








当你拥有一台搭载了2块NVIDIA最新显卡NVIDIA® Quadro RTX™ 8000 GPU的桌面工作站的时候,您想做什么?
我是一名自由AI开发者,喜欢在业余时间去做一些AI模型的开发实现,尤其热衷于一些好玩的AI模型,比如:基于YOLO的行人姿态估计、基于强化学习的贪吃蛇、以及最近比较火的“蚂蚁呀嘿”等等。这次在惠普的支持下,本人有幸拿到了一款HP Z4 G4工作站并对其进行深度学习实验测试。下面我们就一起来看一看这款拥有两块RTX 8000工作站的性能体现吧。
一、AI虐我千百遍
众所周知,人工智能有三大要素:数据、算法和算力。想要做AI模型的开发,离不开这三个要素。
数据和算法目前都有一些开放的资源可用,如GitHub上就有很多的开源项目,也有开源的数据集MNIST、flower102、COCO、Pacal VOC等等,这些只要科学上网就可以下载,但算力就比较难了。虽然也有一些免费的云算力资源,但在使用时不仅需要排队等候资源分配,还需要考虑分配资源是否足够、训练是否花费很长时间、网络传输问题等等,十分的不方便。因此,拥有一台可独占的算力设备,对于AI开发者来说尤为重要。
随着深度学习的全面普及与发展,GPU、DPU、TPU、NPU、BPU等各类计算芯片名词不断涌现。而NVIDIA CUDA的出现,使得AI开发者可以通过GPU超强的并行计算能力实现通用计算,从而加速AI模型的训练开发,因此GPU也是目前主流的算力芯片。现阶段比较受开发者欢迎的GPU有NVIDIA® 2080Ti、Titan V等。那么我们来看一下这些主流NVIDIA GPU在深度学习上的一些性能表现。
 ▲图表 1:不同GPU在不同网络上的吞吐量
▲图表 1:不同GPU在不同网络上的吞吐量
 ▲图表 2:在FP16和FP32上加速比
▲图表 2:在FP16和FP32上加速比
//数据来源,点击查看
以上两张图片的数据来自Lambda的评测,从中可以看出,不管是从吞吐量还是不同精度的加速比,其主流的GPU都能够提供很大的算力支持。那么面对这样的性能体现,NVIDIA® Quadro RTX™ 8000又有什么特别之处呢?
在这里,我汇总了Quadro RTX 8000,GeForce RTX 2080Ti、2080以及Titan RTX的CUDA Core、Tensor Core、RT Core和GPU Memory的标准规格,从硬件配置上我们先看看区别在哪。
 ▲图表 3:RTX 8000与主流GPU的参数对比
▲图表 3:RTX 8000与主流GPU的参数对比
从上图标中的数据中可以看出,NVIDIA® Quadro RTX™ 8000无论是从CUDA Core、Tensor Core还是RT Core和GPU Memory的配置上,都远高于其他GPU。其中CUDA Core是计算单元,可以实现高速浮点运算以及大型矩阵运算。Tensor Core可以大幅度加速深度学习的训练和推理。RT Core可以用于生成反射和阴影。GPU Memory则可以增大模型训练的Batch size大小,节省训练的时间。由此可见Quadro RTX™ 8000性能远远高于其他GPU。
二、专业图形显卡,双路强悍性能
NVIDIA® Quadro系列是NVIDIA面向专业图形领域所推出的芯片,集可编程着色技术、实时光线追踪技术、人工智能于一身。而NVIDIA® Quadro RTX™ 8000也是NVIDIA推出的一款由NVIDIA Turing架构和NVIDIA RTX平台支持的GPU,更是配置了48GB高速GDDR6显存和NVIDIA NVLink™,并且拥有4608个CUDA Core、576个Tensor Core、72个RT Core和48G的高速GDDR6显存,提供了16.3TFLOPS的FP32性能。
 ▲图表 4:数据来源:点击查看
▲图表 4:数据来源:点击查看
而HP Z4 G4工作站内置了2块Quadro RTX 8000显卡,通过NVLink HB桥接器连接,可以实现高达100GB/s的带宽,以及96GB的GDDR6显存,从而在能够保持GPU之间正常通讯的前提下支持更大AI任务的工作负载。
 ▲图表 5:HP Z4 G4中两块Quadro RTX 8000截面图
▲图表 5:HP Z4 G4中两块Quadro RTX 8000截面图
NVLink是NVIDIA开发推出的一种总线及其通信技术,采用点对点结构、串列传输,用户CPU和GPU、GPU和GPU之间连接。与传统的PCle技术相比,NVLink可以提供更快速的多GPU通信方案,实现显存和性能的扩展,可以最大限度的满足计算机视觉任务的负载需求。
 ▲图表 6:https://www.nvidia.cn/design-visualization/nvlink-bridges/
▲图表 6:https://www.nvidia.cn/design-visualization/nvlink-bridges/
三、蚂蚁虽小,但有力千钧
前面对比了NVIDIA® Quadro RTX™ 8000和其他主流用于深度学习的GPU性能,我们看到了Quadro RTX™ 8000的超强性能。而搭载了两块Quadro RTX™ 8000 GPU的HP Z4 G4工作站的性能,就更让人期待了。
不过说真的,当我拿到HP Z8 G4的时候,首先让我惊叹的不是2块NVIDIA® Quadro RTX 8000可能带来的性能,而是它的体积是真的“小”。作为一个提供超强算力的AI工作站,不应该是“魁梧”的吗?
