








智东西(公众号:zhidxcom)
作者 | 子佩
编辑 | Panken
“有一些事烦扰着你,像是阻止人类历史翻过新的篇章,你知道那一页后面空空荡荡,正如这一夜,地球上最后的夜晚。你决定完成那一件事,给整个文明画上一个完美的句号。”
看到这段话的时候,你会想到什么?
是曲折又飘渺的意境,还是不知所云的指代?
这段文字出自科幻作家陈楸帆的短篇小说《出神状态》,在2019年被专门为书籍打分的“AI评论家”谷臻小简评为年度小说,此前,谷臻小简最喜欢的书是莫言的《等待摩西》。

▲《出神状态》原载于《小说界》2018年第4期,该期主题为“地球上最后的夜晚”
令人惊叹的是《出神状态》文章本身也是一部由AI参与创作的作品。
隔着评选与被评选的界限,“AI评论家”和“AI小说家”遥遥相望,在771篇短篇小说中认出了彼此。
这样的“相认”是否代表着AI已经发展出自己的“文学审美”,窥得一丝人类创作的“天机”?
要回答这个问题,我们要从写作型AI的发展历史及其核心技术说起。
一、回顾三十年写作之路:模仿容易创作不易
简单的AI写作从三十年前就开始了,最早的一个AI写作系统诞生于1990年的加拿大,通过从数据库中产生文字摘要的“资料转文本”系统,生成英法双语的气象报告,其后也应用在经济、商业报告和医疗报告上。
三十年过去了,科技世界早已“换了人间”,AI写作也从机械化的“提取”和“填空”,升级到智能化的创作,并开始涉及更加复杂的文本创作。
2016年,日本两支科研团队就曾将AI引入小说创作中,并将其作品参加日本“星新一奖”比赛,骗过了评委的眼睛。
 ▲日本公立函馆未来大学松原仁教授在报告会上演讲
▲日本公立函馆未来大学松原仁教授在报告会上演讲
其中一支团队的负责人松原仁教授表示,自己的团队花费了四年时间来分析日本知名科幻小说家星新一的上千本小说,让AI学习文章中使用的单词种类、句子长短、断句等写作特征。当需要写小说时,AI会基于人类设定好的出场人物、内容大纲等自动补充其余的文章内容。
但他也提到,AI只在小说创作中做出了20%的贡献,并没有学会怎么写小说。
开篇中提到的《出神状态》同样是基于相似的思路。
研究人员直接调用Github上现成的代码,通过调整参数来让模型生成的文字尽可能接近人类写出的文章。且基于对原作者上百万字文章的学习,AI程序“陈楸帆2.0”可以通过输入的关键词和主语,自动生成几十到一百字之间的段落。
尽管模型学会了原作者的写作偏好,如更爱用什么句式、更偏好于怎样的词语描写,但这也仅仅是学会了语句统计的规律,而写作过程更像是从常用语料库中随机找到一些词,按照写作偏好拼接在一起形成段落,没有明确的写作意图或者情感,也难以称得上“文学”之名。
2018年末,世界上第一篇完全由AI创作,无人类参与的小说诞生了。
模仿美国文豪Jack Keroua《在路上》的创作过程,美国小说家Ross Goodwin带着一个麦克风、一个GPS、一个摄像头和一台笔记本电脑上了路,并推出了AI小说《The Road》。
 ▲Jack Kerouac在1948-1950年横穿美国,并创作了《在路上》
▲Jack Kerouac在1948-1950年横穿美国,并创作了《在路上》
