








智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
国内性能最强的大模型计算集群,来了!
智东西4月14日报道,今日,腾讯云发布面向大模型训练的新一代HCC(High-Performance Computing Cluster)高性能计算集群。实测显示,该集群的算力性能较前代提升高达3倍,据称是目前国内性能最强的大模型计算集群。
该集群采用最新一代腾讯云星星海自研服务器,搭载英伟达最新代次H800 Tensor Core GPU,属于国内首发。服务器之间采用业界最高的3.2T超高互联带宽,可以为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
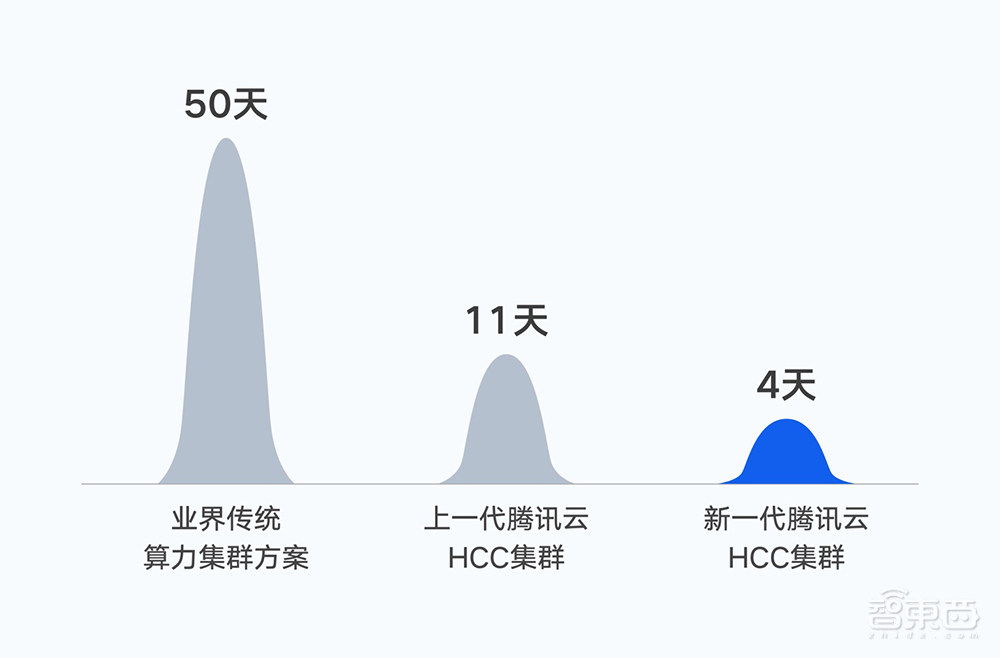
2022年10月,腾讯完成首个万亿参数AI大模型训练,在同等数据集下将混元NLP大模型的训练时间由50天缩短到11天。如果基于新一代集群,训练时间将进一步缩短至4天。
一、最新服务器用上英伟达H800,自研芯片已内部交付使用
H800 GPU是英伟达新代次处理器,基于Hopper架构,对跑深度推荐系统、AI大型语言模型、基因组学、复杂数字孪生等任务的效率提升明显。
与A800相比,H800的性能提升了3倍,在显存带宽上有明显的提高,达到3TB/s。
 ▲A800/H800 GPU基本参数对比(图源:腾讯云)
▲A800/H800 GPU基本参数对比(图源:腾讯云)
相较于上一代的Ampere架构,新的Hopper架构具备的亮点:制程工艺、引入Transformer引擎、第4代NVIDIA NVLink、NVIDIA机密计算、第二代MIG、新的DPX指令等。
此前腾讯的多款自研芯片也已经量产。
其中,用于AI推理的紫霄芯片、用于视频转码的沧海芯片已在腾讯内部交付使用,性能指标和综合性价比显著优于业界。
紫霄采用自研存算架构,增加片上内存容量并使用更先进的内存技术,消除访存能力不足制约芯片性能的问题,同时内置集成腾讯自研加速模块,减少与CPU握手等待时间。
目前,紫霄已经在腾讯头部业务规模部署,提供高达3倍的计算加速性能,和超过45%的整体成本节省。
紫霄芯片已在语音转写、OCR等腾讯业务场景使用:在腾讯的业务场景中,将语音转文字速度提升4.7倍,OCR识别吞吐能力提升2.4倍。视频处理芯片沧海已在云游戏、直点播等场景中规模落地,压缩率比业界通用的软件编解码x265 Medium提升35%。
腾讯云的分布式云原生调度总规模已超过1.5亿核,并提供16 EFLOPS(每秒1600亿亿次浮点运算)的智算算力。
二、先进芯片≠先进算力,大模型对网络提出更高要求
先进算力的背后,是先进芯片、先进网络、先进存储等一系列的综合支撑,缺一不可。
原因是高性能计算存在“木桶效应”,一旦计算、存储、网络任一环节出现瓶颈,就会导致运算速度严重下降。
大模型进入万亿参数时代,单体服务器算力有限,需要将大量服务器通过高性能网络相连,打造大规模算力集群。
据悉,视觉类模型参数需求带宽约在100G到400G,互联网行业需求模型参数带宽需求则高达800G到1.6T。
 ▲不同模型的参数规模和带宽需求(图源:腾讯云)
▲不同模型的参数规模和带宽需求(图源:腾讯云)
即使是目前业界已有的GPU分布式训练方案,也严重依赖于服务器之间的通信、拓扑、模型并行、流水并行等底层问题的解决情况。
如果只有分布式训练框架,甚至都无法正常启动训练过程。这也是为什么GPT-3发布一年时,只有少数企业能复现打造出类似规模的大模型。
三、业界最高3.2T超高通信带宽,TB级吞吐能力存储
那么如何针对大模型对算力的核心诉求,取得最优解?