 ▲图表 7:HP Z4 G4工作站截面图
▲图表 7:HP Z4 G4工作站截面图
话说回来,AI模型的训练推理看的还是性能,虽然外形“不占优势”,但还是很期待性能。
1、实验说明
关于实验之前的说明,因为本人主要做计算机视觉方向的研究,因此主要会通过一些计算机视觉领域的任务对HP Z4 G4的不同参数进行不同角度的实验对比。同时因为是个人实验,所以实验中如果有什么错误的地方大家多多理解。
(1) 视觉任务、算法和数据集的选择
 ▲图表 8:实验说明
▲图表 8:实验说明
在实验任务的选择上,我选择了图像分类和目标检测这两个计算机视觉基本任务,以及一些图像分类算法:ResNet和VGG,目标检测算法:“双刀流”Faster RCNN,以及图像分割的U-Net等经典算法分别进行实验。
(2) 算法实现,深度学习框架的选择
算法的实现上,我从众多框架中选择了TensorFlow和PyTorch这两个主流的框架分别进行实现。
TensorFlow是谷歌大脑于 2015 年冬发布的第二代机器学习框架 。而Facebook于 2015年秋也发布了自家的深度学习框架PyTorch。由于 PyTorch 的纯 Python 式开发风格,其一经面世就受到了 Python 社区的热烈欢迎。TensorFlow和PyTorch也是目前比较主流的两个机器学习框架。
(3) HP ZG G4的配置及评测指标
首先是HP Z4 G4本机的配置以及深度学习环境的配置清单。
 ▲图表 9:HP Z4 G4配置
▲图表 9:HP Z4 G4配置
 ▲图表 10:深度学习环境配置清单
▲图表 10:深度学习环境配置清单
