







智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
智东西9月7日报道,2023Inclusion·外滩大会今日开幕,在下午的“AI前沿技术发展与应用的新浪潮”论坛期间,来自高校、科研单位、科技企业及投资机构的学者专家们齐聚,分别从算法、算力、产业、应用、场景等不同视角,探讨生成式AI和大模型产业现存的挑战与发展趋势。
会后,蚂蚁集团副总裁徐鹏与小冰公司CEO李笛接受智东西等媒体的采访,就大模型及AIGC应用同质化问题、开源与闭源路线的选择、数据及算力稀缺情况等焦点议题进行深入交流。
徐鹏在致辞中谈道,当前,AI大模型技术正高速迭代,新模型、新算法、新应用、新场景正不断涌现,挑战也随之而来,比如算力能耗问题、中文公开数据集语料不足问题、大模型应用安全问题,解决这些问题,需要产学研各界力量协同创新。技术的公平普惠性也要关注,无论是大型还是中小企业,都能借助AI大模型技术提升企业智能化水平,为用户带来更好的服务和体验。
一、大模型雷同问题严重,应用创新才能实现大发展
关于大模型同质化问题,李笛和徐鹏都认为,从应用入手,可以做出非常多不一样的东西。
在论坛圆桌环节,李笛谈道,自己最大的忧虑是国内大模型的多样性,大家用同样的数据集、同样的训练方法、同样的master,对比同样的对象、类似的方法,多样性确实有很大问题。“现在处于技术百花齐放的状态,应该尝试不同的东西,而不是马上数理化外语卷起来了。”
“我觉得现在行业里面最大的问题其实就是「太雷同了」,大家都沿着同一条路径在往前走,没有多样性,这和创新精神是违背的。”李笛认为,创新不是追赶,而是有自己新的方法,去实现自己的优势。他告诉智东西,大模型首先得追及格,再去尝试多样化、差异化,重复造轮子没有必要,在应用上才能实现大的发展。
徐鹏非常认可李笛的观点,大家都是在追赶,首先要及格,及格后才有机会发展的更好,大模型技术上没有本质的差异,但侧重点不一样,像Llama是做一个通用的开源基础模型,GPT本身是闭源的,主要是做ChatGPT对话能力,达到通用人工智能(AGI),在对齐方面要做的很好、上下文长度做的很长,每个既有雷同的地方,又有自己的特色。
他相信像这样非常基础的底层技术,开源是未来。中国形成自己的大模型开源生态,还需给一定的时间。开源模型给应用创新带来便利,不用从头开始浪费大量的财力去训练基础模型,如果大家都将力量放在应用创新上,应用生态更加繁荣,会反过来推动大模型技术的发展。
据他观察,美国很多公司放弃走基础模型这条路,直接在上面做能够创造附加价值的应用,而应用多样性才能给人类、给社会带来价值。
徐鹏感觉,这一波大模型的能力,还不能做出来真正让人人都能够获益的agent,但可能是可以真正往前推进的方向。至于爆款AIGC应用,在他看来,这是可遇不可求的东西,即便如ChatGPT,也会有一定的审美疲劳,能够持续增长的应用非常少。
在李笛看来,开源模型生态过去已经证明了非常旺盛的生命力,但大模型开源目前为止把整个战场变得更加混乱。至于未来到底是闭源还是开源,取决于在行业中的角色定位,如果做大模型,肯定是闭源,如果是一家云计算公司,要兼容各种模型,开源和闭源都是好的生态。
二、建高质量中文数据集是苦力活,英伟达GPU并非无可取代
大模型不能解决所有的事情,需要组合更多技术、靠整个系统不停帮它弥补。李笛联想到他最钦佩的一家公司任天堂,跟微软和索尼相比,任天堂不是堆最先进的硬件,而是榨干1080P成熟技术的最后一点能力,这很重要。
他认为,数据并不是问题,中文语料如果做了好好清洗,还是可以的。把语料真正挖清楚,清洗得足够好,筛选得足够好,这是苦力活。徐鹏补充说,这个苦力活,谁都逃不开,但是中文本身数据的量级应该是够的。
