








1、中央财经委员会会议:要把握AI科技革命浪潮
2、AI成为本季财报电话会议热门话题
3、超17款大型语言模型被授权商用
4、科大讯飞推出讯飞星火认知大模型
5、智源研究院开源18种语言文图生成模型
6、中科院正打造“紫东太初”2.0全模态大模型
7、小红书秘密筹备大模型团队
8、Meta挖走英国AI芯片独角兽团队
9、法国AI创企Mistral AI计划启动首轮融资
10、OpenAI发布文字生成3D模型Shap·E
11、OpenAI CEO:已不使用客户数据来训练模型
12、谷歌拟用AI聊天和视频改造搜索引擎
13、谷歌Workspace宣布开放Bard功能
14、亚马逊利用生成式AI为广告商制作图片视频
15、亚马逊收购音频AI公司Snackable.AI
16、华为:持续做强昇腾AI产业生态
17、AI教父Hinton:AI威胁比气候变化更紧迫
18、美国国安局官员:情报机构需利用商用AI模型
1、中央财经委员会会议:要把握AI科技革命浪潮
中共中央总书记、国家主席、中央军委主席、中央财经委员会主任习近平5月5日下午主持召开二十届中央财经委员会第一次会议,会议强调要把握人工智能等新科技革命浪潮,适应人与自然和谐共生的要求,保持并增强产业体系完备和配套能力强的优势,高效集聚全球创新要素,推进产业智能化、绿色化、融合化,建设具有完整性、先进性、安全性的现代化产业体系。
2、AI成为本季财报电话会议热门话题
据彭博社今日报道,美国各大科技公司在与投资者的电话会议中,AI以及相关话题被提及次数较去年翻番。据彭博社调查数据显示,在美国500家上市公司中,2023年第一季度在电话会议中提及AI的平均次数高达1100次。OpenAI在第四季度财报电话会议中提及AI的次数增加了77%,苹果CEO库克在本周四召开的电话财报会议中也指出,公司已在大部分产品阵容中使用了AI,将继续将AI技术添加到更多的产品当中。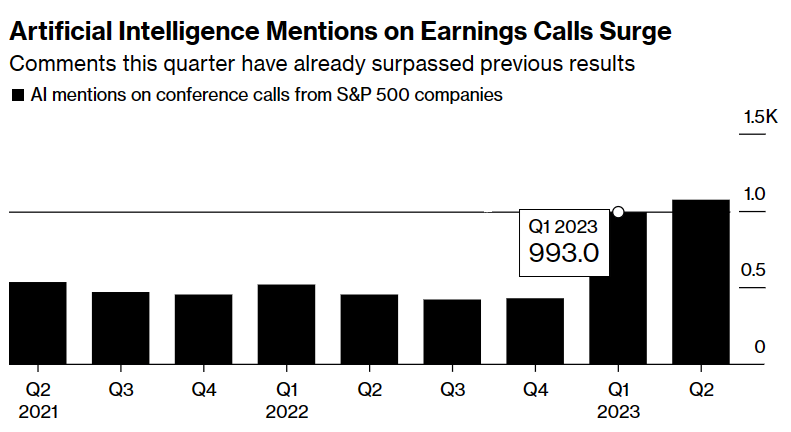
3、超17款大型语言模型被授权商用
一个GitHub项目汇总了被授权可用于商业用途的大型语言模型(LLM),目前已包含T5、UL2、Cerebras-GPT、Pythia、Dolly、RWKV、GPT-J-6B、GPT-NeoX-20B、Bloom、StableLM-Alpha、CodeGeeX、Replit Code、StarCoder、SantaCoder、MPT-7B、h2oGPT、RedPajama-INCITE等17个大型语言模型,并附有相应论文或博客文章的链接。
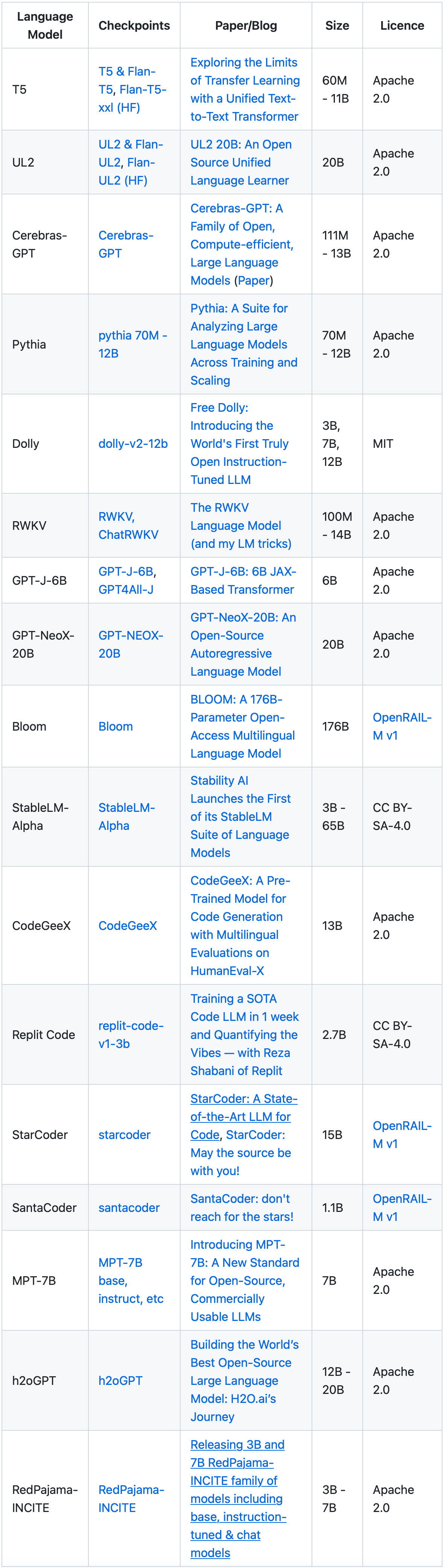
项目地址:https://github.com/eugeneyan/open-llms
4、科大讯飞推出讯飞星火认知大模型
科大讯飞今日发布认知大模型讯飞星火,可实现文本生成、逻辑推理、语言理解、代码能力、知识问答等多种能力。科大讯飞董事长刘庆峰表示,在国内可测试的AI大模型中,讯飞星火大模型认知遥遥领先,和ChatGPT只有细微差距,目前正在进一步优化中。
5、智源研究院开源18种语言文图生成模型
昨日,智源研究院宣布开源AltDiffusion-m18模型。AltDiffusion-m18模型支持18种语言的文图生成,包括中文、英文、日语、泰语、韩语、印地语、乌克兰语、阿拉伯语、土耳其语、越南语、波兰语、荷兰语、葡萄牙语、意大利语、西班牙语、德语、法语、俄语。
