








芯东西(公众号:aichip001)
作者 | 李水青
编辑 | 心缘
当下,人工智能产业发展正在进入“大模型”阶段,1700亿参数的超大规模深度学习模型GPT-3,指引整个人工智能产业寻找一条新的可行之路,缩短我们与通用智能的距离。但与此同时,海量的数据和超大算力需求,让大模型的产业化落地面临巨大的算力挑战。
在摩尔定律逼近物理极限的情况下,中国AI芯片创业大军并非无计可施,而是涌现出一大批革新者,用底层技术创新挑战既有的行业垄断龙头。
创立于2018年的云端AI芯片公司墨芯人工智能就是其中一个代表。
诞生于硅谷,总部位于深圳,这家公司推出多款基于自研稀疏计算芯片的AI计算卡,运行ResNet-50算力超90000fps。相较于当前国际大厂主流推理卡单卡只能支持百亿参数级别的模型,据称,其可以支持千亿参数级别的模型,这意味着让拥有1700亿参数的GPT-3大模型跑在单张计算卡上。
深扒团队背景,创始人兼CEO王维曾在美国高通和英特尔担任架构师,是英特尔5-10代CPU处理器的核心成员,参与开发量产超50亿片芯片,同时他也有过硅谷芯片公司创业经历;首席科学家严恩勖是卡内基梅隆大学拥有40多篇AI顶会成果的机器学习博士。
起点高,冲得快,是很多业内人对墨芯人工智能的印象。
那么这家公司到底有什么核心竞争力?背后又有什么样的创业故事?纵观当下的AI芯片产业化落地潮和价值检验窗口,墨芯能否持续将技术成果转化为产业价值?
近日,墨芯创始人兼CEO王维与智东西进行了线上对话,回顾了四年创业关键节点,并对这些问题进行深入探讨。
今年8月26日下午,王维将出席在深圳举办的GTIC 2022全球AI芯片峰会·云端AI芯片专题论坛,并发表主题为《面向AI未来的稀疏化计算》的演讲。

一、单卡支持大模型,运行ResNet-50算力超90000fps
2022年的元旦夜,王维和几个核心测试人员在实验室,刚刚拿到首颗芯片Antoum的回片。4年努力和艰辛到了验证时刻,王维和同事们立刻将所有软件跑上去,上电的那一刹那,整个芯片驱动程序就刹那间跑通了。
他们当晚连夜把ResNet-50跑通,发现性能都顺利达到了当初设计的目标。“这款全球首款高达32倍稀疏率的AI计算芯片,在算力、功耗、能效比——云端芯片的三大核心技术点上,Antoum都做到了突破性创新。”王维对智东西说。
这是王维创业四年里最兴奋和有成就感的时刻。
所谓稀疏化计算,是一种以人脑得到灵感的模型压缩方法。简单来说,就是通过底层创新、软硬协同设计,让神经网络模型消减冗余,以提高计算效率。
仅仅在流片成功4个月后,今年4月,墨芯就推出首款基于Antoum芯片的S4计算卡。在第三方浪潮服务器上,S4运行多个主流AI模型,实测性能是国际大厂主流AI推理卡T4的6倍。

▲基于Antoum芯片的S4计算卡
近年来新兴的NLP模型——T5,曾被称为“全新NLP SOTA预训练模型”,以其高参数量,让许多计算卡“望而却步”。S4在单机单卡环境下就能运行T5-8B模型,算力稳定在190sps左右。S4运行T5时内存占比只有约7.8%,让人对它能够支持的模型参数具有很大想象空间。