除了需要更多高质量数据,算力也永远紧缺。
李笛说,算力消耗合不合理,取决于商业模式效果,比如游戏NPC,拿很多算力陪人聊天,游戏挣得钱都被NPC聊没了,算力再多也不合理;如果消耗的算力被用于通过生成式AI得到高附加值的收益,算力消耗则是合理的。
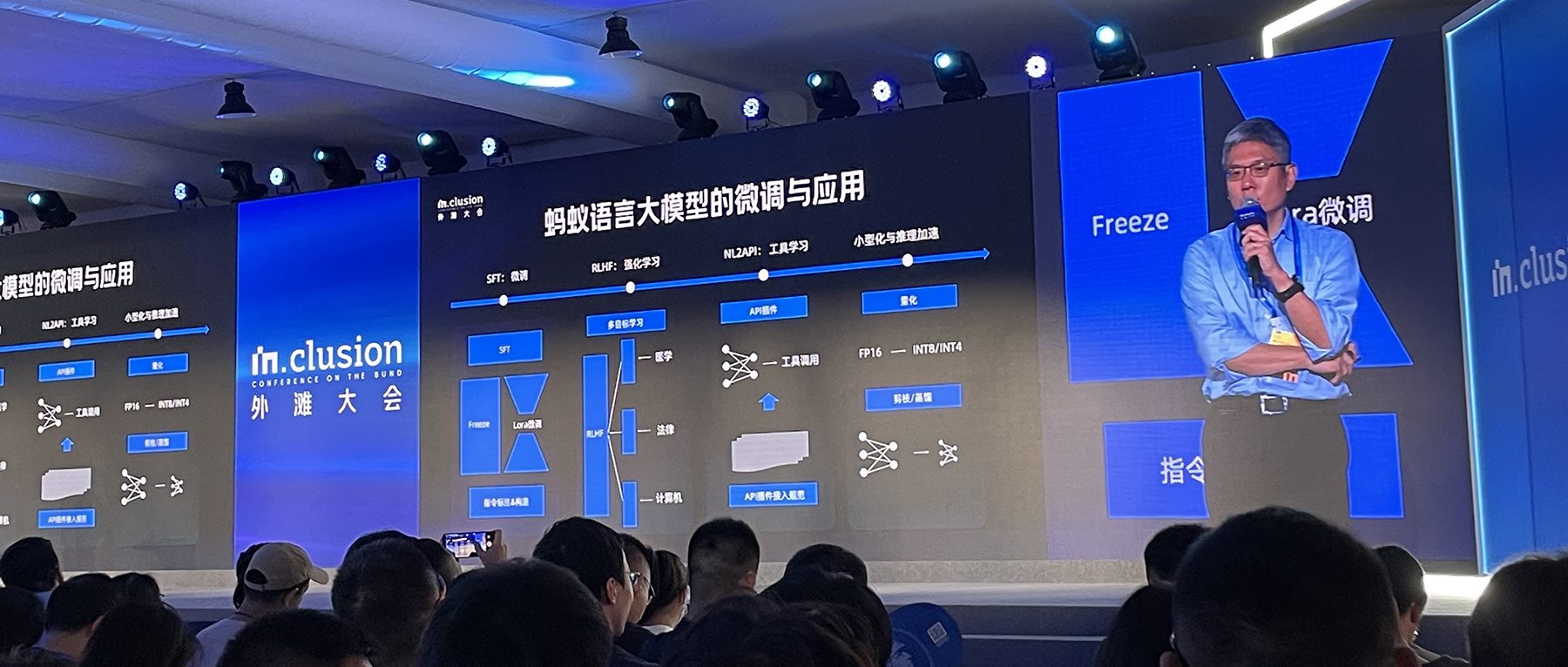
根据徐鹏今日的演讲内容,蚂蚁基础语言大模型采用Transformer架构,使用英伟达GPU、蚂蚁自研的模型架构、高效训练和推理引擎。
作为AI训练芯片的首选,英伟达GPU是当前生成式AI算力红利的大赢家。但徐鹏并不认为英伟达GPU具有非常强的不可替代性,他告诉智东西,这更多是个效率问题,因为英伟达发展的最快、有很强的软件优势、用它的产品效率最高,开箱可用。
应用方采购硬件,有两个因素影响决策买哪些硬件、买多少因素:一是性价比高不高,二是能不能买到。其他公司并不是说没有机会,只是现在还不及英伟达那么成熟,除了硬件本身能力外,还需努力追赶英伟达的软件衔接能力。
李笛相信,恰恰因为大模型太贵了,大家很快会走到一条好的道路上,因为不可能烧钱烧很久,他相信很快就会有变化。
三、从技术信仰转向产品验证,AIGC亟待探索全新商业模式
“很高兴看到整个行业开始进入到了从技术的信仰到产品的验证状态,在未来一年里面的时间,大部分的产品应用会进入到证伪阶段。”李笛在发表演讲时谈道,生成式AI创造的价值与技术所对应的公司实际获得的价值之间存在巨大的鸿沟,这是他看到的当前商业模式最大问题,无论是To C还是To B都应考虑这一问题。
在他看来,目前为止在全球范围内,没有一个成功的AI To C的产品,也没有To B的产品。
过去API调用的商业模式,很大的问题是直接把技术的特点输出了,相当于把科学家手头工作直接怼到客户面前,中间缺少产品化的阶段,也就没有体现出生成式AI的创造力价值。
很多人已经开始探索新的AIGC商业模式。小冰积极尝试Revenue Share的方式,以高附加值作为价值回报的考量依据,李笛认为,大模型创造了一个高附加值的一次交互或一次调用,比期待算力成本下降更加有效,用最贵的GPU、最好的技术都是合理的。
以小冰通过合作帮助动漫工作室打造的生成作品为例,如果按照传统商业模式,游戏厂商总计一次性技术开发收费为几十万人民币,而通过Revenue Share的新方式,3分钟《人和狗》短片上架,小冰获得了15万美元的回报。此外,小冰和网易合作推出了一个新的平台,每一个AI歌手都享有全部生命周期里全部收益的比例,这样的方法才有可能使得真正获得创造力价值。
结语:中国已经有好的高原,接下来一定会产生自己的高峰
李笛强调说,技术发展不是一飞冲天的,都是进入波峰,很多人有创新,又卡住了,突然不知是谁解决了行业难题,大家一起又继续前进。
面对持久的大模型热潮,徐鹏建议要冷静看到它长期能带来什么样的价值、它的能力边界在什么地方,而不是盲目地做太多不切实际的幻想。但又不能离开幻想,因为有幻想才有动力,才有更多的人愿意去做一些看上去不靠谱的事情。
他希望有一定机制去支持有人长期在这个方向做进一步地投入,然后找到核心应用场景,找到它真正能够带来变化的东西,有了这些,就可以反哺AI技术的发展。
这与清华大学计算机科学与技术系副教授刘知远的观点不谋而合。刘知远在今日的圆桌论坛期间谈道,为什么ChatGPT被美国做出来了,中国做不出来?结论是“中国有高原、没高峰”,最原始创新的工作目前仍缺少相应稳定支持的机制,但无论怎样,一切还是在向好的方向发展。
现在百模大战有一些内卷的倾向,但他相信随着内卷不断进行,会变成大家开始寻找差异化的过程,“我们有了这么一个非常好的高原,接下来一定会产生自己的高峰。”刘知远说。
