







作者:Dr. Luo,东南大学工学博士,英国布里斯托大学博士后,是复睿微电子英国研发中心GRUK首席AI科学家,常驻英国剑桥。Dr. Luo长期从事科学研究和机器视觉先进产品开发,曾在某500强ICT企业担任机器视觉首席科学家。
一、自动驾驶行业简介
2022年可谓是ADS的L3自动驾驶元年。近几年来,行业的数字化和行业的AI化,推动ADS向阳而生:从单车智能维度,L2部分功能已经成为行业标配:2022年前五个月的搭载率25.5%,几个主流车厂的新车款的搭载率甚至到70%以上。在硬件预埋(大算力芯片 + Multi-View Camera + LiDAR + Radar)的趋势驱动和最新的ADS行业准入法规政策驱动下,L2+快速向L3演进已经是大势所驱,今明两年,可以预测到城市级L3+将会在国内迅速普及。软件定义汽车,甚至是AI定义汽车,必然是当前的一个时代主流趋势。
自动驾驶ADS主要是由高速场景向城市道路场景演进来落地领航辅助NOA功能,AI与场景的深度融合,推动ADS逐步实现从低速到高速,从载物到载人,从商用到民用,从阶段一提供L2高级辅助驾驶和L3拥堵高速公路副驾驶,发展到阶段二可以提供L3拥堵公路自动驾驶和L4高速公路自动驾驶,最终实现阶段三的L4城郊与市区自动驾驶和L5商用无人驾驶等等。
二、ChatGPT行业简介
生成式AI大模型,包括近两年推出的ChatGPT和Stable Diffusion,能够比较满意地完成类似通用的问题答问Q&A系统任务,以及特定内容的高清图像生成。ChatGPT(Generative Pre-trained Transformer)是OpenAI开发的一款生成式AI模型,它结合了监督学习和强化学习方法,通过对话的方式来进行交互:依据用户的文本输入来做多种语言的智能回复,简文或者长文模式,其中可以包括不同类型的问题答复,翻译,评论,行业分析,代码生成与修改,以及撰写各类计划书与命题书籍等等。各类生成式AI模型也可以联合调用来提供丰富的人机对话的能力。生成式AI模型多需要海量的参数,来完成复杂的特征学习和记忆推理生成,例如ChatGPT模型参数为1750亿。如图 1所示,ChatGPT有两个主要类别的应用:
- 改善我们的日常生活,做人类力所能及的语言文本图像视频类的分析而且可能会做得更好;
- 在行业AI化过程中通过模型的新训练方法,数据/场景的生成以及可理解可解释的输出等功能来加速AI的开发进程。
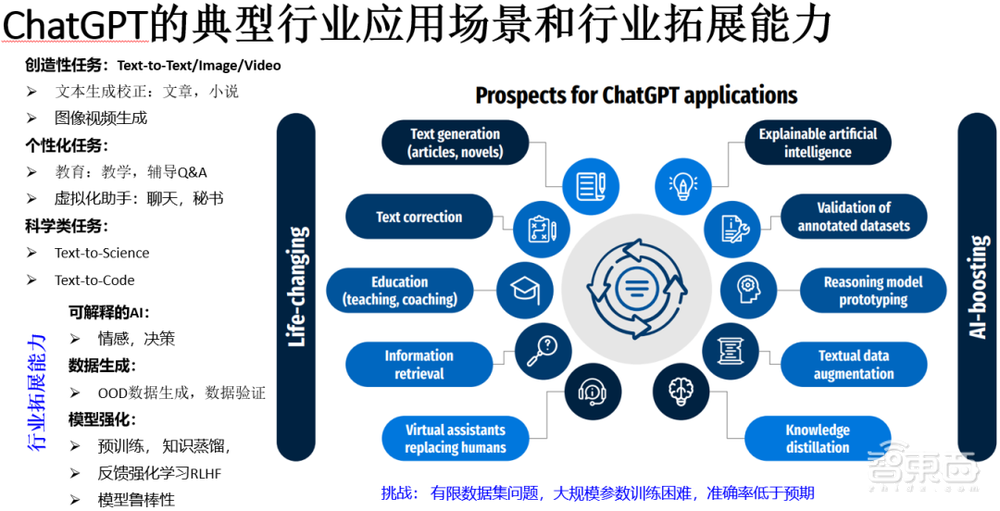
图 1 ChatGPT的典型行业应用场景和行业拓展能力 (Kocon 2023)
三、ChatGPT的底层技术分析
Transformer系列模型能够成功应用到NLP和CV的一个主要原因是其编解码器架构。其优势体现在:训练与推理的并行能力强;关注机制模型带来的全局感受域有利于捕获文本图像中的距离与语义关系表征;相同网络层的简单数量上堆叠使用可以快速构建大模型。当模型复杂到一定程度(例如600亿以上参数),可以做为一个通用模型来针对下游的不同视觉任务,获得与人类相当的性能。而互联网上轻松获得的海量公开多模态数据,结合大模型LLM的无监督或自监督学习,通过人工的数据清洗、预训练和人类反馈强化学习,对提升性能也变得非常容易。
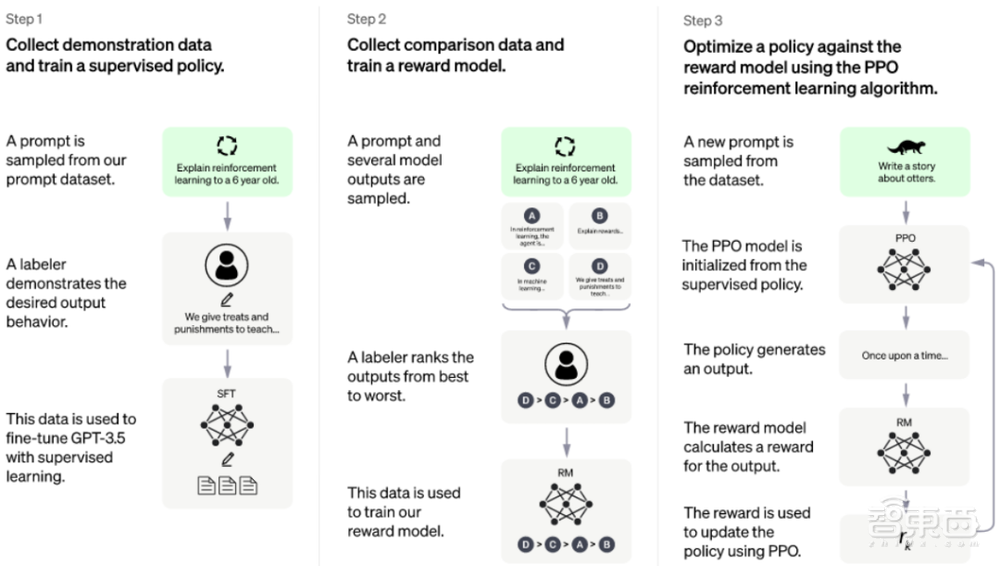
图 2 ChatGPT模型的训练流程(G-Brizuela, 2023)
如图 2所示,ChatGPT模型结合了监督学习和强化学习方法,采用了基于人类反馈的强化学习RLHF训练方法,与此同时采用了迁移学习(或者叫自监督学习)的训练方法,即通过预训练方式加上人工监督进行调优(近端策略优化PPO算法)。RLHF训练方法确实可以通过输出的调节,对结果进行更有理解性的排序,这种激励反馈的机制,可以有效提升训练速度和性能。在实际对话过程中,如果给出答案不对(这是目前最让人质疑的地方,可能会错误地引导使用者),可以通过反馈和连续谈话中对上下文的理解,主动承认错误,通过优化来调整输出结果。给出错误问答的其中一个主要原因是缺乏对应的训练数据,有意思的是,虽然缺乏该领域的常识知识和推广能力,但模型仍然能够胡编乱造出错误或者是是而非的解答。ChatGPT的另外一个主要缺陷是只能基于已有知识进行训练学习,通过海量的参数(近100层的Transformer层)和已有的主题数据来进行多任务学习,目前来看仍缺乏持续学习或者叫做终身学习的机制,也许下一代算法能够解决这个难题。