在评测的指标上,我们将在实验中记录训练和推理过程中的GPU 的利用率、内存利用率、GPU 内存占用,CPU 利用率、CPU 内存占用和训练/推理速度等数据,以0.5秒为间隔,然后计算平均利用率。同时因为HP Z4 G4内置2块GPU,因此会对单卡和多卡单独进行测试。同时实验中将默认使用FP32精度,batch_size=128进行训练与推理。
2、 实验结果
在这里,我将展示不同视觉任务中,不同框架的算法训练、推理性能和资源利用率。并且会针对ResNet50网络的训练和测试进行单卡和双卡的测试。
(1) 实验1:图像分类任务:ResNet50 + flower102的训练和推理
 ▲图表 11:ResNet50的训练性能和资源利用率
▲图表 11:ResNet50的训练性能和资源利用率
 ▲图表 12:ResNet50的推理性能和资源利用率
▲图表 12:ResNet50的推理性能和资源利用率
(2) 实验2:图像分类任务:VGG16 + ImageNet的训练和推理
 ▲图表 13:VGG16的训练、推理性能和资源利用率
▲图表 13:VGG16的训练、推理性能和资源利用率
(3) 实验3:目标检测任务:Faster RCNN + Pascal VOC的训练和推理
 ▲图表 14:Faster -RCNN的训练、推理性能和资源利用率
▲图表 14:Faster -RCNN的训练、推理性能和资源利用率
(4) 实验4:图像分割任务:U-Net + KITS的训练和推理
 ▲图表 15:U-Net的训练、推理性能和资源利用率
▲图表 15:U-Net的训练、推理性能和资源利用率
3、结果分析
我们通过对上面数据的可视处理,进一步对结果进行分析。 图16和图17展示的是不同模型在训练和推理时的性能体现。整体上来看,无论是从训练性能还是推理的性能,TensorFlow都略胜于PyTorch。
 ▲图表 16:不同模型的训练性能
▲图表 16:不同模型的训练性能
