








智东西(公众号:zhidxcom)
作者 | 心缘
编辑 | 漠影
智东西8月31日报道,在INTERSPEECH大会上,NVIDIA展示了其对话式AI最新研究成果——开发者和创作者可使用最先进的对话式AI模型进行具有表现力的语音合成,为角色、虚拟助手和个性化形象生成声音。
语音领域顶会INTERSPEECH汇聚了1000多名研究人员,展示在语音技术方面的突破性进展。在本周会议上,NVIDIA研究院将展示对话式AI模型架构及供开发者使用的完全格式化语音数据集。
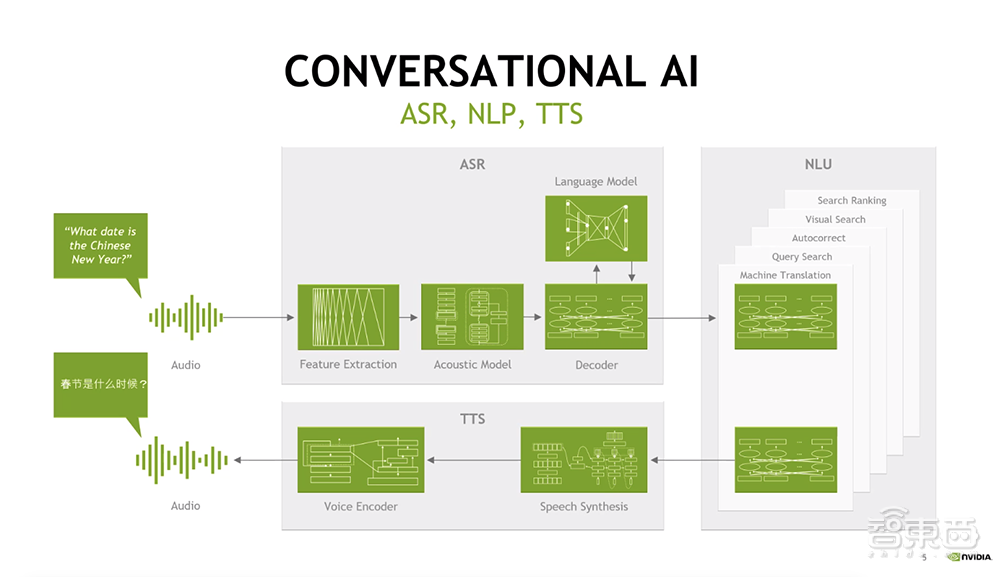
一、AI合成语音与人声的差距逐渐缩小
如今合成语音逐渐走入人们的日常生活,从单调的机器人呼叫、传统GPS导航系统转变为智能手机和智能音箱中愈发拟人化的虚拟助手。
此前AI合成语音与我们在日常对话和媒体中听到的人类语音仍有差距,很难模仿人类说话时的复杂节奏、音调和音色。而这一差距正迅速缩小。
NVIDIA研究人员正在创建高质量、可控制的语音合成模型和工具,这些模型和工具能够捕捉人类语音的丰富性,并且不会出现音频杂音。
这些模型可实现为银行和零售商的自动客户服务热线配音、使视频游戏和书籍中的人物变得栩栩如生,并为数字化身提供实时语音合成。
具有表现力的语音合成只是NVIDIA研究院在对话式AI领域的重点工作之一。该领域还包括自然语言处理、自动语音识别、关键词检测、音频增强等。
这些前沿工作经过优化后可以在NVIDIA GPU上高效运行,其中的一些工作已通过NVIDIA NeMo工具包开放源代码,可在NVIDIA NGC容器和其他软件中心获得。