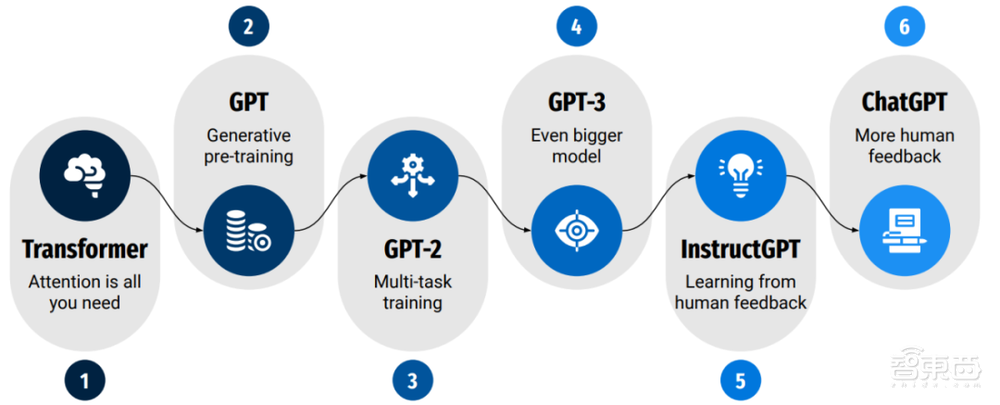
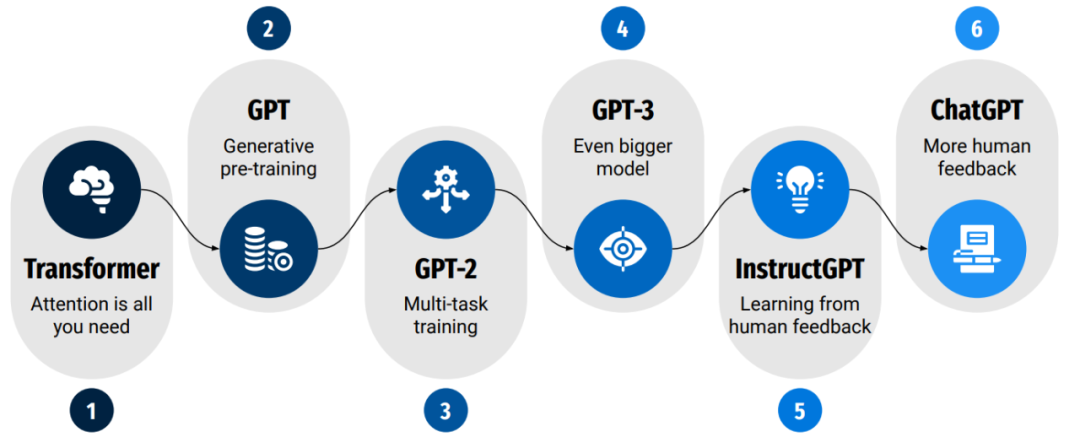
图 3 GPT不同版本模型的演进趋势 (Kocon 2023)
如图 3所示,GPT不同版本模型的演进趋势总结如下:
●GPT-1: 对比Transformer基础架构,GPT第一代模型只采用了Transformer Decoder Stack和单方向的自关注模型,可以很好的应用于文本翻译、做摘要和回答问题。
●GPT-2:GPT-2模型延申了这些设计理念,通过引入多任务学习来对模型的下游任务进行调优训练,与此同时,将输入上下文的长度设置GPT-2:GPT-2模型延申了这些设计理念,通过引入多任务学习来对模型的下游任务进行调优训练,与此同时,将输入上下文的长度设置从512增加到1024,模型参数从117M(GPT)增加到1.5B(GPT-2),预训练用的数据也增加到40GB。GPT-2成功显示了,即使不用大量数据做监督学习,模型也能够处理应对很多新应用任务。
●GPT-3:模型参数从1.5B(GPT-2)增加到175B(GPT-3), 预训练用的文本数据也增加到45TB。数据驱动的大语言LLM模型成功演示了zero-shot和few-show场景的优越性能。
●InstructGPT:由于训练GPT-3用的海量互联网公开数据存在的数据偏见和不可靠性问题,GPT-3有时会生成一些具有冒犯性的文本,输出结果也经常低于用户的期望。对于如何能够匹配用户需求,InstructGPT采用了人类反馈做为奖励信号,通过强化学习RLHF来更新模型参数。对于所谓的人类反馈, OpenAI第一步采用了特别的人工标注方式(即标注工作者的思路必须是高度一致),对不同的提示所对应的期望答案类型进行描述,第二步即模型随后的调优跟随这个输入,按照系统响应的排序来训练奖励模型。最后一步是采用近端策略优化PPO算法来进一步提升模型质量。
●ChatGPT:ChatGPT是InstructGPT的一个最近的迭代版本,它显然采用了更多的用户反馈来处理更多的多样化任务,目来看公开细节不多,估计采用了非公开数据集。ChatGPT的基础模型参数为3.5B,从对话任务的质量要好于有17.5B参数的GPT-3,这显然与收集人类数据来做模型的监督学习调优有很大的关联性。
