








智东西(公众号:zhidxcom)
编译 | ZeR0
编辑 | 漠影
智东西12月9日消息,谷歌母公司Alphabet旗下顶尖AI实验室DeepMind曾因其AI系统AlphaGo击败顶尖人类围棋选手、AlphaStar赢得星际争霸2而爆红全球。本周,它又披露新的游戏AI系统。
与此前开发的游戏系统不同,DeepMind的AI新作Player of Games是第一个在完全信息游戏以及不完全信息游戏中都能实现强大性能的AI算法。完全信息游戏如中国围棋、象棋等棋盘游戏,不完全信息游戏如扑克等。
这是向能够在任意环境中学习的真正通用AI算法迈出的重要一步。
Player of Game在象棋、围棋这两种完全信息游戏和德州扑克、苏格兰场这两种不完全信息游戏中与顶尖AI智能体对战。
从实验结果来看,DeepMind称Player of Games在完全信息游戏中的表现已经达到了“人类顶级业余选手”水平,但如果给予相同资源,该算法的表现可能会明显弱于AlphaZero等专用游戏算法。
在两类不完全信息游戏中,Player of Games均击败了最先进的AI智能体。

论文链接:https://arxiv.org/pdf/2112.03178.pdf
一、深蓝、AlphaGo等AI系统仅擅长玩一种游戏
计算机程序挑战人类游戏选手由来已久。
20世纪50年代,IBM科学家亚瑟·塞缪尔(Arthur L. Samuel)开发了一个跳棋程序,通过自对弈来持续改进其功能,这项研究给很多人带来启发,并普及了“机器学习”这个术语。
此后游戏AI系统一路发展。1992年,IBM开发的TD-Gammon通过自对弈在西洋双陆棋中实现大师级水平;1997年,IBM深蓝DeepBlue在国际象棋竞赛中战胜当时的世界棋王卡斯帕罗夫;2016年,DeepMind研发的AI系统AlphaGo在围棋比赛中击败世界围棋冠军李世石……
 ▲IBM深蓝系统vs世界棋王卡斯帕罗夫
▲IBM深蓝系统vs世界棋王卡斯帕罗夫
这些AI系统有一个共同之处,都是专注于一款游戏。比如塞缪尔的程序、AlphaGo不会下国际象棋,IBM的深蓝也不会下围棋。
随后,AlphaGo的继任者AlphaZero做到了举一反三。它证明了通过简化AlphaGo的方法,用最少的人类知识,一个单一的算法可以掌握三种不同的完全信息游戏。不过AlphaZero还是不会玩扑克,也不清楚能否玩好不完全信息游戏。