二、AI为视频配音,还能将男声切换成女声
NVIDIA的语音合成模型已经被应用到I AM AI系列视频中,为这个介绍重塑各行业全球AI创新者的系列视频制作了生动的解说。
不久之前,这些视频还都是由人类配音的。以前的语音合成模型对合成声音节奏和音调的控制十分有限,因此AI配音无法唤起观众的情感反应,只有富有感情的人类声音才能做到这一点。
过去一年,NVIDIA文本-语音研究团队开发出更强大、更可控的语音合成模型(如RAD-TTS),解决了上述难题。
NVIDIA在SIGGRAPH Real-Time Live比赛中的获奖演示即采用这个模型。通过使用人类语音音频来训练文本-语音模型,RAD-TTS可以将任何文本转换成说话人的声音。
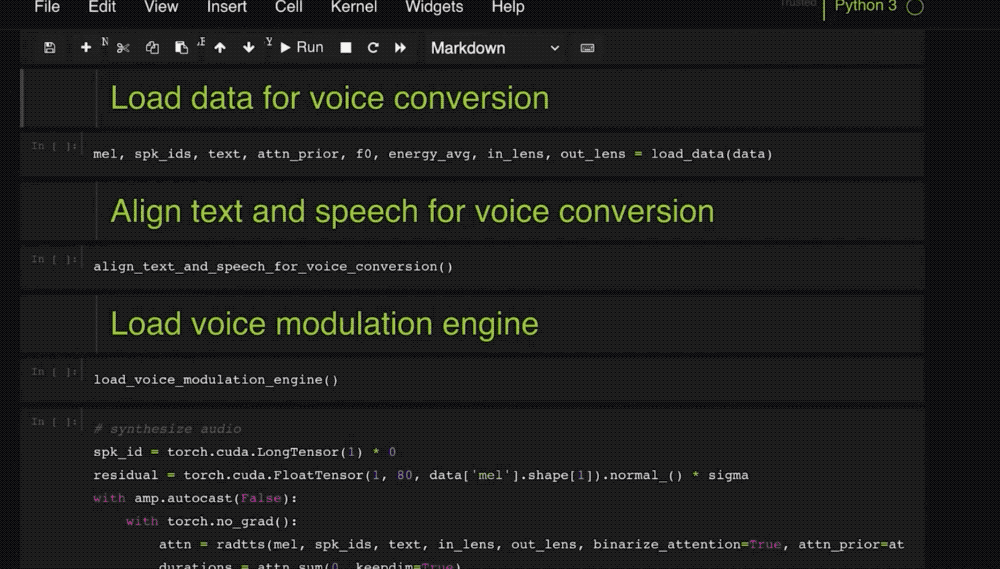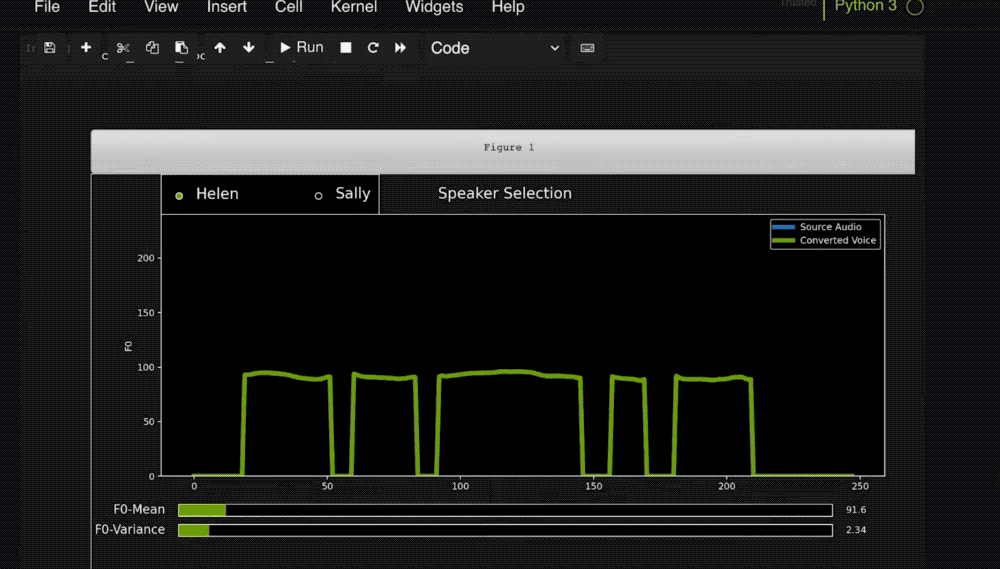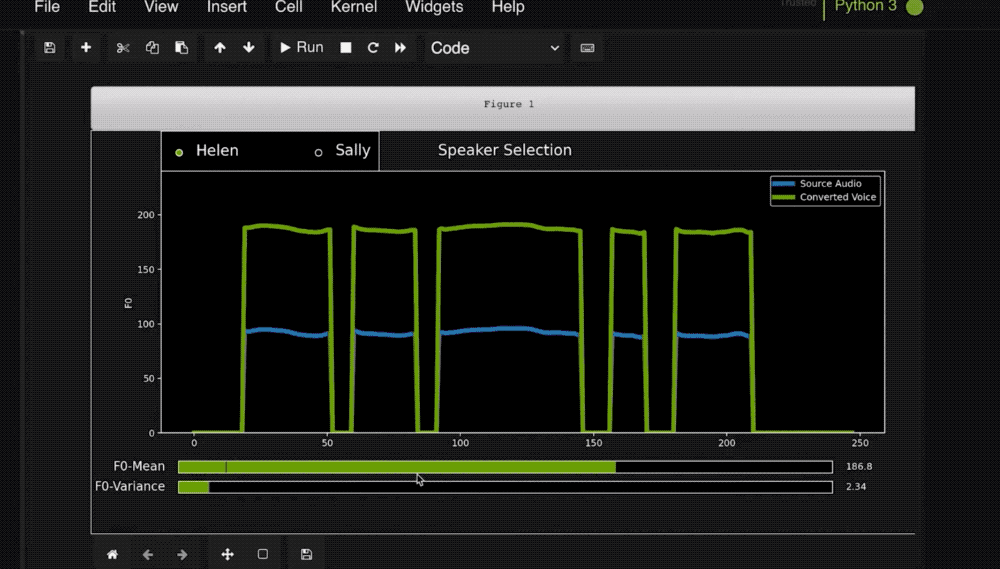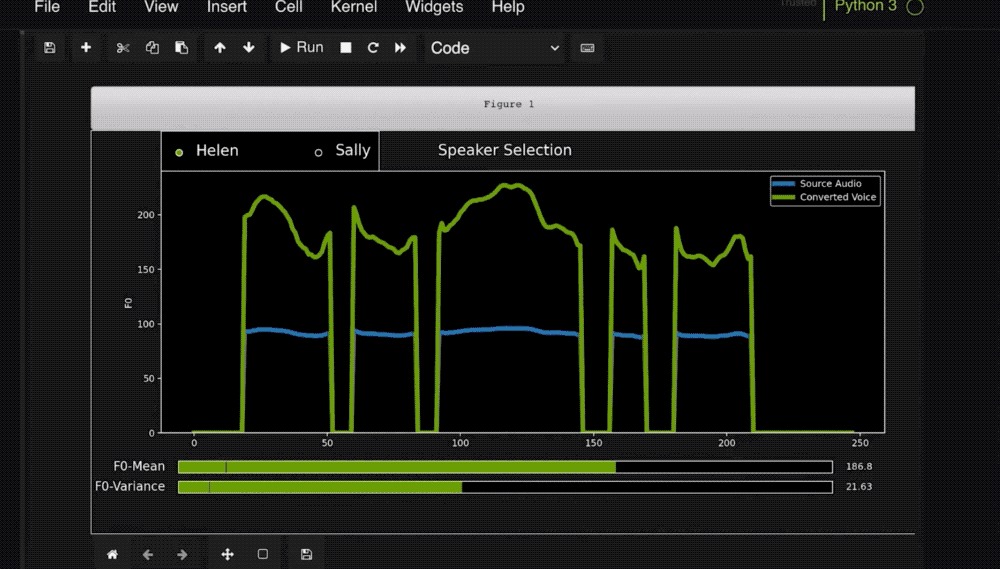
该模型的另一项功能是语音转换,即使用一名说话人的声音讲述另一名说话人的话或歌唱。
RAD-TTS界面的灵感来自于将人的声音作为一种乐器这一创意。用户可以使用它对合成声音的音调、持续时间和强度进行精细的帧级控制。
通过这个接口,视频制作者可以在录制中自行阅读视频文本,然后使用AI模型将他作为男叙述者的语音转换成女叙述者的声音。
制作者可使用这个基准叙述,像指导配音演员一样指示AI,比如通过调整合成语音来强调特定的词语、修改叙述节奏以更好地表达视频中的语气等。