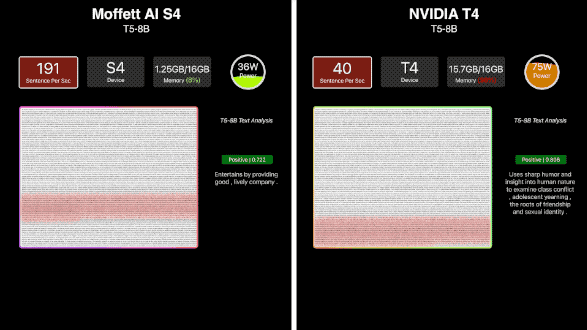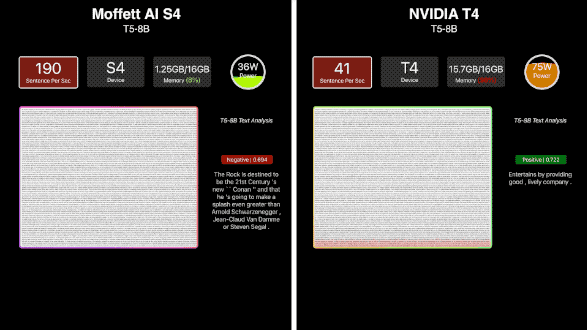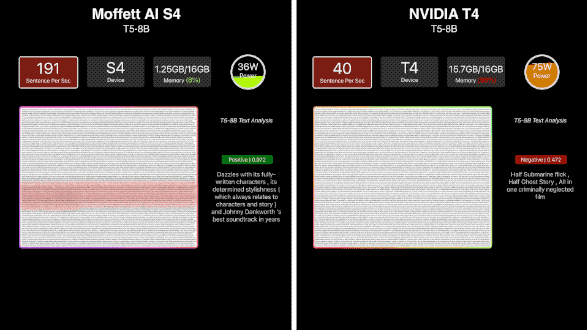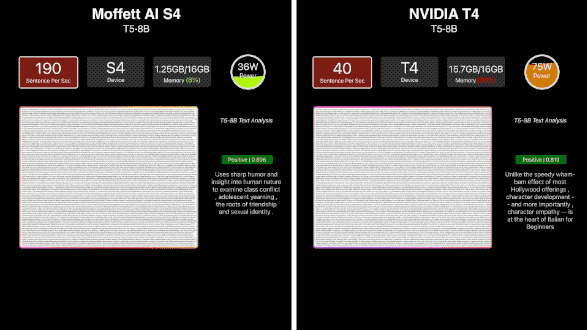
相较于当前国际大厂主流推理卡单卡只能支持百亿参数级别的模型,S4计算卡可以支持千亿参数级别的模型。而随着S4性能得到验证,更大尺寸的S30也迅速推出,适用于能效比、功耗更高的场景。

▲基于Antoum芯片的S30计算卡
王维向我们举了一个例子,GPT-3模型是拥有1700多亿参数的大模型代表,如果放在GPU上去做推理的话,需要内存量是要几百G,也就是需要很多张80G的GPU,且会有明显时延;但通过稀疏化路径,用一张墨芯S30计算卡,就可以跑通GPT-3,并且计算速度还变快了很多。
墨芯正通过打造这一套芯片和软硬件产品,去推动深度学习更高算力、更大规模、更低计算成本的方向去发展。
就在近日,第三方实测数据显示,墨芯S4计算卡运行ResNet-50,算力达33197fps,S30计算卡运行ResNet-50算力超90000fps。
墨芯已成为非盈利性机器学习开放组织MLCommons会员,后者由谷歌、英伟达、英特尔、Facebook、浪潮等全球AI领军企业创建,是业内权威基准测试MLPerf的监管者,9月将公布其首批稀疏化计算卡S4和S30的性能测试结果,有望代表国产AI芯片达成一个新里程碑。
二、主攻稀疏化计算,在云端AI芯片赛道独辟蹊径
纵观全球云端AI芯片创业大军,如同过独木桥般竞争激烈。
一个创业公司想要从行业垄断龙头口中抢占市场蛋糕,想在各显神通的AI芯片创企中杀出一条血路,就一定要有来自底层技术的颠覆性创新,而不能是微量的差异化和创新点。王维认为,这个技术差异化或者性能提升至少需要10倍。
稀疏化计算技术在王维看来是一条能实现10倍颠覆性创新的路径。
“(稀疏化计算)技术差异化达到了一个数量级,当时我们就可以在算法层面上做到接近20倍的稀疏率,模型精度不改变,这是一个足够颠覆性的技术特点。”王维说,“同时,稀疏计算无需再造一个生态,它和现在所有的AI训练、推理生态兼容,因此市场化落地可以确定。”
事实也正如王维所料,市场几乎不需要他去重新教育。其接触了很多行业的头部客户,本身有较强的AI算法和人才,所以都十分认可稀疏化计算在深度学习推理、训练的潜力和发展空间。
令客户好奇的是,墨芯把稀疏化做到什么程度了?产品的完整性如何?是不是到可用甚至易用、通用的程度了啊?这个里面的技术差异性有没有足够大,让我足够有兴趣,去选择国际大厂之外的第二供应商?这些是更加重要的问题。
而这,实际上也是当下云端AI芯片产业发展至今,走向规模化落地的最大挑战之一。