 ▲图表17:不同模型的推理性能
▲图表17:不同模型的推理性能
图17展示的是ResNet50在不同框架中的单卡训练和多卡训练的性能体现,相比于PyTorch多卡性能2倍的提升,TensorFlow的多卡性能提升并不大。
 ▲图表 18:ResNet50在不同框架上的单卡训练和多卡训练
▲图表 18:ResNet50在不同框架上的单卡训练和多卡训练
图18展示的是TensorFlow框架下,不同网络分别在训练和推理时的GPU利用率的情况。由此发现RenNet50和VGG16在推理阶段的GPU利用率比较高,而Faster RCNN和U-Net在训练阶段的GPU利用率比较高。
 ▲图表 19:TensorFlow下不同网络在不同阶段的GPU利用率
▲图表 19:TensorFlow下不同网络在不同阶段的GPU利用率
图19是不同网络在训练过程中的显存使用情况。从中可以看出,随着任务复杂度的提高,虽然TensorFlow和PyTorch对网络进行了优化,但显存占用明显变大。
 ▲图表20:不同网络在训练过程中的显存使用
▲图表20:不同网络在训练过程中的显存使用
图20展示的是不同网络在训练过程中的CPU使用情况。从数据图标中可以看出,PyTorch在ResNet50和VGG16中占用的CPU相对较少,在Faster RCNN和U-Net中占用的较多。
 ▲图表 21:不同网络在训练过程中的CPU利用率
▲图表 21:不同网络在训练过程中的CPU利用率
需要说明的是,以上实验的代码都来自于GitHub上的开源项目,而每个项目本身可能存在一定的优化,因此这里的实验结果只作为一个实验结果参考。