在旅途开始之前,Goodwin向模型输入了6000万字的文学作品训练长短期记忆网络(LSTM),其中三分之一是诗歌,三分之一是科幻小说,余下的三分之一是颓废主义文学作品。
在旅程中,摄像机画面以及GPS位移等变化会作为种子单词(seed word)贯连起小说情节。Goodwin希望通过这种方式规避AI小说叙事混乱的问题,增加故事的连贯性。
可惜的是,虽然神经网络可以基于种子单词关联到相关的词语,组成句子,但他们并不知道自己在写什么,也不明白这些话实际代表了什么含义,最终又都会驶向“超现实”写作的范畴,成为一堆单词的拼凑组合。
如何让AI知其然,知其所以然?这就是自然语言处理(NLP,Natural Language Processing)的工作了。
二、AI写作的“引擎”:详解NLG全流程
作为AI皇冠上的明珠,NLP涵盖的范围也很广,包括文本分类、机器翻译、机器理解等,其中最与创作息息相关的就是自然语言生成(NLG,Natural Language Generation)。
自然语言生成的概念也非常易懂,其实就是机器理解的逆过程。
机器理解通过将人类语言转化为机器语言(二进制或其他编码方式),让机器明白人类的意图,而自然语言生成则是通过将机器语言转化为人类语言,让人类明白机器的意图。
大部分NLG模型都遵循一个“从整体到细节”的过程,具体可以被拆分为以下六个步骤:
1、内容确定(Content determination):确定文本包含哪些信息,比如今天我们需要写一篇AI写作有关的文章,所以需要收集相关的资料。
2、文本结构(Text structuring):确定文本的逻辑结构,例如先说AI写作的成就,再展开描述通过哪些技术实现AI写作。
3、句子聚合(Sentence aggregation):合并意义相似的句子,让阅读过程更轻松。如将“AI写作在1990年就出现了”和“最早,AI写作应用于气象、商业、医疗报告等领域”合并为“1990年,最早的AI写作应用于气象、商业、医疗报告等领域。”,让阅读过程更轻松易懂。
4、词汇化(Lexicalisation):找到表述准确的词语。
5、引用表达式生成(Referring expression generation):一些词语能指代更大的范围或引申义,例如当提到NLG,默认其是NLP下的一个分支,下文可以基于这一信息展开其他内容。
6、语言实现(Linguistic realisation):将所有单词和短语组合成表意清晰的句子。
如下图就展示了NLG模型如何从一张新生儿心率图像生成文本。
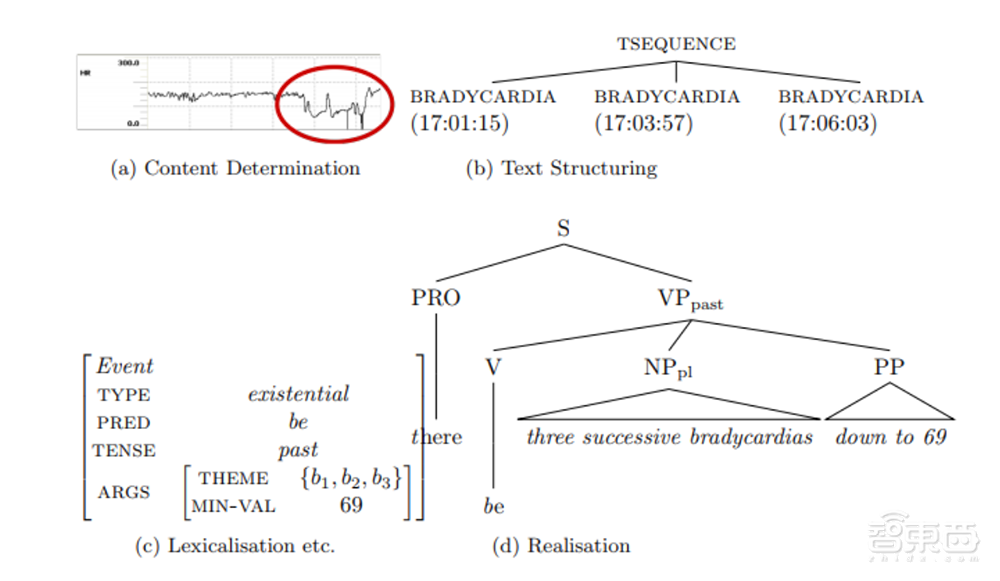
首先在内容确定阶段确定了文本需要描述新生儿的心率变化,在文本结构部分,找出了新生儿三次心率过缓的时间,按时间顺序排列。第三阶段包括了句子聚合、词汇化和引用表达生成,通过词向量的排列组合找到适合的词语,最后在实现阶段组成通顺的句子。
最早的NLG模型可以追溯到1993年的机器翻译模型,Peter F. Brown和Della Pietra将统计方法应用于模型中,实现英法语互译。