对于如何评估ChatGPT,一种思路(Kocon 2023)是采用不同类别的公开数据集来评估模型的多样性,包括多数人口的期待和少数民族/个人的敏感问题。但ChatGPT在专家领域(教育,医学,法律等) 应用的一个主要限制,依旧是结果的可靠性和可解释性,所以全面和系统的评估至关重要。如图 4所示,一种简单案例(Kocon 2023)是评估ChatGPT对不同任务中提问的辨别,即检测问题是可以回答的还是不能回答的,可以看到,模型不能有效检测到这类不能回答的问题导致给出错误回答的比例还是非常非常高的,需要通过用户不停提示来纠偏。
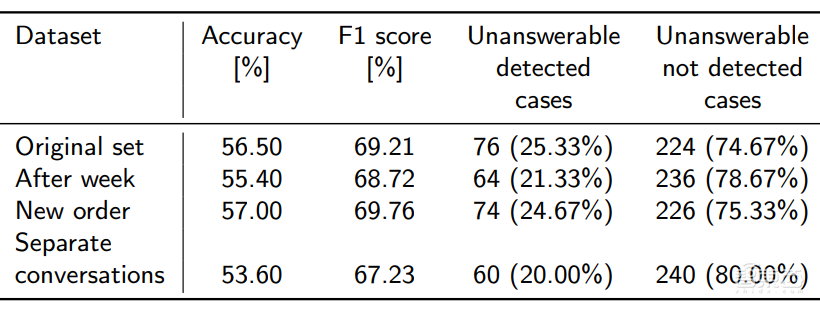
图 4 ChatGPT对于用户问题的理解实验分析(Kocon2023)
LLM大语言模型,包括GPT-3,ChatGPT,其性能很大一部分依赖与任务相关的提示Prompt的质量。基于提示的学习范式,对于工程化实现落地和行业拓展,有非常大的挑战,这要求非常细致的提示的工程工作和提示微调。提示微调的方法或者通过对下游任务质量来验证其相关性,或者直接约束范围是可以用来评估模型的语言理解能力的。ChatGPT的优势是可以为其答案给出自解释的理由的,即所谓的自解释的AI(XAI),具体可以总结其中几个要点如下(Kocon 2023):
●ChatGPT可以为其决策提供合理的符合事实的澄清
●ChatGPT看上去不太关注个人,反而比较注意态势Situation
四、ChatGPT和自动驾驶的融合趋势分析
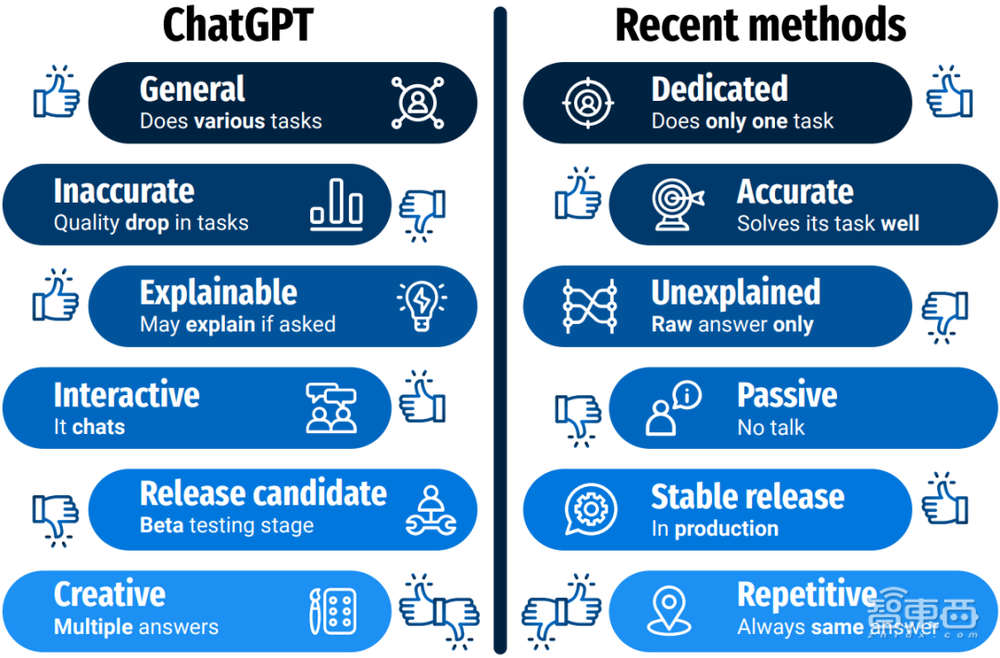
图 5 ChatGPT与SOTA专项NLP/CV 类任务的差别总结(Kocon2023)
如图 5所示,ChatGPT与其它SOTA专项任务(包括NLP/CV)的差别对比,这里所说的专项任务,可以包括NLP,CV,以及自动驾驶的感知决策类模型任务,具体差别可以体现在:通用/专用,生成式/可重复生产,高低精度,是否可解释/可交互,等等。