从上面的实验结果中,我们可以发现,无论是TensorFlow还是PyTorch,虽然本身也在做一些相应的优化,但在实际的训练和推理过程中,还是非常依赖硬件环境,如显存、内存等等。单卡的性能远不及多卡性能,并且TensorFlow默认情况下是调用所有的显卡进行计算的。
而且在整个实验的过程中,搭载了两块NVIDIA Quadro RTX 8000 GPU的HP Z4 G4工作站,无论是面对比较小的flower数据集,还是很大的ImageNet、COCO数据集,从各种性能要求上都可以满足正常的训练和推理需要。
4、我待AI如初恋
AI领域不只有图像分类、目标检测和图像分割这样的视觉任务,也有很多前沿的研究领域,如动作迁移、强化学习,姿态检测与跟踪等有趣的研究。不过这些模型的训练和推理往往需要很大的算力支持,这次趁着有HP Z4 G4工作站的算力支持,我也跑了一些比较好玩的模型,一起来看看吧。
– 基于强化学习算法DQN实现的贪吃蛇
项目地址:https://github.com/zhangbinchao/snake_dqn
深度强化学习模型是在强化学习框架的基础上,将感知环境的部分用CNN卷积神经网络进行构建。这也是当前游戏AI发展的趋势,因为游戏的复杂度越来越高,因此模型训练的消耗也越来越大,硬件要求也不断增高。
在本次模型的训练中,我们在设置的12*12的游戏空间中一共训练了100万次,共花费了大约4个小时。可能是训练次数太少的问题,最后的训练结果并不太理想,最优成绩也只有8。如果增加训练次数的话,应该可以取得更好的结果。
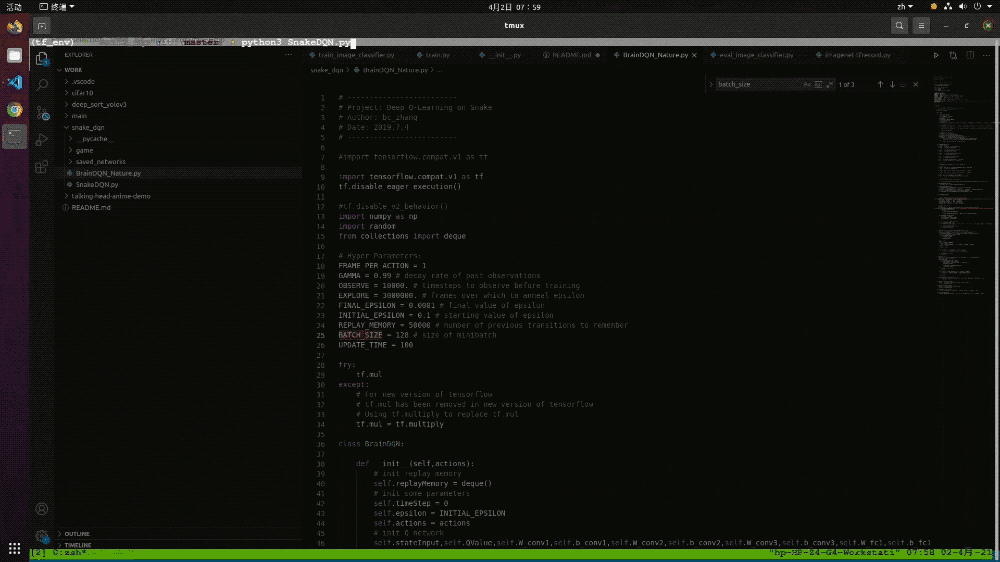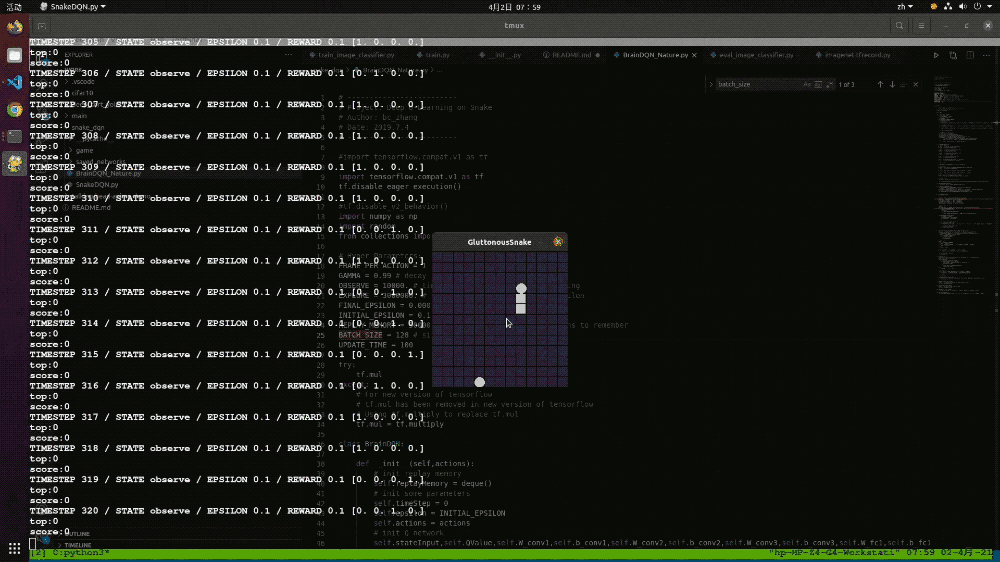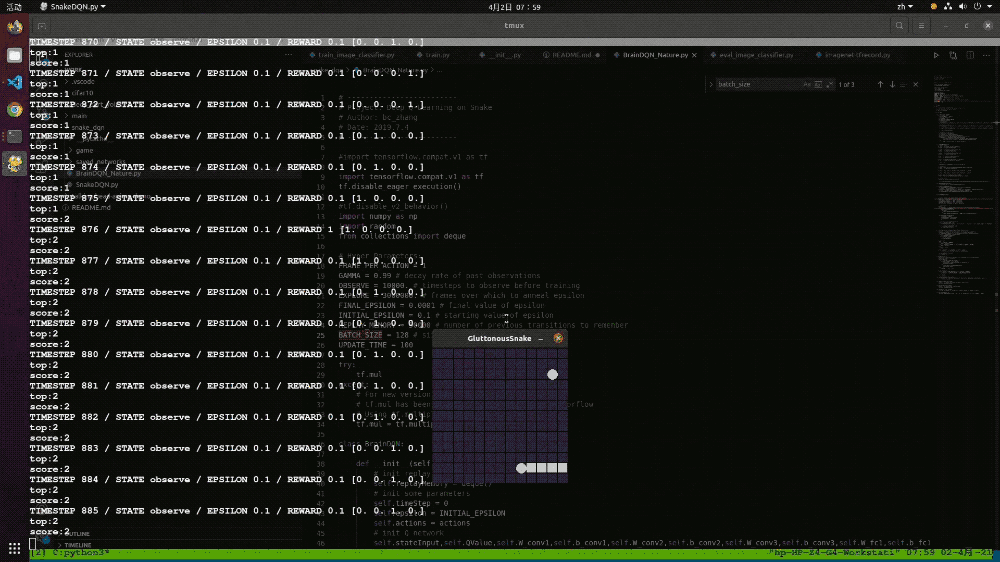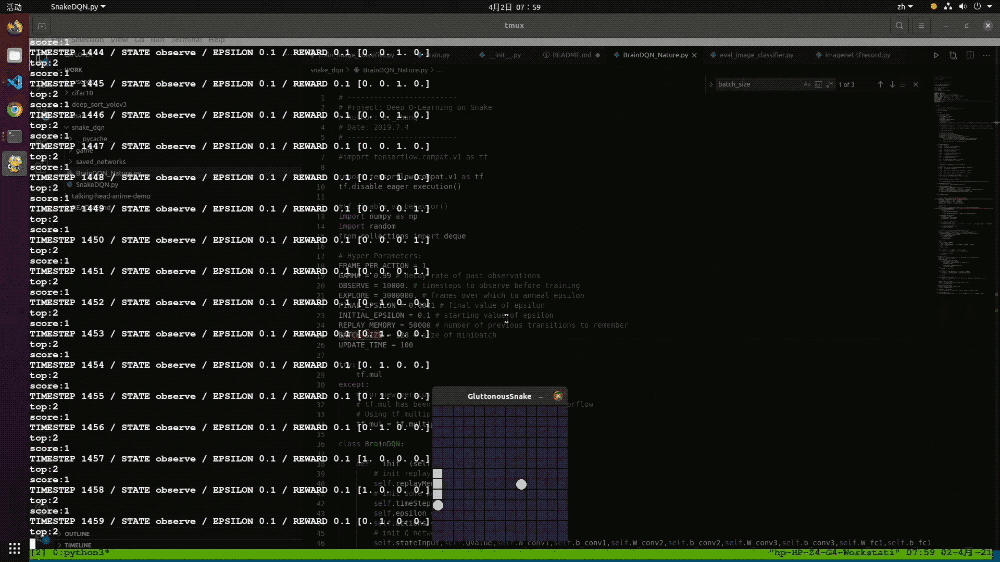 ▲图表22:基于强化学习算法DQN实现的贪吃蛇