其后更多的新方法、新突破也投入了NLG模型中:启发式模型、双语并行语料库、对抗性训练等,让NLG模型在近三十年的历史中,乘风破浪,不断“进击”。
三、AI写作“进阶”:多创新突破理解障碍
NLG是怎么运行的,我们已经很清楚了,但至于为什么目前AI还是无法成为“小说家”,说到底,还是理解不够透。
我们以早期NLG算法模型马尔可夫链举例。
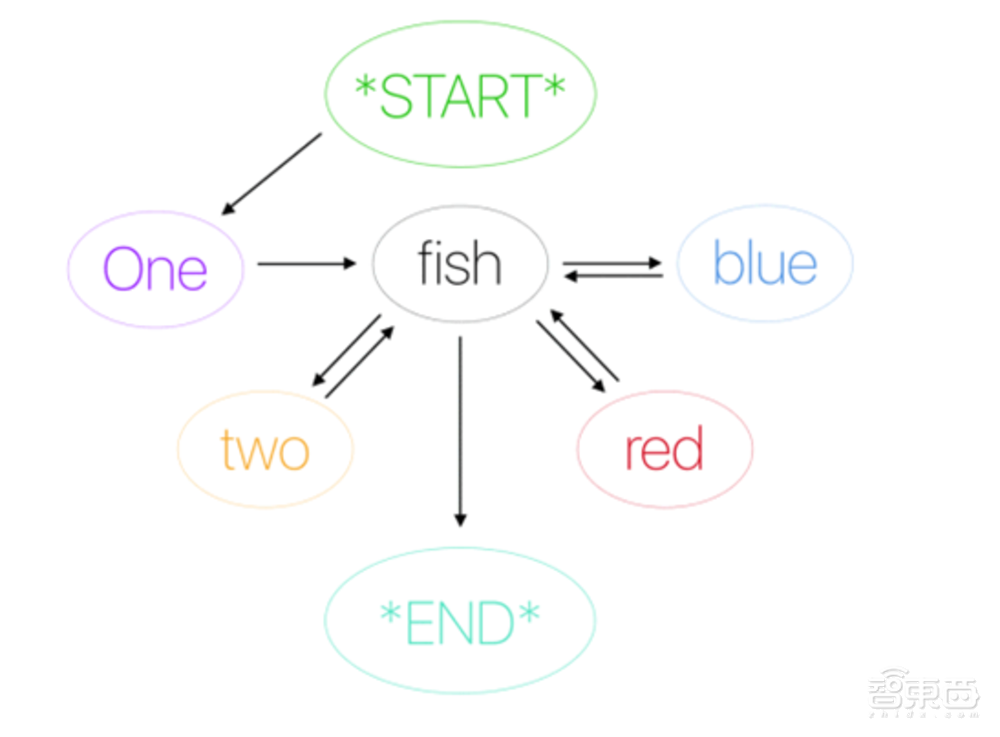 ▲马尔可夫链示意图
▲马尔可夫链示意图
它会使用当前单词来预测句子中的下一个单词。
比如,当模型仅使用以下句子进行训练:“AI能写出诗歌”和“AI写出小说”,那在文本生成阶段,“AI”后面一定会接着“写”,而“写”则有一半的可能接上“诗歌”或者“小说”。
马尔可夫链基于训练集中词频的统计来判断词语之间相连的可能性,这也反映了大部分算法模型暗含的问题,由于训练集的不同,预测结果很可能不同。模型大多数时候并不是“主动”地创作文本,而只是“被动”地根据统计结果猜测下一个可能出现的词是什么。
这样一来,NLG模型确实可以创作出看起来非常像小说的小说,但是仔细一读,却发现它“虚有其表”。
研究人员也采用了许多方法去突破这一瓶颈,其中RNN(递归神经网络)、LSTM神经网络和Transformer(自注意力机制)是较为常用的方法。
RNN通过构建输入输出的非线性关系,实现更灵活的双向预测;LSTM则通过四层神经网络(RNN仅有一层)允许网络选择性地仅跟踪相关信息,且观测到离预测距离更远的上下文。
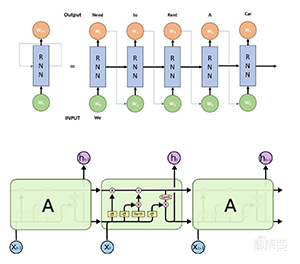
▲分别为RNN和LSTM神经网络的架构图
而Transformer则是目前许多大型语言模型的基石。
简单来说,Transformer可以通过编码器处理任意长度的输入文本,在执行较少步骤的同时,忽略词语位置,直接模拟句子中所有词语之间的关系。
2020年,美国查普曼大学的学生利用基于Transformer的GPT-3模型, 创作了影片剧本《律师》,走红社交网络。
影片开始是一个女人坐在沙发上看书,一阵敲门声响起。
她起身开门,发现一个汗流浃背、狂躁不安的年轻人站在她家门口,他说:“我是耶和华见证人(Jehovah’s Witnesses)。”
但这个女人看起来不为所动,说:“对不起,我不和律师讲话。”
该男子焦躁了起来,试图用一个故事引起她的注意。
 ▲影片《律师》截图
▲影片《律师》截图
影片制作Eli Weiss表示:“我们认为AI写作非常有趣,它将剧情带向了意想不到的方向,而且从故事写作的角度来看,AI写的每一个转折都正中观众心坎。”
结语:创作天机,不可泄露
尽管AI写作的应用日趋广泛,但无论是剧本还是小说,呈现在观众面前的作品都是经过人工修改和调整。
人们所惊叹的创造力,也不来源AI本身的思考,而是根据自身训练数据预测出“下一个最有可能出现的词”。
所以如果我们看一看AI生成的原文就会发现,它们句法完整、辞藻华丽,却往往不知所云,缺乏文学创作中最重要的思想性和情感共鸣。
至于AI是否已经窥得创作“天机”,或许目前它最好的用法,还是作为人类创作者的参考工具。