实现超级扑克AI的方法有很大的不同,扑克游戏依赖于博弈论的推理,来保证个人信息的有效隐藏。其他许多大型游戏AI的训练都受到了博弈论推理和搜索的启发,包括Hanabi纸牌游戏AI、The Resistance棋盘游戏AI、Bridge桥牌游戏AI、AlphaStar星际争霸II游戏AI等。
 ▲2019年1月,AlphaStar对战星际争霸II职业选手
▲2019年1月,AlphaStar对战星际争霸II职业选手
这里的每个进展仍然是基于一款游戏,并使用了一些特定领域的知识和结构来实现强大的性能。
DeepMind研发的AlphaZero等系统擅长国际象棋等完全信息游戏,而加拿大阿尔伯特大学研发的DeepStack、卡耐基梅隆大学研发的Libratus等算法在扑克等不完全信息游戏中表现出色。
对此,DeepMind研发了一种新的算法Player of Games(PoG),它使用了较少的领域知识,通过用自对弈(self-play)、搜索和博弈论推理来实现强大的性能。
二、更通用的算法PoG:棋盘、扑克游戏都擅长
无论是解决交通拥堵问题的道路规划,还是合同谈判、与顾客沟通等互动任务,都要考虑和平衡人们的偏好,这与游戏策略非常相似。AI系统可能通过协调、合作和群体或组织之间的互动而获益。像Player of Games这样的系统,能推断其他人的目标和动机,使其与他人成功合作。
要玩好完全的信息游戏,需要相当多的预见性和计划。玩家必须处理他们在棋盘上看到的东西,并决定他们的对手可能会做什么,同时努力实现最终的胜利目标。不完全信息游戏则要求玩家考虑隐藏的信息,并思考下一步应该如何行动才能获胜,包括可能的虚张声势或组队对抗对手。
DeepMind称,Player of Games是首个“通用且健全的搜索算法”,在完全和不完全的信息游戏中都实现了强大的性能。
Player of Games(PoG)主要由两部分组成:1)一种新的生长树反事实遗憾最小化(GT-CFR);2)一种通过游戏结果和递归子搜索来训练价值-策略网络的合理自对弈。
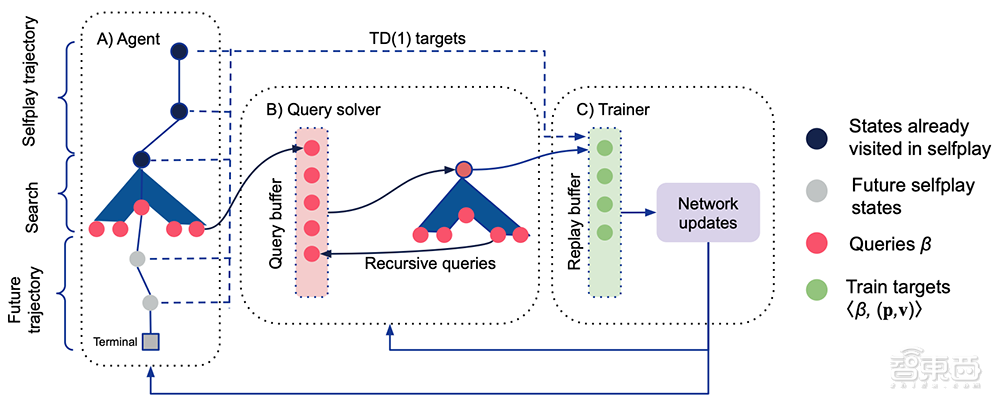 ▲Player of Games训练过程:Actor通过自对弈收集数据,Trainer在分布式网络上单独运行
▲Player of Games训练过程:Actor通过自对弈收集数据,Trainer在分布式网络上单独运行
在完全信息游戏中,AlphaZero比Player of Games更强大,但在不完全的信息游戏中,AlphaZero就没那么游刃有余了。