在墨芯创业之时,各路玩家都在求索突破摩尔定律极限的新路。业内已经有一些显性路径,比如通过存算一体设计,在底层硬件层面做优化。而从稀疏化算法,是从上层AI算法切入做芯片优化的另一路径。无论是那条技术路径,除了要向客户证明其产品差异化,还要证明其技术完整度及TCO(总拥有成本)。
而在众多技术路径中,稀疏化计算在当时可谓人迹罕至。包括英伟达、英特尔等大芯片厂都还未有推出相关产品,而是在这两年才有相关进展。
这也决定了墨芯在研发与落地过程中几乎没有同类玩家可以参考,挑战重重。
三、硅谷20年芯片老兵+算法大牛创业,打造算法定义计算平台
如何在毫无参考的情况下实现底层创新突破?
“很显然,你需要有顶级的算法科学家,对于稀疏化计算这一套理论有很强的突破性和创新性,因为这个地方是最核心的创新源、创新点。”
王维告诉我们,令他有底气的是,墨芯从早期团队设置就兼顾了算法、架构、芯片设计的顶尖人才。
2018年冬天,王维从美国硅谷飞往卡内基梅隆大学,与正在读博士的校友严恩勖聊了两天两晚,当即拍板基于稀疏算法做AI芯片创业。严恩勖是神经网络动态稀疏算法发明者,曾在Google和Microsoft Research担任研究员,在国际顶级人工智能期刊论文发表40余篇。
彼时,1700亿参数的GPT-3大模型还没有诞生,但关于通用人工智能发展的潮水已在业内暗流涌动。大模型意味着巨量数据和算力需求。时任英特尔芯片架构师的王维看到了其中的创业机会。
就在与严恩勖会面的几个月前后,王维找来了硅谷20多年的好友。这两位好友分别是有20年以上SoC芯片设计和团队管理经验的芦勇,他曾任SK Hynix芯片设计总监和Marvell资深芯片设计经理;以及,拥有18年DSP、CPU处理器以及硬件加速器学术及产业经验的肖志斌,他曾是阿里达摩院的核心架构师和研究员。
在半导体圈摸爬滚打20多年,王维、芦勇和肖志斌深知半导体是一个成熟行业。
在这一行业,如果要寻求机会的话,一定需要一个爆发点的应用产生。就如同过去20年,PC、移动互联网手机的兴起,为半导体行业带来的巨大空间一样。现在,人工智能正在带来新的大趋势、大机会、大市场。
2018年8月,墨芯人工智能(Moffett AI)正式在硅谷创立。
墨芯取自其英文名Moffett的谐音,这是其创业起源卡内基梅隆大学硅谷校区的地名;同时,墨芯也有“墨子芯片”之意,致敬中国古代伟大的科学家墨子。
经过全面系统化分析推演之后,王维和几位创始人已经一步步明确执行了其设立的目标——打造一个优秀的算法定义计算平台,支持前沿的稀疏化计算框架。
四、两年闷声研发,一次流片成功,首颗芯片即量产
看好国内的创业大环境和市场,墨芯人工智能于2019年5月在深圳建立总部。
而此时,墨芯也正式完成研发首颗芯片的前期筹备。尽管团队都是经验丰富的芯片老兵,但由于稀疏化计算在国内外都没有先例参考,墨芯的芯片真正完成研发转去流片,已经是两年后2021年5月。在这两年里,墨芯除了拿下了来自基石、真格基金、深圳天使母基金、凯旋创投、将门创投领投、浪潮和智慧互联产业基金等战略投资的三轮合计数亿元的融资,大多数时候没有更多消息流出。