当前,非英文文图生成模型选择有限,用户往往要将prompt翻译成英语再输入模型,这样会导致操作复杂并影响生成图片的准确性。智源研究院FlagAI团队首创高效训练方式,使用多语言预训练模型和Stable Diffusion结合,训练出多语言文图生成模型AltDiffusion-m18。
AltDiffusion-m18在英文的FID、IS、CLIP score客观评测上达到了Stable Diffusion 95~99% 效果,在中文、日文上达到了最优水平,同时填补了其余15种语言文图生成模型的空白,极大满足了产业界对于多语言文图生成的强烈需求。相关创新技术报告《AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities》已被Findings of ACL 2023接收。
项目地址:
https://huggingface.co/BAAI/AltDiffusion-m18
https://github.com/FlagAI-Open/FlagAI/blob/master/examples/AltDiffusion-m18
6、中科院正打造“紫东太初”2.0全模态大模型
在今日举行的华为昇腾AI开发者峰会上,中国科学院自动化研究所“紫东太初”大模型研究中心常务副主任、武汉人工智能研究院院长王金桥研究员介绍,基于华为全栈国产化软硬件平台昇腾AI与开源AI框架昇思MindSpore,中国科学院自动化研究所和武汉人工智能研究院正在联合打造“紫东太初”2.0全模态大模型。
自动化所在2021年7月正式发布了全球首个千亿参数多模态大模型“紫东太初”,实现了图像、文本、语音三模态数据间的“统一表示”与“相互生成。“紫东太初”2.0全模态大模型可实现文本、图片、语音、视频、3D点云、传感信号等不同模态的统一表征和学习,并优化语音、视频和文本的融合认知以及常识计算等功能,进一步突破感知、认知和决策的交互屏障。
此外,“紫东太初”大模型开源了基于昇腾与昇思的3.8B图像-文本-语音多模态模型并开放紫东太初大模型服务平台。“紫东太初”大模型已在手语教学、法律咨询、交通出行、广电、医疗机器人、医学影像判读等数十个行业场景领域已展现出落地潜力。

7、小红书秘密筹备大模型团队
据36氪今日报道,小红书从3月份起筹备了独立的大模型团队,核心员工来自广告业务的NLP技术团队。目前该部门在内部为保密状态,在员工系统里也被直接隐藏。团队负责人为张德兵,薯名为“宇尘”,曾担任过一年的小红书智能多媒体算法负责人,主要负责AI和音视频算法方向。在更早期,他还在快手担任多模态智能创作组负责人,负责视觉相关的算法研发。
除了成立大模型团队以外,小红书内部还有多个独立部门同时推进AIGC方向的落地探索。4月份时小红书上线了一款名为“Trik”的AI创作应用,主打AI绘画。
8、Meta挖走英国AI芯片独角兽团队
据路透社5月5日报道,Facebook母公司Meta最近聘请了一个人工智能网络芯片专业团队。该团队曾长期为英国芯片独角兽公司Graphcore开发人工智能网络技术,直至去年年底。Meta发言人乔恩·卡维尔(Jon Carvill)已证实本次招聘。
此举为Meta改善其数据中心的工作方式提供了支持,Meta正努力应对整个公司各个团队对AI基础设施激增的需求,团队都希望开发新的功能。尤其是Meta旗下的Facebook和Instagram越来越依赖AI技术来定向广告、推荐帖子和清除被禁止的内容。
此外,据消息人士透露,Meta已经在内部设立了专门团队,并设计了几种芯片,旨在加速和最大限度地提高其AI工作的效率。其中包括一种网络芯片,可以为服务器执行一种类似于空中交通管制的功能。除了网络芯片外,Meta还在设计一款复杂的计算芯片,用于训练AI模型和执行推断,但该芯片预计要到2025年左右才能准备好。