腾讯云认为,云原生架构是模型训练到应用的最优选择,并提供极致的硬件底座、灵活的实例调用、易用的加速软件等针对性解决方案。
 ▲云原生架构是模型训练到应用的最优选择(图源:腾讯云)
▲云原生架构是模型训练到应用的最优选择(图源:腾讯云)
通过对处理器、网络架构和存储性能的全面优化,腾讯云攻克了大集群场景下的算力损耗问题,能为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。
 ▲不同精度下的单卡算力性能(图源:腾讯云)
▲不同精度下的单卡算力性能(图源:腾讯云)
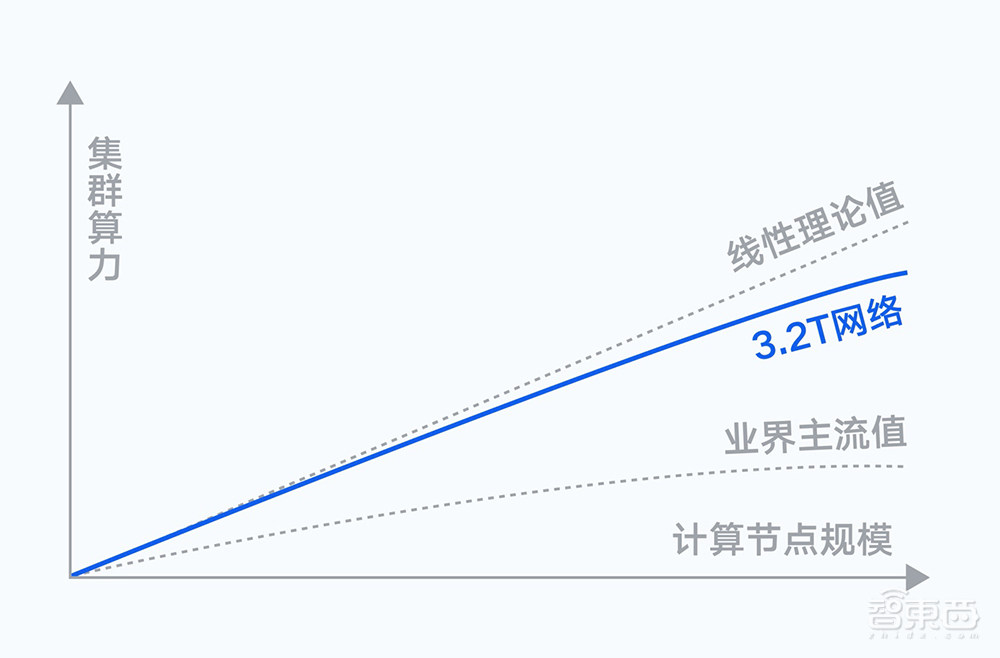
网络层面,计算节点间存在海量的数据交互需求,随着集群规模扩大,通信性能会直接影响训练效率。腾讯自研的星脉网络为新一代集群带来了业界最高的3.2T的超高通信带宽。
实测结果显示,搭载同样的GPU卡,3.2T星脉网络相较前代网络,能让集群整体算力提升20%,使得超大算力集群仍然能保持优秀的通信开销比和吞吐性能;并提供单集群高达十万卡级别的组网规模,支持更大规模的大模型训练及推理。
存储层面,几千台计算节点同时读取一批数据集,需尽可能缩短加载时长。腾讯云自研的文件存储、对象存储架构,具备TB级吞吐能力和千万级IOPS,能够满足大模型训练的大数据量存储要求。
底层架构之上,针对大模型训练场景,新一代集群集成了腾讯云自研的TACO Train训练加速引擎,对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约训练调优和算力成本。
腾讯太极机器学习平台自研的训练框架AngelPTM,也已通过腾讯云对外提供服务,能够帮助企业大幅提高大模型训练显存上限、性能。
四、智算平台覆盖三大方向,支持多种方式取用算力
腾讯云智算平台当前覆盖AI训练/推理、渲染、科学计算三大方向:
1、AI训练/推理,如人脸识别、图像识别、语音识别、智能推荐等。
2、实时渲染,如云游戏、云手机、云电脑、动画制作、智能封面、智能编辑等。
3、科学计算,如流体动力学计算、地震分析、基因组学、芯片仿真等。
在算力层面,腾讯云针对训练、推理、测试及优化场景,提供匹配方案和产品。
其中,HCC高性能计算集群,面向大规模AI训练,以专用集群方式售卖,腾讯云将裸金属云服务器作为节点,满配最新代次的GPU,并结合CFS Turbo高性能存储、节点之间通过RDMA网络互联,给大模型训练业务提供高性能、高带宽和低延迟的一体化高性能计算。
 ▲GPU产品选型关键因素(图源:腾讯云)
▲GPU产品选型关键因素(图源:腾讯云)
此外,腾讯云还通过云服务的方式对外提供适配OCR场景的推理卡、视频编解码的卡等等。
目前腾讯云提供裸金属、云服务器、Serverless容器、云函数、GPU Lab等多形态多层级的算力取用方案。
结语:腾讯正打造面向AIGC的高性能智算网络
集群算力显著提高后,未来不仅能服务于大模型训练,还将在自动驾驶、科学计算、自然语言处理等场景中充分应用。
以新一代高性能计算集群为标志,基于自研芯片、星星海自研服务器和分布式云操作系统遨驰,腾讯云正通过软硬一体的方式,打造面向AIGC的高性能智算网络,为加速云上创新提供支撑。
