








智东西(公众号:zhidxcom)
编辑 | 心缘
智东西4月25日报道,今日,华为云推出盘古系列超大规模预训练模型,包括全球最大视觉(CV)预训练模型和全球最大中文语言(NLP)预训练模型。

全球最大视觉(CV)预训练模型包含30亿参数,首次兼顾了图像判别与生成能力,既能提升测试精度,又能平均节约90%以上研发成本。
全球最大中文语言(NLP)预训练模型由华为云、循环智能、鹏城实验室联合开发,包含千亿参数、40TB训练数据,刷新了CLUE三项榜单世界纪录。
后续,华为云还将陆续发布多模态、科学计算等超大预训练模型。
预训练大模型是解决AI应用开发定制化和碎片化的重要方法。华为云人工智能领域首席科学家、IEEE Fellow田奇称,华为云盘古大模型可以实现一个AI大模型在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,并使用ModelArts平台,让AI开发由作坊式转变为工业化开发的新模式。
 ▲华为云人工智能领域首席科学家田奇介绍盘古大模型
▲华为云人工智能领域首席科学家田奇介绍盘古大模型
一、最大中文语言预训练模型:千亿参数、40TB训练数据
盘古NLP大模型是全球最大的千亿参数中文语言预训练模型,涉及千亿参数、40TB中文文本训练数据,对算法、算力、海量数据处理、并行优化都提出了很大挑战。
在算法方面,华为云的算法团队与循环智能(Recurrent AI)的NLP团队经过数月联合攻关,突破了大模型微调的难题。
在算力方面,鹏城实验室的国内最大规模AI训练集群鹏城云脑II,为盘古NLP大模型训练提供了强大的AI算力基础。
该模型通过在预训练阶段引入基于Prompt的任务等多项创新方案,经由行业数据的样本调优,提升模型在场景中的应用性能。
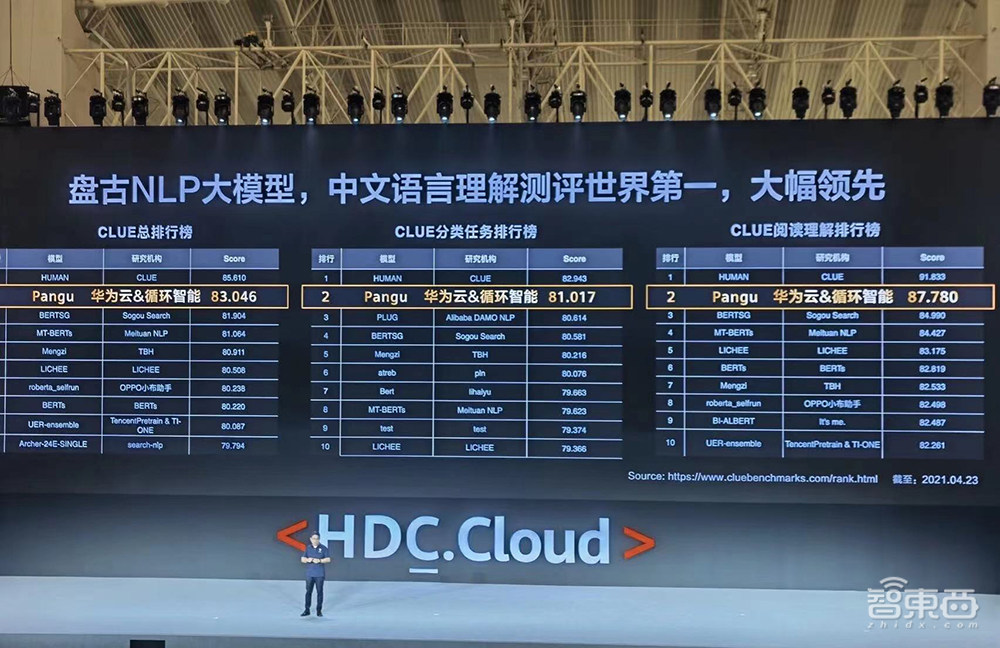
具体来看,盘古NLP大模型在3个方面实现了突破性进展:
1、具备领先的语言理解和模型生成能力
在权威的中文语言理解评测基准CLUE榜单中,盘古NLP大模型的总成绩、分类任务、阅读理解单项均排名第一,刷新三项榜单纪录,总成绩得分83.046,向人类水平(85.61)迈进了一大步。
在NLPCC2018文本摘要任务中,盘古NLP大模型取得了Rouge平均分0.53的业界最佳成绩,超越第二名60%。
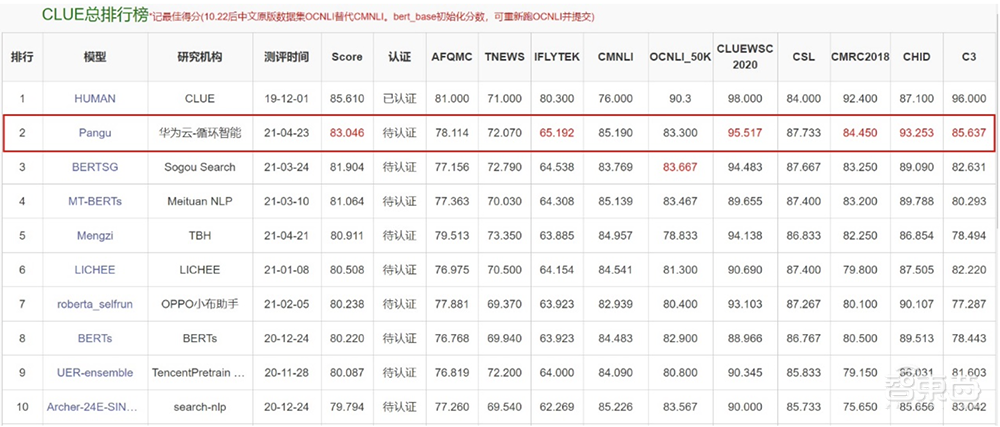 ▲盘古NLP大模型位列CLUE榜单总排行榜第一
▲盘古NLP大模型位列CLUE榜单总排行榜第一
2、让大模型更好融入行业知识
盘古NLP大模型在预训练阶段沉淀了大量的通用知识,既能做理解又能做生成。
除了能像GPT-3等仅基于端到端生成的方式以外,该模型还可以通过少样本学习对意图进行识别,转化为知识库和数据库查询,解决以往大模型难融入行业知识和数据的问题。
该模型通过功能的模块化组合支持行业知识库和数据库的嵌入,进而对接行业经验,使能全场景的快速适配与扩展。
比如在华为云和循环智能合作构建的金融客服场景中,盘古NLP大模型能更好地赋能销售环节的实时沟通辅助系统,帮助服务人员快速提升业务水平,重塑消费者体验。
3、小样本学习任务超GPT系列
盘古NLP大模型采用大模型小样本调优的路线,实现了小样本学习任务上超越GPT系列。
比如在客户需求分析场景中,使用盘古NLP大模型生产语义标签时,实测得到目标结果所需的样本量仅为GPT系列模型的1/10,即AI生产效率可提升10倍。
由于盘古团队在预训练阶段加入了基于 prompt 的任务,大幅降低微调难度,解决以往大模型难为不同行业场景进行微调的问题。
在下游数据充足时,微调难度的降低使得模型可以随着数据变多而持续优化;在下游数据稀缺时,微调难度的降低使得模型的少样本学习效果得到显著提升。
比如,在企业借助沟通内容判断客户购买意向,以找出更多目标客户从而提升转化率的场景中,实测盘古NLP大模型相比GPT系列模型可提升27%的成单转化率。

