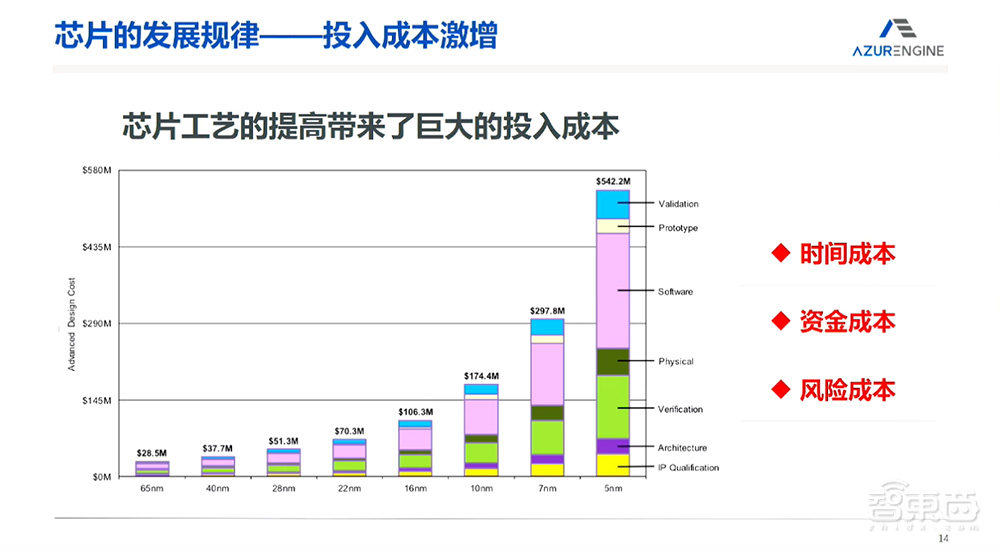
我第一次做芯片设计的时候还是90纳米的芯片,后来65纳米、40纳米、28纳米,到现在为止7纳米、5纳米,甚至要出现3纳米的芯片。但是它的趋势实际上是成本飞速的增长。有几个公司能够支持得了7纳米、5纳米?这个飞速增长带来的是不变的规律,就是在芯片行业数字电路随着纳米数的推进,时间成本、资金成本、风险成本都是非常非常高的。它需要我们解决的矛盾,就是芯片技术飞速发展和特别长、特别大的资金的投入,以及特别大的风险之间的矛盾。
现在市场接受的是什么?绝大部分市场接受的东西还是CPU+GPU,是不是它的功耗比最高呢?不是。它的计算能力是不是最高呢?也不是,但是它现在变成了最被接受的主流平台。原因大家都知道,它的生态起到了非常重要的作用。
三、基于自研RPP架构,打造“六边形战士”处理器
我介绍一下芯动力在并行计算上面的研发历史和我们现在做到的成绩。
从芯动力最早的研发开始,我自己在博士期间做的东西就是专用的芯片,当时在Turbo译码器出现的时候,我就研发高度并行的Turbo译码器;2008年我们做了第一家初创公司,做通用的卫星通讯算法的芯片,这也是高度并行的计算;后来Turbo译码器商用成功以后,被英特尔收购,进入了英特尔的服务器;之后又做出来了基站,也是一个高度并行的计算,其实是软件化的一颗非常高度并行计算的芯片。
2011年第一家公司被并入英特尔之后,我们就提出来了计算效率的定义,开始并行计算的探索,刚开始从CGRA开始,也就是粗粒度可重构阵列开始的。我们知道语言对于一个芯片是至关重要的时候,就提出来使用CUDA语言重新构造一个并行计算芯片,这时候提出了“RPP”的概念,这也是一个数据流的方式。
在那之后,对于compiler(编译器)的研究变成非常重要的事情。后来在工作中才发现,在这个架构中,寄存器和并行处理器里面的连线是同一个意思。由于这一点,我们攻克了编译器的难关,直接达到了能够使用CUDA编译器,之后逐渐把这个芯片得到应用,现在已经在好几个领域得到了应用,已经开始小批量出货了。
我们大概讲一下技术环节。首先从最基本的概念来讲,什么是计算?就是用指令和数据来形成的图,举一个很小的计算例子,ABCDEFG,他们之间计算的输出就是连线,连线在一个传统的计算机里面就是寄存器,指令算出来的结果给了计存器,计存器再给下一个指令做计算,也就是时间轴的处理器。这样的处理器很重要的标志就是现在正在做哪一个指令。这个是司空见惯的,CPU、GPU、DSP都属于同一种处理方式。
当有并行计算的时候,并行计算的种类其实很多,我们现在讨论其中的一种,也就是CUDA语言所定义的SIMT的并行计算。多数据、单指令的计算方式现在成为主流,这种方式做的事情跟原来C语言能描述的事情完全一样,只是它的数据很多,英伟达认为它是多线程,所以用SIMT的方式来描述。当然也可以用原来的方式去计算,但这种方式的效率并不高。
什么样的效率更高呢?也就是现在碰到的问题,是不是存在一种在并行计算里面的通用性和性能高度融合的东西?
