








AIGC背后,是动辄百亿、千亿参数的AI大模型,
巨大的算力需求如何满足?
这家AI芯片企业,给出了答案——
7月6日,在世界人工智能大会WAIC上,AI芯片企业墨芯人工智能发布了最新的大模型适配成果:墨芯AI计算平台在业内率先支持高达千亿参数的大语言模型,并在吞吐、延时等多项指标上表现优异,创下AI芯片行业的又一里程碑。
在活动现场,墨芯展示了1760亿大模型Bloom在墨芯AI计算平台上的推理效果,成为全场热点。Bloom是与ChatGPT同等参数量级的开源大语言模型。在墨芯AI计算平台高吞吐、低延时的强大算力支持下,Bloom能够快速完成问答、创作等语言类生成任务,赢得现场观众的关注与好评。

在千亿参数大模型上表现优异,不仅是墨芯实力的证明,亦是重要的行业突破:有效缓解AI大模型算力瓶颈、落地难等行业长期、普遍的痛点,为大模型带来“好用”、“用得起”的算力方案,真正满足AIGC落地需求:
- 行业先发,首屈一指
AI大模型参数暴增,对芯片等算力基础设施带来巨大挑战。通常AI芯片能够支持十亿、百亿参数已属难得,墨芯支持高达千亿参数模型,成为业内为数不多的、能够支持大模型落地的AI芯片企业。
- 好用:性能突破,为AIGC全面提速
墨芯更做到性能提升,确保大模型的应用效果:
在ChatGPT等在线式AIGC应用中,AI内容生成速度是最关键的指标之一,墨芯的AI计算平台展示出高吞吐、低延时的优势:
在千亿参数大模型上,8张墨芯S30计算卡吞吐达432 token/s,大幅加快响应速度,性能超过主流GPU,使用户能够更快地获得内容,提升用户体验。
- 用得起:助力AI企业降本增效
对于百亿、千亿参数的大模型,一般需要数张、乃至数十张AI计算卡,才能支持大模型推理。
在活动现场,墨芯仅采用8张S30计算卡,就展现出高吞吐、低延时等优异性能,同时功耗远低于旗舰GPU。这意味着能够为AI企业减缓算力基础设施与运营成本压力,达到降本增效。