Player of Games有很强通用性,不过不是什么游戏都能玩。参与研究的DeepMind高级研究科学家马丁·施密德(Martin Schmid)说,AI系统需考虑每个玩家在游戏情境中的所有可能视角。
虽然在完全信息游戏中只有一个视角,但在不完全信息游戏中可能有许多这样的视角,比如在扑克游戏中,视角大约有2000个。
此外,与DeepMind继AlphaZero之后研发的更高阶MuZero算法不同,Player of Games也需要了解游戏规则,而MuZero无需被告知规则即可飞速掌握完全信息游戏的规则。
在其研究中,DeepMind评估了Player of Games使用谷歌TPUv4加速芯片组进行训练,在国际象棋、围棋、德州扑克和策略推理桌游《苏格兰场》(Scotland Yard)上的表现。
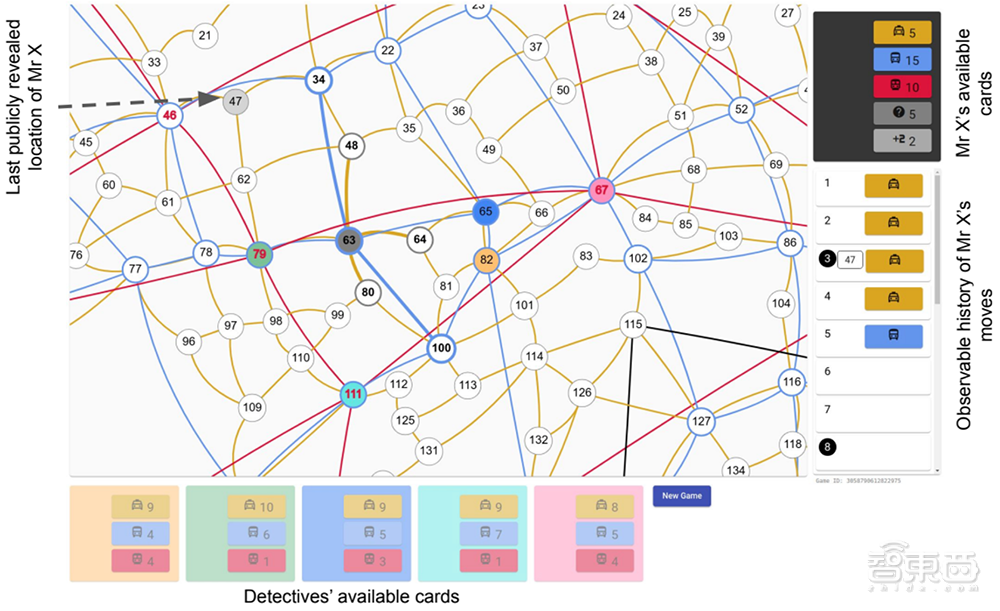 ▲苏格兰场的抽象图,Player of Games能够持续获胜
▲苏格兰场的抽象图,Player of Games能够持续获胜
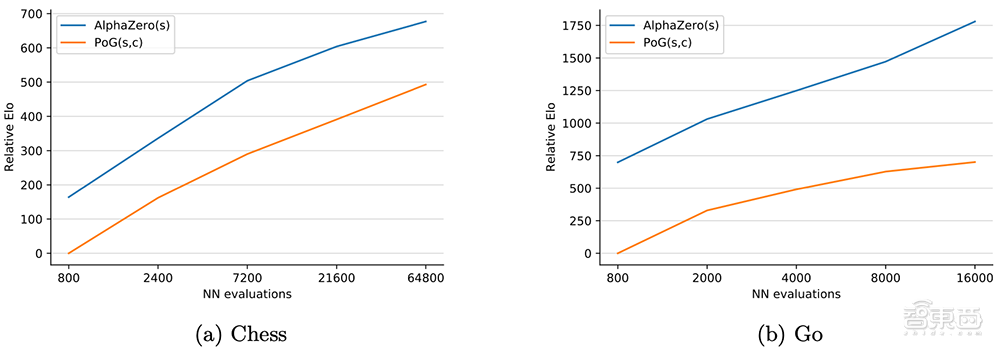
在围棋比赛中,AlphaZero和Player of Games进行了200场比赛,各执黑棋100次、白棋100次。在国际象棋比赛中,DeepMind让Player of Games和GnuGo、Pachi、Stockfish以及AlphaZero等顶级系统进行了对决。
 ▲不同智能体的相对Elo表,每个智能体与其他智能体进行200场比赛
▲不同智能体的相对Elo表,每个智能体与其他智能体进行200场比赛
在国际象棋和围棋中,Player of Games被证明在部分配置中比Stockfish和Pachi更强,它在与最强的AlphaZero的比赛中赢得了0.5%的胜利。
尽管在与AlphaZero的比赛中惨败,但DeepMind相信Player of Games的表现已经达到了“人类顶级业余选手”的水平,甚至可能达到了专业水平。
Player of Games在德州扑克比赛中与公开可用的Slumbot对战。该算法还与Joseph Antonius Maria Nijssen开发的PimBot进行了苏格兰场的比赛。
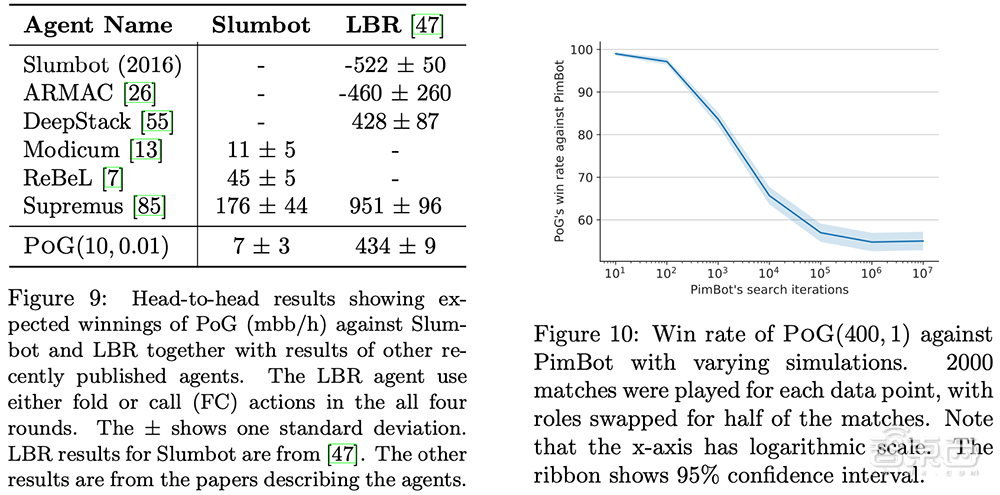 ▲不同智能体在德州扑克、苏格兰场游戏中的比赛结果
▲不同智能体在德州扑克、苏格兰场游戏中的比赛结果