▲图表22:基于强化学习算法DQN实现的贪吃蛇
– 动作迁移模型
项目地址:https://pkhungurn.github.io/talking-head-anime-demo/
还记得最近网上比较火的“蚂蚁呀嘿”吗?其背后的原理就是动作迁移。而在这个项目中,我们将视频换成了摄像头,以方便实时的进行动作迁移。模型的整个工作流程是这样的:首先对摄像头的人物进行关键点检测定位,然后和目标图像进行关键点的匹配,这样当摄像头里面的任务进行动作变化的时候,其目标图像也会进行相应的动作变化,这就是动作迁移。以下就是该模型的效果展示,从中可以看出其运行起来还是比较流畅的。
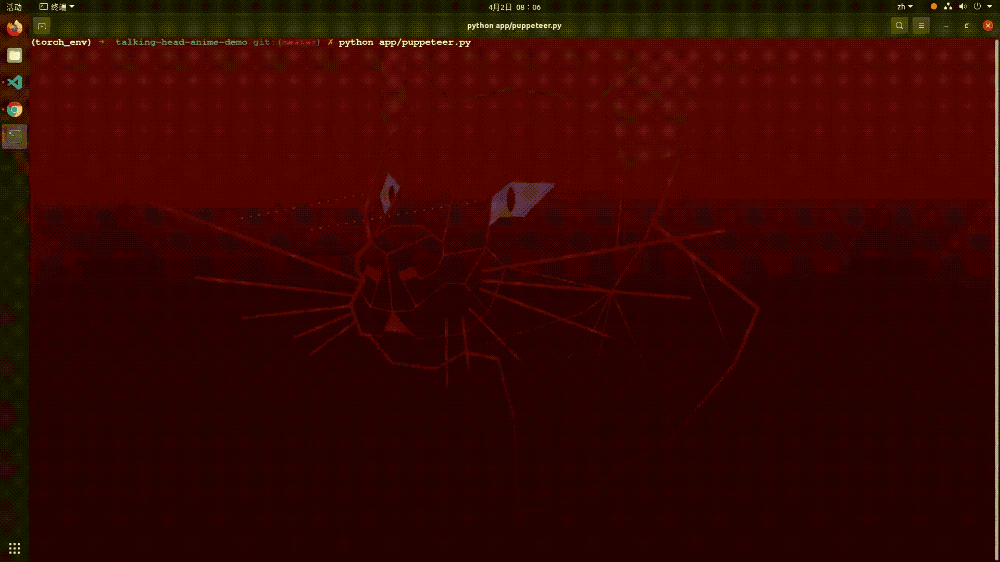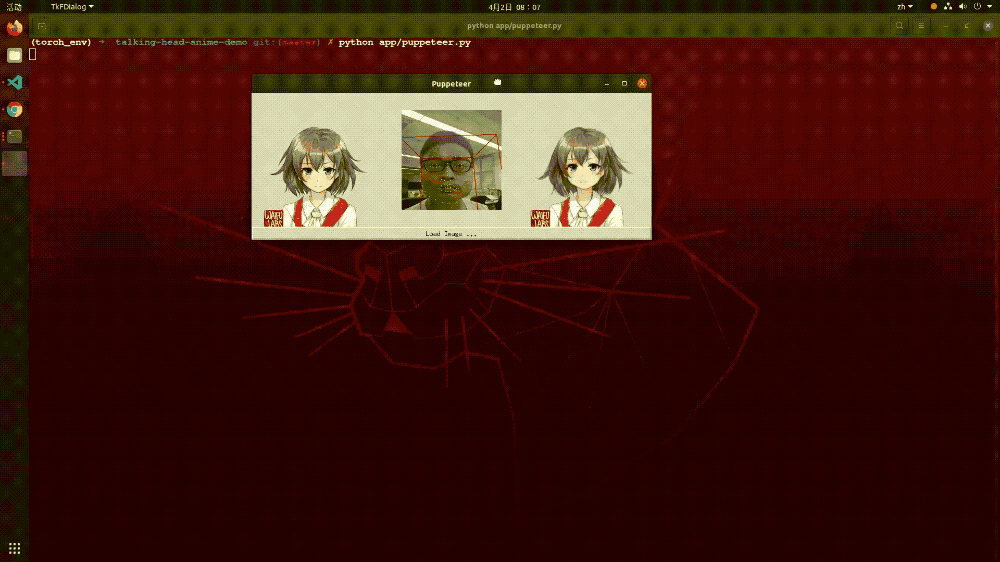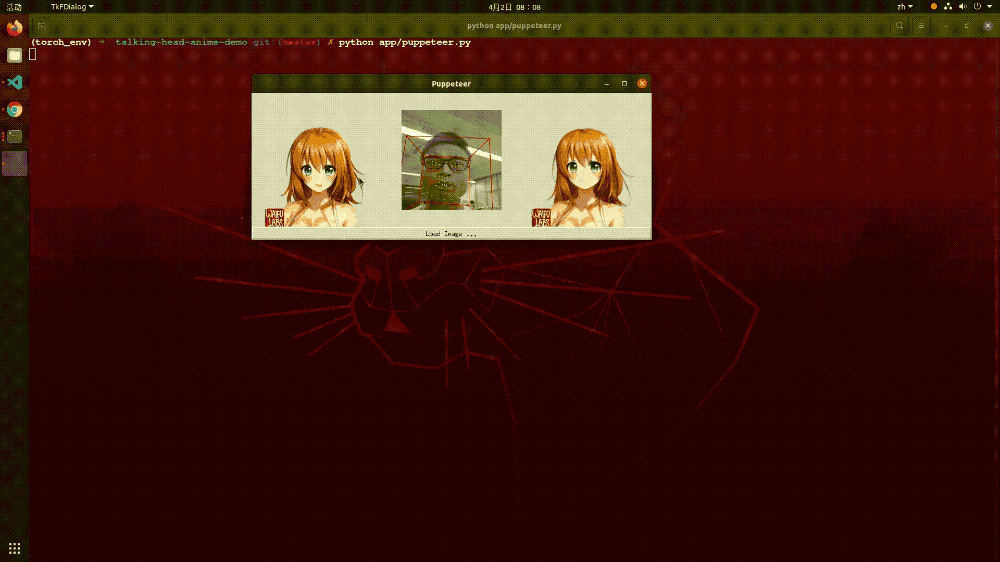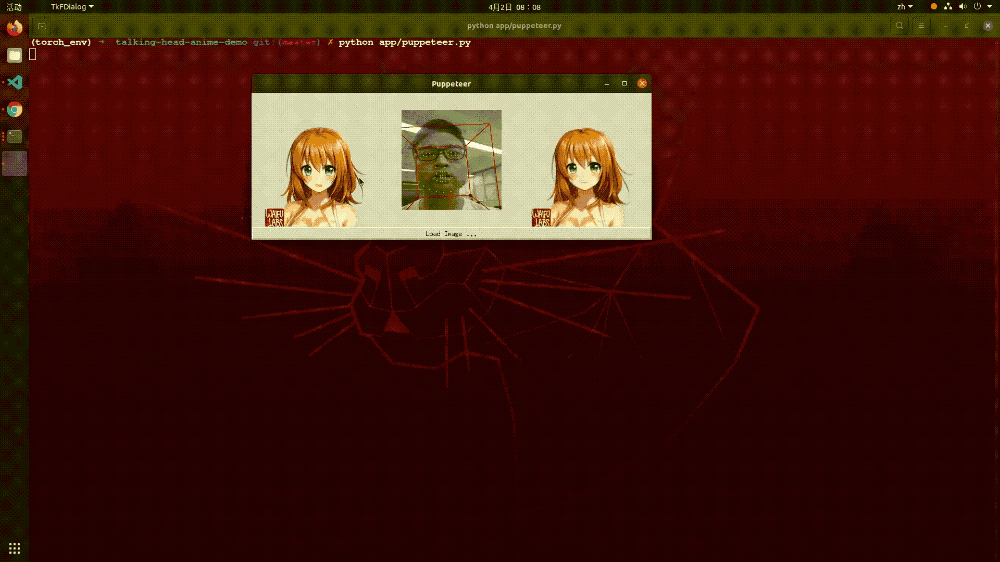 ▲图表23:动作迁移模型
▲图表23:动作迁移模型
– 多目标检测与跟踪模型
项目地址:https://github.com/Qidian213/deep_sort_yolov3
deep_sort算法一个多物体目标跟踪算法,不过在deep_sort_yolov3算法里,是将检测的模块换成了检测效率更好的YOLOv3。因此deep_sort_yolov3可以实现更高效的多目标检测与跟踪。下面就是该算法的效果展示,来看看效果吧。
 ▲图表24:多目标检测与跟踪模型
▲图表24:多目标检测与跟踪模型
5、结语