9、法国AI创企Mistral AI计划启动首轮融资
据Insider今日报道,法国AI初创公司Mistral AI正在计划启动第一轮融资,将筹集近100亿欧元,成为欧洲领先的AI领域参与者。
据悉,该公司是由前公司是Facebook AI部门研究科学家纪尧姆·兰普尔(Guillaume Lample)和谷歌DeepMind前研究科学家亚瑟·门施(Arthur Mensch)联合创办的。目前,有关该公司的公开信息很少,联合创始人兰普尔撰写了许多关于自然语言处理和机器学习的论文,并在在谷歌学术上被高度引用。法国媒体将该公司称为“欧洲的OpenAI”以及“法国对抗ChatGPT的秘密项目”。
据知情人士透露,美国投资者Lightspeed正在与兰普尔和门施商议是否领投80万美元,Mistral AI目前估值约为200亿美元。
10、OpenAI发布文字生成3D模型Shap·E
近日,OpenAI发布新论文,提出了一个3D资产的条件生成模型Shap·E。这是一个3D隐式函数空间上的潜在扩散模型,可以渲染为NeRF和纹理网格。OpenAI发现,在给定相同的数据集、模型架构和训练计算的情况下,Shap·E匹配或优于类似的显式生成模型。
当在配对3D和文本数据的大型数据集上进行训练时,其结果模型能够在几秒钟内生成复杂而多样的3D资产。与点云上的显式生成模型Point·E相比,尽管建立了更高维度的多表示模型,但Shap·E收敛得更快,并达到了相当或更好的样本质量输出空间。
OpenAI还发现,其纯文本条件模型可以在不依赖图像作为中间表示的情况下生成各种有趣的对象。这些结果强调了生成隐式表示的潜力,特别是在像3D这样的领域,它们可以提供比显式表示更大的灵活性。
项目地址:https: //github.com/openai/shap-e
论文地址:https://arxiv.org/pdf/2305.02463.pdf
11、OpenAI CEO:已不使用客户数据来训练模型
美东时间5月5日,美国AI公司OpenAI CEO山姆·奥特曼(Sam Altman)称,公司已经“有一段时间”没有使用付费客户的数据来训练AI大语言模型了。奥特曼在专访中说道,“用户们显然希望我们不要使用他们的数据进行训练,所以我们已经改变了我们的计划,未来我们也不会这样做了。”
网络记录也显示,今年3月1日,OpenAI悄然更新了其服务条款:“不会使用通过其API提交的任何数据来“服务改进”,包括AI模型训练,除非客户或组织选择加入。”
12、谷歌拟用AI聊天和视频改造搜索引擎
据外媒今日报道,谷歌正在改变其呈现搜索结果的方式,将AI对话以及更多的短视频和社交媒体帖子整合到其中,这与数十年来使其成为主导搜索引擎的网站搜索结果列表有所不同。谷歌已经开始在搜索结果中整合一些在线论坛帖子和短视频,但它计划在未来更加强调这类内容。
据公司文件和知情人士透露,谷歌将推动该服务进一步偏离其传统格式,即非正式的“10个蓝色链接”。文件显示,谷歌计划使其搜索引擎更加“视觉化、便当化、个性化和人性化”,重点为全球年轻人服务。谷歌拟将重点放在对传统网络搜索结果无法轻易回答的问题的回应上。谷歌的搜索访问者可能会更频繁地被提示提出后续问题,或者在TikTok视频等视觉效果上滑动来回答他们的问题。
据其他知情人士透露,在将于下周举行的年度I/O开发者大会上,谷歌预计将推出一些新功能,允许用户与一个代号为“Magi”的AI程序进行对话。
13、谷歌Workspace宣布开放Bard功能