该AI模型的能力已超出了配音工作的范围:文本-语音转换可以用于游戏、为有声音障碍的人提供帮助、或帮助用户用自己的声音进行不同语言的叙述。它甚至能重现标志性歌手的表演,不仅可以匹配歌曲的旋律,还能匹配人声背后的情感表达。
IAM AI系列视频链接:https://www.youtube.com/playlist?list=PLZHnYvH1qtObE_PjzaAFqS_CpmumGx5cW
三、为AI开发者和研究者提供语音SDK
为了方便企业及研究人员的应用,NVIDIA提供了GPU加速的语音SDK。
NVIDIA NeMo是一款用于GPU加速对话式AI的开源Python工具包。NeMo中易于使用的API和预训练模型能帮助研究人员开发和自定义用于文本-语音转换、自然语言处理和实时自动语音识别的模型。
其中几个模型是在NVIDIA DGX系统上使用数万小时的音频数据训练而成。开发者可根据自己的使用情况对任何模型进行微调,用NVIDIA Tensor Core GPU上的混合精度计算加快训练速度。
NVIDIA NeMo还通过NGC提供在Mozilla Common Voice上训练的模型,该数据集拥有76种语言、近14000小时的众包语音数据。其目标是在NVIDIA的支持下,通过全球最大的开源数据语音数据集实现语音技术的普及化。
包括NeMo研究进展在内,本周的INTERSPEECH大会期间,NVIDIA嘉宾将带来如下演讲:

《兼容任何场景的多麦克风语音去混响》
论文链接:https://arxiv.org/abs/2010.11875