AI和大数据带来的时代的变量,已经改变了半导体设计思路,闷声做研发的墨芯是这一进程的亲历者。
墨芯选择“算法创新,定义芯片架构”的策略,这与传统芯片公司只攻底层的设计思路不同。简单来说,这一方法是通过理解创新算法的突破,用这些新算法的突破来定义软件架构,再往下定义硬件架构。
当下,市面上已有同行也在打造算法定义硬件或算法芯片化产品,但与基于特定场景做算法芯片化的做法不同,墨芯更注重应对通用性、易用性的基础算力需求。聚焦数据中心AI算力需求的通用性,其在大数据里提取核心特征,为应用场景做决策和判断。
“我们是一次流片成功,第一颗芯片就是量产芯片。”王维告诉智东西,“这件事情的考验,完全在于芯片团队,它是否有足够的经验和能力,能够承担得起一个这么大一块芯片,一次流片成功。我相信我的团队很好的、非常出色的完成了这个任务。”
五、流片半年已有多家客户,构建生态发力三大市场
2022年被认为是中国AI芯片产业化落地元年。四年磨一剑,墨芯也正开启稀疏化创新技术路径的产业化推广。
今年7月,王维已经谈下了几家客户。流片成功仅半年,在互联网市场,墨芯已在一些头部互联网公司进入适配阶段;在行业市场,墨芯也与生命科学领域部企业项目落地。
在未来一个阶段中,墨芯将围绕互联网、泛政府行业及垂直行业三大方向进行市场推广。在定价上,墨芯不会采取低价策略,而是将整个算力服务器的TCO(总拥有成本)达到现有主流产品的1/2,甚至1/3。
在王维看来,稀疏化计算是一个通用的、正前沿的发展方向,它在技术层面上没有什么局限性。现在最大的挑战是关于稀疏化的计算生态。只有生态完备,这些产品能够更快速的让各个行业的用户快速使用起来、熟悉起来。
因此,墨芯面对的下一步更大的挑战是如何未来去建立一个生态同盟的合作关系。
在算法生态方面,由于墨芯是从算法创新,与当下主流算法框架高度兼容,已通过众多SDK布局TensorFlow、PyTorch等主流框架接口,让客户在使用时好像“仍然是在用原来的平台一样”。
在硬件生态上,墨芯也与市面上主流服务器厂商展开合作,比如而在一个月前,墨芯刚刚与浪潮信息签订元脑战略合作协议,通过加入计算生态进行市场推广。而后,墨芯也将与其他服务器提供商以及运营商开放生态合作。
结语:AI芯片产业化验证期,考验创企多兵种作战力
当下,随着摩尔定律逼近物理极限,中国AI芯片创业也进入产业化验证期。AI芯片创业大军中涌现出不同技术流派的玩家,他们中既有几十年经验的芯片老兵,又有学术成果丰硕的AI算法后浪。这展现出中国产业发展至今的人才蓄水池的汩汩活力,是中国攻克芯片卡脖子难关的动力之源。
墨芯人工智能是这批创业大军中的一支多兵种作战队伍,硅谷20年芯片老兵与AI算法科学家共同构建的团队基因,让这支队伍在技术路线选择上也独辟蹊径。稀疏化计算路径,作为AI算法领域认可的一大发展趋势,率先被这家芯片创企实现产品验证。下一步,生态能否快速建立,产品能否快速推广落地,是其面临的新课题。