从ChatGPT的行业拓展趋势来说,需要解决超大模型部署的推理加速优化问题。避开这个问题不谈,提升ChatGPT性能的学习方法和训练已经开始在自动驾驶ADS等领域得到部分应用,包括模仿学习,在线和离线决策策略Policy学习,知识蒸馏用于模型压缩和跨模态的知识迁移学习等等,ADS场景数据集自动生成等等。
ChatGPT当前的一个核心问题是模型的鲁棒性问题,即对于不确定性输入其性能的稳定性,这对于安全至关重要的应用来说非常关键,这要求行业能够交付有责任的AI (Responsible AI)。如图 6所示,对于对抗性和Out-of-Distribution (OOD)分类任务评估来说,可以看出所有模型的绝对性能都远低于期望,有很大的提升空间,包括ChatGPT。例如对伪造新闻的检测来说,攻击者可以通过添加噪声和一定的内容扰动可以轻松绕过AI检测系统,所有没有鲁棒性,系统的可靠性会很容易坍塌。而OOD的场景,也包括遮挡或者屏蔽场景,有时会很容易引入输出结果的过度自信输出。训练一个基础大模型的成本非常高(千万美元级别/次),所以针对下游任务的零样本zero-shot性能非常重要。
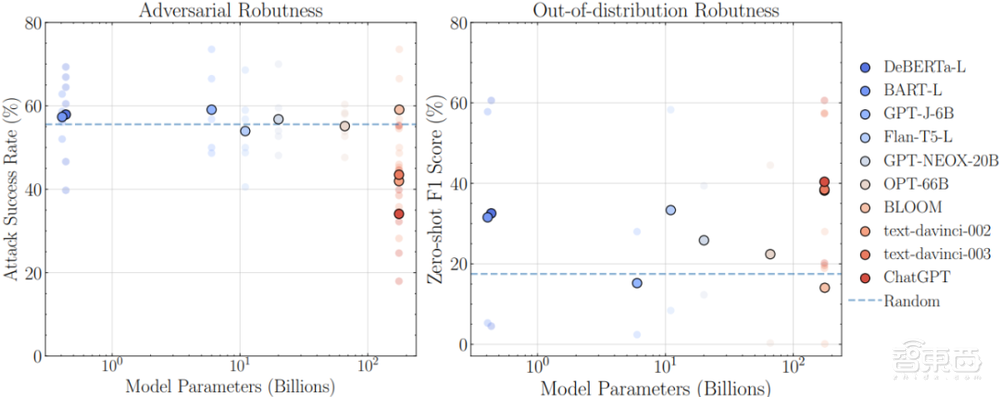
图 6 LLM大语言模型的鲁棒性评估(对抗与OOD分类任务):性能 vs 参数尺寸(wang 2023)
如图 6所示,ChatGPT和其它基础模型的对比如下(wang 2023):
优势:
●对于对抗和OOD样本有比较一致性的性能提升
●翻译任务能力强,在对抗性输入下有合理的可读的一致性响应
●对于对话相关的文本有更强的意图理解能力,这与学习方法和数据集处理有
劣势:
●对于对抗和OOD样本,整体性能低于预期
●对于医学相关的问题,难以提供确定性的答案,更多只是非正式的建议和分析,比较适合健康小助手的角色
做为一个大规模语言LLM模型,ChatGPT主要关注于多任务、多模态和多语言的性能,而当前ADS主要关注在4D时空场景下甚至是5D场景(+关注目标的自运动状态等)下多任务、多模态的安全决策性能,未来引入语音文本输入也是一种大趋势。