经过了从2011年到2016年期间五年的研究,我们终于发现这个事情是存在的。我们把这个东西命名为RPP,也就是数据流的处理方式。它使用的是CUDA语言,ASIC可以用CUDA语言来执行这个程序,达到性能和通用性双方的结合,但前提必须是并行计算。
并行计算的特点是什么?比如说在专用芯片里面,NPU性能比较高,但专用性太强,可能难以编程,GPU是一种非常通用的芯片架构,但效率并不高,RPP把两种结合在一起,也就是达到效率很高的同时,通用性也和CUDA语言兼容。
这里用一个动画来演示一下实现方式。指令由SEQ进行解码,解码下来的指令会下发给每一个计算单元,叫PE。当PE接收到指令之后可以驱动数据,把数据进行计算,往下一个指令进行下发。指令排布好以后,就形成一个数据流,这样的数据流是有限的,我们只是使用了CUDA语言定义的所有指令形成了一个数据流,在有限的数据流之中形成一个环状,让它可以无限地延伸,这样的方法可以对于任何的CUDA语言进行数据流的执行方式,直到它把所有指令都做完,就会把数据存回内存里面去。这做到和英伟达CUDA语言的指令集兼容,它只是在空间的执行方式而已。
但为了实现这么大的系统,要把它做成一个后端并不容易,因为它需要跑很高的频率。动画显示了如何在一开始就必须得从后端进行设计,把芯片由后端去设计前端驱动的方式做完。我们有32个PE,这个PE放的位置的排列组合非常多,但数据流的本身可以形成一个环状。
我们又有很多的SRAM来把数据进行适配,比较直接的想法就是形成一个环状,32个PE形成一个环状之后,可以把数据进行很好的连接,但这样带来的问题就是内存的大小被控制在内部不能变。
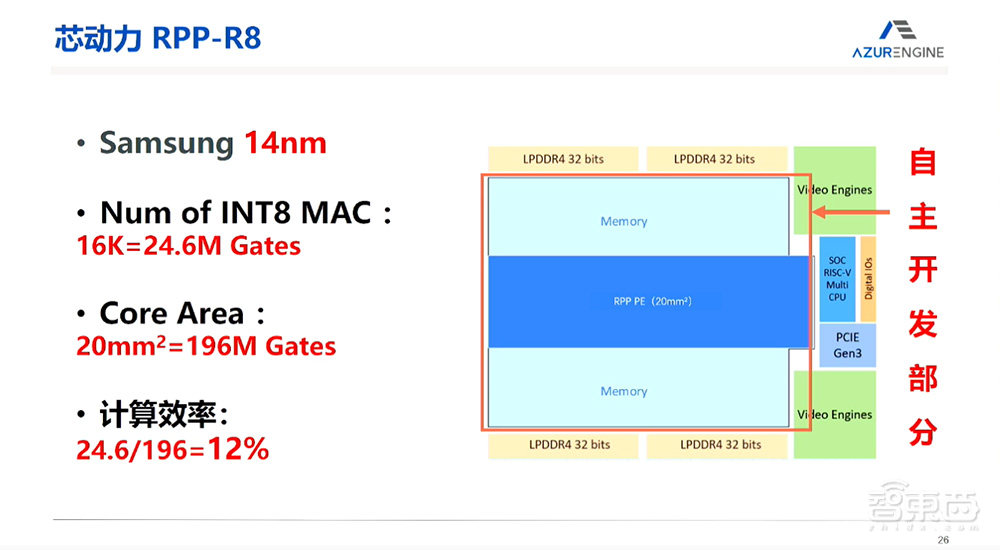
我们后来采取了扁平状的环,使得内存分布在两边,每一个PE可以到达SRAM的任何一点。这样整个空间就由一个非常狭窄的22平方毫米的面积来组成。SRAM起到了一个很大的缓存,大大地减小了由片外DDR内存达不到的功耗效率。这样的设计使得整个面积只有22平方毫米,对GPU来讲提高了大概7倍的芯片利用面积。