现阶段算力就是成本。从个人角度出发,云算力虽然能够提供足够的算力,但不方便操作。而普通主机或者笔记本电脑虽然使用方便,但难在没有足够的算力支持。所以很多开发者会自己搭建服务器进行模型的训练,其中一个比较友好的方式就是利用集成好工作站进行搭建,在灵活使用的前提下,可以提供足够的算力进行模型的训练与开发。
从上面的实验结果来看,无论是图像分类模型,还是目标检测和图像分割模型,惠普不仅完全可以满足性能的需求,还将工作站的体积做得非常Mini,尤其是搭载的两块NVIDIA Quadro RTX 8000,更是为AI模型的训练和推理提供了强力的算力支持。
当然,整个AI领域不只有视觉模型开发需要算力支持,数据科学计算、语音模型开发和自然语言处理模型的开发也都需要算力支持。而且随着算法模型复杂度的不断增长,对算力的要求也不断提高。那么如果有一个可以满足高性能算力需求的工作站可以选择,或许对于个人开发者来说是一个最优的选择。
参考链接:
[2] https://developer.nvidia.com/zh-cn/blog/nvidia-turing-architecture-in-depth/
[3] https://hub.fastgit.org/tensorflow/models/tree/master/research/slim
[4] https://hub.fastgit.org/YunYang1994/tensorflow-yolov3
[5] https://hub.fastgit.org/pytorch/examples
[6] https://hub.fastgit.org/eriklindernoren/PyTorch-YOLOv3
[7] https://github.com/tensorpack/tensorpack/tree/master/examples/FasterRCNN