谷歌5月5日宣布将其Bard AI工具提供给拥有谷歌Wordspace账户的用户,现已开放Workspace账户的访问权限。据谷歌官方博客显示,谷歌Workspace管理员现在可以为其网域启用Bard,从而允许用户使用自己的Workspace帐号访问Bard。用户在登录已启用管理员功能的谷歌Workspace帐号后,可使用Bard来解决工作、研究或其他业务需求。
14、亚马逊利用生成式AI为广告商制作图片视频
据The Information 5月6日报道,一位亚马逊发言人已证实,亚马逊正在组建一支致力于开发AI工具的团队Creative X,为广告商在其平台上的广告活动生成图片和视频,此举有可能助其实现广告业务多样化。
自亚马逊在2021年开始披露广告收入以来,该业务每季度都能实现两位数增长,去年为亚马逊带来380亿美元收益。亚马逊目前的广告业务重心是在搜索结果中为商家提供助力,该公司正试图打造更广泛的广告业务,包括通过在其免费视频流服务Freevee上出售广告位,以及在Prime Video的周四晚间橄榄球转播期间出售广告。

15、亚马逊收购音频AI公司Snackable.AI
据New York Post昨日独家报道,亚马逊悄悄收购了一家名为Snackable.AI的小型音频AI公司。AI去年为其播客增强了用户功能。亚马逊证实于去年12月完成了对Snackable的收购。该交易的财务条款没有披露。
Mari Joller是Snackable的创始人兼首席执行官,目前在亚马逊担任人工智能和机器学习产品负责人。Snackable将致力于通过亚马逊音乐提供的播客功能。根据她的LinkedIn账户,Joller现在领导着一个“由工程师、应用科学家和计算语言学家组成的团队,为亚马逊音乐播客的客户构建人工智能产品”。
16、华为:持续做强昇腾AI产业生态
据科创板日报今日报道,华为ICT Marketing总裁周军在采访时称,昇腾吸引了超过150万开发者,迄今已发展1100多家伙伴,并推出2000多个联合解决方案,目前有25个城市基于昇腾构建人工智能计算中心,其中14个已经上线并饱和运行。华为将聚焦根技术,持续做强昇腾AI产业生态,坚定践行开放开源策略,持续贡献昇思开源社区,把昇思MindSpore打造成支持大模型和科学智能等AI创新的首选框架。
17、AI教父Hinton:AI威胁比气候变化更紧迫
“AI教父”计算机科学家杰弗里·辛顿(Geoffrey Hinton)本周五在采访中称,相较于气候变化,AI所产生的威胁对人类而言“更加紧迫”。他补充道,人类应对气候变化,相对而言,更容易提出一些有效的应对策略,比如说减少碳的排放,如果你这样做,最终一切都会好起来的。但对于AI的风险,你根本不知道如何下手。
辛顿认为此前业内联名签署的要求暂停AI训练的公开信完全不现实,他认为我们现在应该投入大量资源,找出我们能做些什么。他说:“科技行业的领导人最了解人工智能的风险,政府也必须参与进来。它影响到我们所有人,所以我们都必须考虑如何应对它。”

18、美国国安局官员:情报机构需利用商用AI模型
据彭博社5月5日消息,美国国家安全局研究总监吉尔伯特·埃雷拉(Gilbert Herrera)在接受采访时称,情报界需要以一种不侵犯用户隐私的方法来利用AI模型。他认为如果想要利用好AI的全部力量,必须和工业界加强合作。国家安全局应该使用在开放互联网上训练的大型商业AI模型,并引用外部可访问的公司的数据,比如Facebook、谷歌和微软等。
埃雷拉称,情报机构应该使用商用AI来跟上全球对手的步伐,同时还要确保解决隐私风险和对技术滥用的担忧。情报界必须先解决好如何利用公开信息的问题,否则将会被对手甩在身后。