《 SPGISpeech:用于完全格式化端到端语音识别的5000小时转录金融音频》
论文链接:https://arxiv.org/abs/2104.02014
《Hi-Fi多讲话者英语TTS数据集》
论文链接:https://arxiv.org/abs/2104.01497
《TalkNet 2:用于语音合成(具有明确音高和持续时间预测)的非自回归深度可分离卷积模型》
论文链接:https://arxiv.org/abs/2104.08189
《使用稀疏随机三元矩阵压缩一维时间通道可分离卷积》
论文链接:https://arxiv.org/abs/2103.17142
《NeMo逆向文本正则化:从开发到生产》
论文链接:https://arxiv.org/abs/2104.05055
结语:NVIDIA持续推进AI语音技术前沿研究
NVIDIA正在进行语音技术各个领域的研究,除了本文重点提及的TTS和语音再合成外,NVIDIA在ASR、语音增强与去噪、音频压缩、数据集、文本规范化、基本建模技术方面有新研究进展。
由I AM AI视频的配音示例,我们可以延展出更多语音合成技术的应用场景。尤其在愈发昂贵的视频游戏录制方面,越来越成熟的语音合成技术不仅能将配音从一种语言翻译成另一种语言,同时能保证声音情感内容的充沛。此外,语音合成技术也在零售、客服、医疗保健、汽车等日益由语音驱动的场景中大有可为。
当然,迄今对话式AI模型的突破仍很困难,预计在相当长一段时间都将是前沿研究领域。NVIDIA也在着力研究解决交互延迟等难题,我们也期待看见此类技术快速进化,以更加拟人化的方式在更多行业及人们生活中发挥价值。
