








智东西(公众号:zhidxcom)
编辑 | GTIC
智东西4月13日报道,在刚刚落幕的GTIC 2023中国AIGC创新峰会上,NVIDIA消费互联网行业解决方案架构师负责人徐添豪带来了主题为《NVIDIA全栈赋能LLM的前沿研究和规模化部署》的主题演讲。
硬件算力的提升不仅依靠芯片工艺的提升,更依靠准确捕捉AI模型算法演进的需求和趋势,徐添豪说:“找到计算加速的关键点,并不断创新满足未来的业务需求。”进入大模型时代,一张卡远远无法承载一个模型的训练,需要更多个体组成能互相协作的机器节点。
NVIDIA引入NVLink,NVSwitch和IB技术,其中Ampere和Hopper架构就是根据NVSwitch构建节点,通过IB网络进行集群组网,使得这些实力强劲的个体能高效协作完成同一件事。
其中底层硬件是底座,为了开发者把硬件用起来并真正解决问题,需要软件的协同。因此,NVIDIA在过去一直在构建SDK和场景应用以解决各行各业的问题,其中NeMo Framework就是为了解决大模型训练和推理部署问题。
那么,怎么评估训练GPT-3到底需要多少资源?徐添豪讲解了一个公式:消耗的时间=做大模型需要的FLOPS/硬件发挥的有效算力。基于并行方式的有效集成及一系列的优化,NVIDIA的NeMo Framework在训练GPT-3过程中能使得硬件算力有效性能达到50%以上。
此外,为了加速企业的大模型规模化部署,NVIDIA NeMo Framework还提供了基于Faster Transformer和Triton整合的一体化大模型方案。
以下为徐添豪的演讲实录:
大家下午好!非常荣幸今天能够来参加GTIC大会,借此机会围绕LLM(大语言模型)带来一些NVIDIA在硬件、上层的分享。
在这几月,创投圈、技术圈聊大模型的人特别多,今天我不会从行业场景或算法层面来切入这个点,而是大家离不开的算力话题,主要包括三部分:
1、回顾过去五六年NVIDIA迭代的硬件系统设计思考,探讨怎样围绕AI时代来做演进和创新。
2、解读从底层硬件到上层软件构建出来完整的生态系统布局。
3、聚焦更多关注大模型怎么高效把GPU集群用起来的方法。
一、五代硬件系统迭代,解决深度学习时代算力问题
简单回顾一下过去几年大家听到比较多的硬件架构,NVIDIA五个平台架构Pascal、Volta、Turing、Ampere、Hopper对应的产品有五代。除了图灵卡没有训练卡,其余四代都有相应的训练卡。
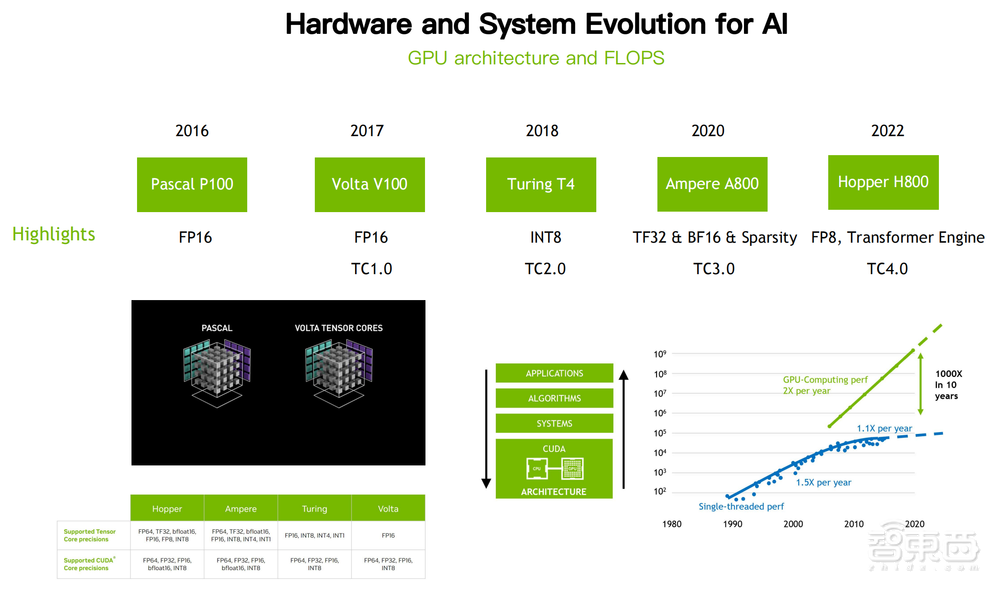
我们可以看到,Pascal架构第一次引入了FP16。以前我们做HPC的时代,FP64的数值精度都是必备的,对于算法结果是很重要的一个保障。到了深度学习、机器学习时代,大家发现FP32就能搞定这个问题,省下很多算力。
再进一步,是不是有更低的数值精度把这个问题解决好?FP16的引入,在P100的架构构成机器上,开创了混合精度时代,再往后到加深了混合精度,到Ampere、Hopper架构引入更多新的数值格式,到Hopper上引入FP8,即将会迎来围绕着FP8的混合精度训练时代。
从ResNet到RNN,从卷积神经网络到Transformer,核心结构都是计算重心在矩阵乘法上,非常直接的一个加速方法或者把算力提上去的方法,就是加速这个矩阵乘法,专门做矩阵计算加速的Tensor Core。过去十年的算力演进,每年相比上一年翻一番,过去十年累计起来可以看到,已经提升了1000倍算力提升。
整个硬件的演进不仅仅把算力通过工艺堆叠起来,也通过不断的创新去找到AI算力需求点,去进行额外的探索工作。
二、引入NVLink、NVSwitch等技术,让多卡并肩作战
一张卡可以认为是单打独斗的人,非常有力量。大模型时代不可能由一张显卡来解决问题,它的问题规模是原来的一万倍、一百万倍,甚至未来更大数量级的提升,我们必须用更多的显卡、更多有力量的个体组成协作节点和集群。
怎么互相协作?