业界针对ADS所采用的Vision Transformer(ViT)模型,通过类似方法来构建例如ViT-22B的大规模视觉LVM模型,在40亿JET数据集上进行训练,对图片分类任务有很好的提升,但LVM模型未能呈现LLM大语言模型所呈现的浪涌效应“emergent abilities”。这里的浪涌效应是指语言模型突破到规模的临界点:例如GPT-3 (130亿参数),LaMDA (680亿参数),模型的表现出现快速提升的态势,能够很好地从学会的知识的紧凑表达中去记忆和尝试知识,理解应对本文中所提到的Zero-Shot或Few-Shot Prompting任意任务和多步推理Multi-Step Reasoning的应答能力。目前来说,浪涌效应的理论尚不清晰,LVM模型的临界点在何方有待探索。模型的规模、结构,模型的训练方法和学习方法,数据集的规模,以及人类反馈和任务提示的质量,对浪涌效应来说都是值得深度研究的。对于ADS系统来说,目标的交互关系、多模态环境元素的融合空间表达,目标利益的博弈关系,安全决策驱动下的感知融合,这些高维度的有效表征,对探索LVM的浪涌效应都是至关重要的。
参考文献:
1. J. Kocon and etc., “ChatGPT: Jack of all trades, master of none”, https://arxiv.org/pdf/2302.10724.pdf
2. J. Wang, and etc., “On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective”, https://arxiv.org/pdf/2302.12095.pdf
复睿微电子: 复睿微电子是世界500强企业复星集团出资设立的先进科技型企业。复睿微电子植根于创新驱动的文化,通过技术创新改变人们的生活、工作、学习和娱乐方式。公司成立于2022年1月,目标成为世界领先的智能出行时代的大算力方案提供商,致力于为汽车电子、人工智能、通用计算等领域提供以高性能芯片为基础的解决方案。目前主要从事汽车智能座舱、ADS/ADAS芯片研发,以领先的芯片设计能力和人工智能算法,通过底层技术赋能,推动汽车产业的创新发展,提升人们的出行体验。在智能出行的时代,芯片是汽车的大脑。复星智能出行集团已经构建了完善的智能出行生态,复睿微是整个生态的通用大算力和人工智能大算力的基础平台。复睿微以提升客户体验为使命,在后摩尔定律时代持续通过先进封装、先进制程和解决方案提升算力,与合作伙伴共同面对汽车智能化的新时代。