二、最大视觉预训练模型:30亿参数,兼顾图像判别与生成能力
盘古CV大模型包含超过30亿参数,是目前业界最大的视觉预训练模型。
该模型首次兼顾了图像判别与生成能力,从而能够同时满足底层图像处理与高层语义理解需求,同时能够方便融合行业知识微调,快速适配各种下游任务。
性能方面,盘古CV大模型在ImageNet 1%、10%数据集上的小样本分类精度上均达到目前业界最高水平(SOTA)。
盘古CV大模型致力于解决AI工程难以泛化和复制的问题,开创AI开发工业化新模式,大大节约研发成本;并提供模型预训练、微调、部署和迭代的功能,形成了AI开发完整闭环,极大提升AI开发效率。
目前,盘古CV大模型已经在医学影像、金融、工业质检等100余项实际任务中得到了验证,不仅大幅提升了业务测试精度,还能平均节约90%以上的研发成本。
三、助力无人机电力智能巡检,CV模型开发成本降低90%
国网重庆永川供电公司是国内早期应用无人机电力智能巡检技术的电网企业。
华为云与国网重庆永川供电公司合作,在无人机智能巡检AI模型开发上,相较传统开发模式,华为云盘古CV大模型展现出明显的优势。
传统的无人机智能巡检AI模型开发主要面临两大挑战:一是如何对海量数据进行高效标注;二是缺陷种类多达上百种,需要数十个AI识别模型,开发成本高。
在数据标注方面,盘古CV大模型利用海量无标注电力数据进行预训练,并结合少量标注样本微调的高效开发模式,独创性地提出了针对电力行业的预训练模型,使得样本筛选效率提升约30倍,筛选质量提升约5倍,以永川每天采集5万张高清图片为例,可节省人工标注时间170人天。
在模型通用性方面,结合盘古搭载的自动数据增广以及类别自适应损失函数优化策略,可以做到一个模型适配上百种缺陷,替代原有20多个小模型,极大地减少了模型维护成本,平均精度提升18.4%,模型开发成本降低90%。
结语:盘古大模型背后的基础平台支撑
除了参与到具体模型开发外,华为的底层软件、训练框架、ModelArts平台协同优化,也对充分释放算力和达成全栈性能最优起到关键作用。

首先,针对底层算子性能,基于华为CANN采用了算子量化、算子融合优化等技术,将单算子性能提升30%以上。
其次,华为MindSpore创新性地采用了“流水线并行、模型并行和数据并行”的多维自动混合并行技术,大幅降低了手动编码的工作量,并提升集群线性度20%。
华为云ModelArts平台提供E级算力调度,同时结合物理网络拓扑,提供动态路由规划能力,为大模型训练提供了最优的网络通信能力。
此外,借助ModelArts平台的高效处理海量数据能力,仅用7天就完成了40TB文本数据处理。
截至目前,华为云已经在全国10多个行业超过600个项目进行了人工智能落地和实践,帮助城市、交通、医疗、钢铁、纺织、能源、金融等行业智能升级。未来,华为云还将持续通过技术创新来驱动产业智能升级。