NVLink和NVSwitch是点对点的连接器件,把GPU之间连接起来,高速互联,不再需要走PCIe受限于带宽做信息共享。
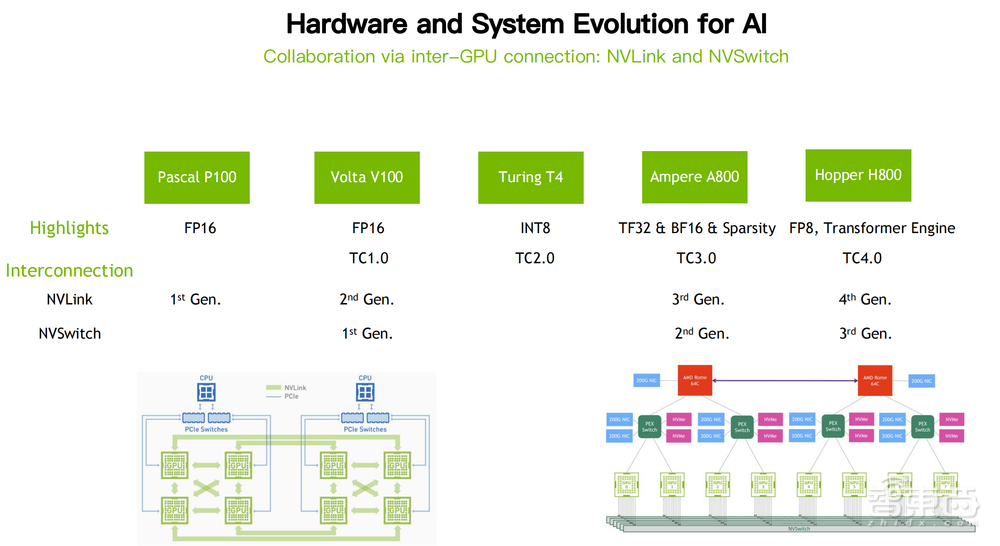
NVLink系统已经演进到第四代,本质差异是带宽增加。在Volta架构引入第一代NVSwitch,由16卡构成的单节点机器,到Ampere和Hopper,现在市场上主流的是这样一些通过NVSwitch构建出来的节点。
NVSwitch就是一个Switch,进行点对点的全速互联,使得这么多非常强的个体能够高效地合到一起,一起做一件事情,机器内节点的演进和思考。
如果说这个问题的规模变得越来越大,比如现在OpenAI做ChatGPT,可能需要上万张显卡一起来做,意味着有几千个节点,这些节点同样需要硬件的连接设备,使得我们有足够的信息交流渠道,让它们以高效一致的步伐来做协作。
引入机器间的网络互联,以交换机和网卡构建出来以IB网络构建的数据中心集群,对于这个问题的解决是至关重要的。
你的节点内问题解决得很好,节点间大家又存在一些带宽的限制,使得它不能高效合作起来,算力就会被浪费。NVIDIA在硬件、底层系统架构设计上过去几年不断演进思考和设计,这才使大家现在能看到基于A800系统赋能快速把大语言模型做出来。
除了底层硬件,NVIDIA在软件生态上花了很多的功夫,自2006年引入CUDA,在生态中构建了很多软件。
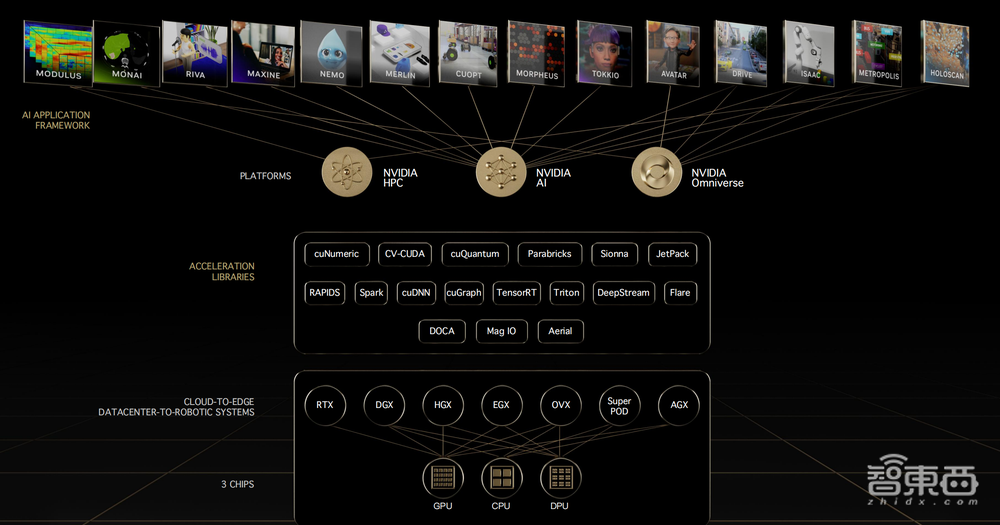
底层的硬件作为一个底座,如果要支持上层做得更好,还需要用各种各样的软件。过去这么多年,围绕CUDA的生态解决了各种各样的问题。比如我们帮台积电解决在芯片设计生产领域的计算加速问题。
类似这样的工作非常多,构成了软件层的核心部分。
三、基于NeMo Framework,GPT-3训练算力有效性能超50%
再到上层,今天大家可能聚焦的NeMo,专门针对解决大模型以及其它训练的问题。
前面大家都提到了做一个GPT-3的训练大概要多少资源。我们拿一千张A800的卡做一个评估,有一个简单的公式,需要消耗的时间等于你做这个大模型,比如GPT-3标准结构,要的FLOPS是多少,通过理论方式可以算出来。