把这个芯片制作成功以后,大概是32T INT8算力的芯片,已经流片成功并且进行了商用。我们把这颗芯片也拿回来做芯片效率的回访,芯片效率是12%,也就是说它和TPU相比,第一代TPU只做INT8,我们在这里面还要做浮点,当然效率会低一点,把这几个效率相比之后,可以看到,RPP的芯片效率和TPU的效率比较接近。
还可以看一下功耗效率,由于这个架构已经形成了一条流水线,功耗效率也很高。拿它和A100的7纳米的芯片效率进行比较,可以看到,实测的效率远远超过了7纳米芯片的功耗效率。利用这样的芯片研发技术,完全可以在成熟的14纳米的工艺上,完成一个7纳米A100的等价性能,完全可以做到。
我们也对它进行了软件生态上的研发。CUDA语言作为一个最底层的编程语言,对它进行了最基本的支持,在这之上英伟达还做了很多生态上的库,比如说深度学习的TensorRT,我们做了完全一样的OpenRT,在其它领域FFT、数学库等等,我们都做了一样的支持,这里面的工作比较花时间,因为不是公开的数据集。
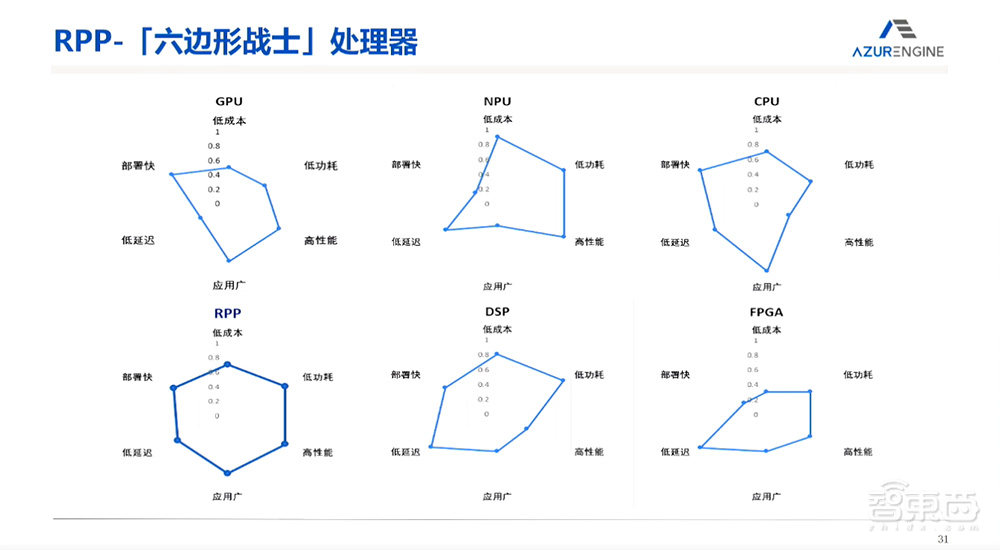
和其他性能之间的比较:RPP是一个综合性能比较均匀的芯片,它部署比较快,因为它是用大家都所接受的CUDA语言来进行编程的;成本比较低,因为它的芯片面积远远小于现在GPU的芯片面积;功耗也远远小于GPU的功耗,性能比同样的GPU更高,应用也非常广泛。所以这个方向上这么多种不同类型的芯片,相比GPU、NPU、CPU等,RPP对并行计算来讲是比较适合的类型。
在应用场景上,我们除了开发了AI,比如泛安防的领域以外,也开发了传统的CUDA语言能涉及的领域,比如信号处理、医疗影像等等,完全是非AI的一些计算。我们已经完全超过了同等的DSP和FPGA的性能,所以在边缘端现在得到了很多客户的认可。
我们非常认同Chiplet带来的价值,在下一代产品会把Chiplet和I/O die进行连接,形成在边缘端更加适合的芯片,类似SOC的解决方案。在算力提升的方向,使用Chiplet的技术把多颗核心进行连接,提供更高的计算能力。我今天的讲解就到这里,谢谢大家!
以上是李原演讲内容的完整整理。