墨芯优异的产品表现,不仅为AIGC的更广泛应用打开了空间,更是在AI算力缺口日益巨大的趋势下,为芯片发展弯道超车提供了可行的创新路径。这背后,正是墨芯的核心技术——稀疏计算。
算力之难,AIGC落地之痛
在ChatGPT席卷全球后,基于大模型的AIGC应用迅速兴起,数月内仅国内就有三十余家AI企业推出了大模型产品,以AI芯片为核心的大量算力基础设施更是成为焦点。算力是AIGC竞争的”燃料”,AI企业必须先解决算力问题,才能在市场中保持竞争力。
然而算力问题已经成为困扰众多企业的难题:一方面,算力昂贵。据报道,ChatGPT生成一条回答的成本达数美分,是目前传统搜索引擎的3到4倍;算力初始投入成本约为8亿美元,每日电费在5万美元左右。另一方面是吞吐问题,相较于传统搜索引擎,AIGC的内容生成速度还有待提升。ChatGPT多次因访问超过算力承载能力而出现故障。如果算力问题不解决就上线AIGC产品,很可能会出现问题。
解决算力问题并不简单。首先,算力供需严重不足,业界公认摩尔定律已经失效,算力增长趋于放缓;加上进口高端芯片断供等问题,算力缺口更为显著。另一方面,AI企业正面临算力降本增效的迫切需求,为了满足AIGC的大算力和加速推理等需求,AI企业通常购买更多数量或更高端的AI加速卡,而这些都加重了企业的成本负担。
用单纯堆叠硬件的方式,难以从根本上解决算力瓶颈。业界逐步达成共识:算力的突破口,必须从结合AI模型本身的特性,走软硬协同的道路——有没有既不影响大模型效果,又能减少计算量的方式?
答案正是:稀疏计算。
这也是谷歌、英伟达、Meta、微软等巨头纷纷布局的技术,墨芯已经成为稀疏计算领域的引领者。
稀疏计算的原理是:模型运行时仅激活对处理输入有帮助的参数,即无效元素不纳入计算过程,从而大幅减少计算量。这样一来,大模型发展与算力的矛盾能够得到根本解决:技术计算使大模型可以在参数量上跃升若干个数量级的同时,又缓解了算力负担,为大模型的持续发展带来空间。
稀疏计算已成为业界公认、巨头加紧布局的趋势技术:英伟达A100架构将稀疏化纳入,能支持2倍稀疏率。Google Research的论文《Sparse is Enough in Scaling Transformers》,表明稀疏化是未来大模型的发展方向,稀疏计算能够为大模型带来数十倍加速。
而墨芯做的,则更进一步:当行业对神经网络高倍稀疏化算法还停留在研究层面时,墨芯就已率先一步,把算法和硬件结合落地,基于稀疏计算重新设计芯片架构,推出AntoumⓇ芯片。
护城河稳固,墨芯有望在AIGC时代率先突围
墨芯AntoumⓇ是全球首款高倍率稀疏芯片,支持高达32倍稀疏率,将此前的业界纪录整整提升16倍。
此次,基于AntoumⓇ芯片的墨芯AI计算卡支持千亿参数大模型,赢得各界关注;在此之前,墨芯也已用多次佳绩证明实力:
在众多国际巨头参加的国际权威测试MLPerf 中,墨芯AI计算卡两度问鼎世界冠军,更是在今年的MLPerf中斩获双料冠军。而且这是墨芯AntoumⓇ芯片为12nm制程的情况下,取得了比7nm等更先进制程产品更好的成绩,体现出稀疏计算的巨大优势与潜力。
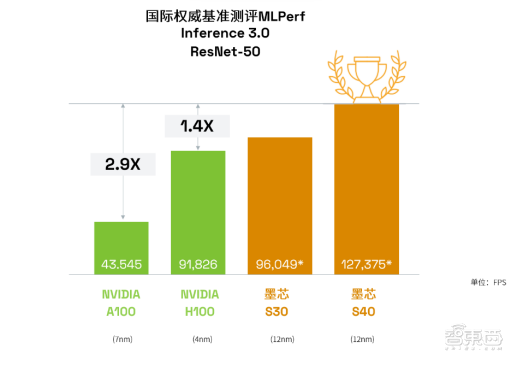
在商业进展上,墨芯也步伐迅速,取得骄人成绩:
快速销售,实现量产:墨芯AI计算卡产品仅数月就达成销售、实现量产,已在互联网、生命科学领域成单落地;
持续拓展稀疏计算生态:已完成百度飞桨等AI框架、浪潮、新华三等主流服务器的适配,并加入龙蜥等国内操作系统生态。
在复杂的形势下,稀疏计算更是对我国AI芯片发展具有重要意义:稀疏计算主要通过算法与硬件协同实现算力增长,在我国芯片先进制程工艺受限的情况下,稀疏计算是实现突破、弯道超车的重要路径。
稀疏计算的想象力不止于AIGC:纵观AI发展史,神经网络借鉴了大脑的机制,稀疏计算借鉴了大脑的低功耗高效运作机制:人脑中约有千亿个神经元、百万级的神经突触连接,执行任务时仅激活相关神经元,同时激活的神经元不到总数的2%。稀疏计算,是通向通用人工智能的必经之路。
AIGC时代的全面到来,注定充满挑战,而挑战往往孕育着机遇。以稀疏计算为代表的颠覆技术成为AIGC时代的曙光,而墨芯已经站在这场算力变革的潮头,让业界看到AIGC市场的新机会,在广阔的市场中率先突围,点亮新的时代。