同时除以硬件的FLOPS乘以它的有效性,硬件真正发挥出来的FLOPS,等于你做完这个问题到底要花多少时间。前面都是定的,比如我有一个参考,GPT-3这样的结构去过300 billon tokens的数据,假设给你128台A800机器组建的集群,用FP16做训练的话,单卡的FLOPS是312TFLOPS,总共有128个节点,算出来这些是定的FLOPS。
大家做各种各样的软件设计去实现更快的训练收敛效率,非常核心的因素在于这个“50%”。NVIDIA在NeMo Framework上175B的规模在128台机器上超过50%。各路业内大拿都在用各样各样的方法,都是围绕这50%做得更高,这也成为一个持续的话题。
基于这个值,128台机器需要24天左右的时间完成300 billon tokens的数据训练175B的模型,这个可以跟大家看到的1000张卡一个月左右的时间对上。
考虑到前面的硬件结构设计,机器内通过NVSwitch互联,互联带宽非常强,可以把需要更多的带宽通信的并行模式放到节点内。通过这样的技术再结合ZeRO1等技术可以实现前面提到的50%+的效率,这是非常好的效果。
NVIDIA推理方面在过去几年跟国内各行各业都有非常紧密的合作,在这个过程当中不断地积累,有一套Fast Transformer,对于部署场景提供更高的吞吐以及Latency的平衡,有时候在GPU的硬件设备上为了拿到更大的吞吐可能要组Batch,这是常见的部署方法。
此外,为了加速企业的大模型规模化部署,NeMo Framework还提供了基于FasterTransformer和Triton整合的一体化大模型方案。
四、总结:NVIDIA全栈赋能LLM的前沿研究和规模化部署
总结一下前面讲的,从2016年Pascal架构到现在Hopper架构马上要开始部署了,每代显卡针对当时甚至未来AI的模型可能出现什么结构做前沿的创新,这些创新落实到现在能看到的训练脚本里面,甚至是一些框架里面。
由这些非常强的个体本身的算力演进来提升1000倍算力,由超强的个体再组成节点集群,这里面都有NVIDIA非常多的思考,有着每一代技术的演进,才能构成超强的计算集群,来为大模型时代提供非常好的基础架构设施参考。
下一步,围绕硬件以外的软件生态,NVIDIA构建出全栈的、能够直接最终给到大家开箱即用的一系列加速软件方案,帮助大家在接下来的大模型时代能有更快的速度,推出用时间、空间来赢得在市场上地位的软硬件一体化方案。
这就是我的分享,也是过去跟行业内各个客户,真实把这些技术结合硬件、软件、生态落地之后的一些思考。
谢谢大家,我的分享就到这里。
以上是徐添豪演讲内容的完整整理。