结果显示,Player of Games是一个更好的德州扑克和苏格兰场玩家。与Slumbot对战时,该算法平均每hand赢得700万个大盲注(mbb/hand),mbb/hand是每1000 hand赢得大盲注的平均数量。
同时在苏格兰场,DeepMind称,尽管PimBot有更多机会搜索获胜的招数,但Player of Games还是“显著”击败了它。
三、研究关键挑战:训练成本太高
施密德相信Player of Games是向真正通用的游戏系统迈出的一大步。
实验的总体趋势是,随着计算资源增加,Player of Games算法以保证产生更好的最小化-最优策略的逼近,施密德预计这种方法在可预见的未来将扩大规模。
“人们会认为,受益于AlphaZero的应用程序可能也会受益于游戏玩家。”他谈道,“让这些算法更加通用是一项令人兴奋的研究。”
当然,倾向于大量计算的方法会让拥有较少资源的初创公司、学术机构等组织处于劣势。在语言领域尤其如此,像OpenAI的GPT-3这样的大型模型已取得领先性能,但其通常需要数百万美元的资源需求,这远超大多数研究小组的预算。
即便是在DeepMind这样财力雄厚的公司,成本有时也会超过人们所能接受的水平。
对于AlphaStar,公司的研究人员有意没有尝试多种构建关键组件的方法,因为高管们认为训练成本太高。根据DeepMind披露的业绩文件,它在去年才首次盈利,年收入达到8.26亿英镑(折合约69亿人民币),获得4380万英镑(折合约3.67亿人民币)的利润。从2016年~2019年,DeepMind共计亏损13.55亿英镑(折合约113亿人民币)。
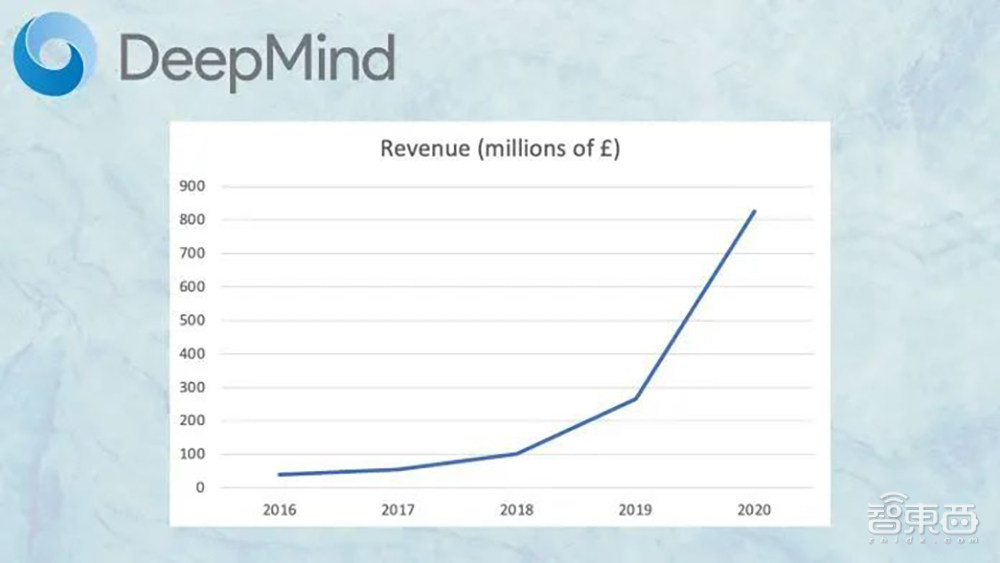
据估计,AlphaZero的训练成本高达数千万美元。DeepMind没有透露Player of Games的研究预算,但考虑到每个游戏的训练步骤从数十万到数百万不等,这个预算不太可能低。
结语:游戏AI正助力突破认知及推理挑战
目前游戏AI还缺乏明显的商业应用,而DeepMind的一贯理念是借其去探索突破认知和推理能力所面临的独特挑战。近几十年来,游戏催生了自主学习的AI,这为计算机视觉、自动驾驶汽车和自然语言处理提供了动力。
随着研究从游戏转向其他更商业化的领域,如应用推荐、数据中心冷却优化、天气预报、材料建模、数学、医疗保健和原子能计算等等,游戏AI研究对搜索、学习和博弈推理的价值愈发凸显。
“一个有趣的问题是,这种水平的游戏是否可以用较少的计算资源实现。”这个在Player of Games论文最后中被提及的问题,还没有明确的答案。
来源:VentureBeat,arVix
