









芯东西(公众号:aichip001)
作者 | 心缘
编辑 | 漠影
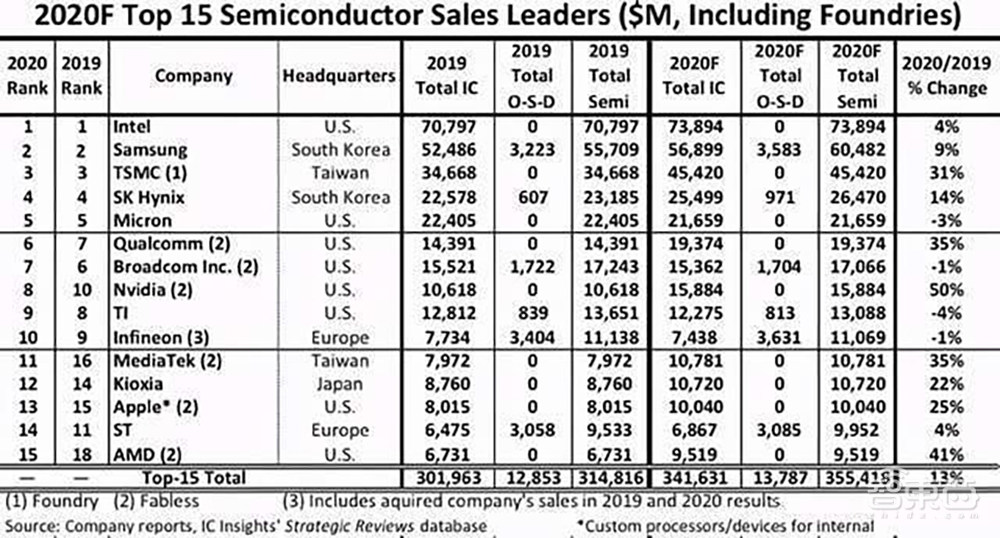
芯东西12月17日报道,根据知名行业调研机构IC Insights预测,2020年全球半导体销售额前十五大公司中,NVIDIA(英伟达)增幅最大,有望较去年增长50%,且排名比去年连升两位。
NVIDIA能取得如此显著的成绩,显然与今年的努力密不可分。在本周的NVIDIA GTC China线上大会期间,来自NVIDIA的五位中国技术专家与芯东西等媒体分享了NVIDIA在架构创新、数据中心平台、网络、图形渲染、嵌入式系统及自主机器等方面的进展及见解。
一、A100 GPU架构创新的三大特性
今年5月,NVIDIA在AI领域投下一颗惊雷——A100 GPU及系列计算产品横空问世,尤其是结构化稀疏模式下性能较上一代猛增。
对此,NVIDIA区中国工程和解决方案高级总监赖俊杰提到,之所以NVIDIA使GPU发展速度和性能提升呈现几倍、甚至几十倍的结果,更多依靠于架构方面的创新。
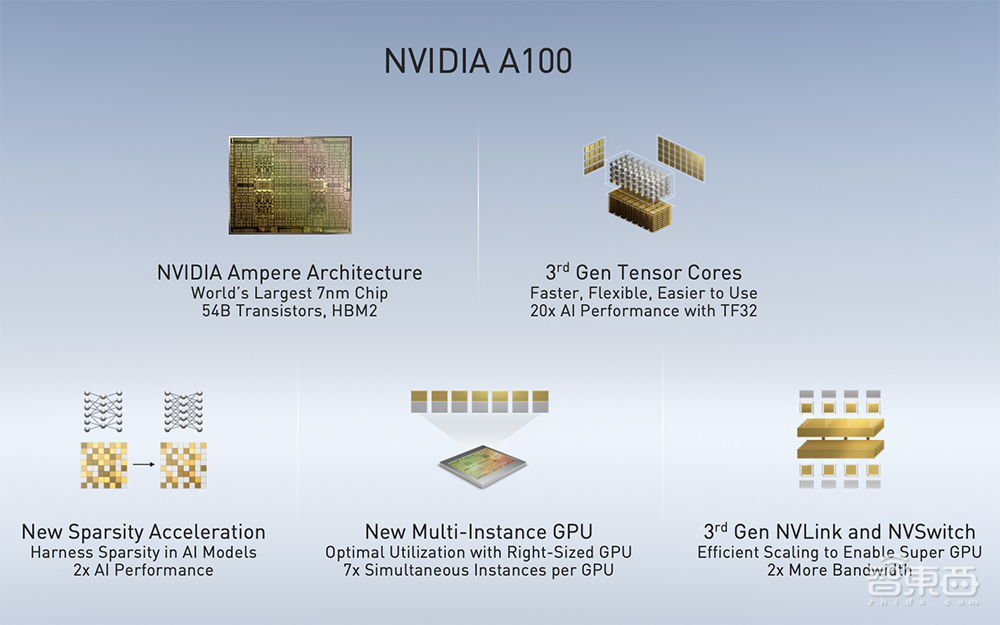
他重点强调了A100架构创新的三点特性:
第一点是第三代Tensor Core引入了TF32精度,TF32精度介于FP 16和FP 32中间,在计算精度和速度之间取得了很好的折中,一方面有足够的动态范围和精度来保证神经网络训练时没有任何精度损失,另一方面能利用Tensor Core架构大大加速神经网络相关的一些计算性能。
第二点是结构化稀疏,换种说法是对网络进行一些规律性的裁减。如果要借助神经网络稀疏性的特征,要想在实际硬件上取得可观的收益是非常难的。基于Ampere架构,NVIDIA A100首次对稀疏性在架构上能够获得显著的提升。NVIDIA主要采用的一个逻辑,是对稀疏性做了一定的限制,每四个权重有两个为“0”,通过这样的方式支持稀疏化计算的全新Tensor Core能够获得额外两倍的性能提升。根据实测,神经网络计算效果也能够得到1.5倍端到端的性能提升。
第三点是多实例GPU,允许对像A100这样比较大的GPU进行灵活的切分,这些切分成的GPU实例在硬件资源上实际上是隔离的,这就能够保证在这些不同的实例上互不影响地运行不同的应用。
赖俊杰还介绍了提供GPU之间高速互连的第三代NVLink和NVSwitch,NVLink是GPU之间“点对点”高速互连,NVSwitch在中间提供一个交换的结构。利用A100 GPU NVSwitch以及Mellanox高速网卡,NVIDIA设计了DGX A100服务器。DGX A100服务器中有8块A100 GPU,通过6个NVSwitch芯片完成高速互连。
结合DGX服务器、Mellanox交换机和网络,NVIDIA还可以搭建更大的数据中心规模解决方案或者参考架构。这是整个数据中心非常重要的一环,使得客户可以在非常短的时间就完成整个数据中心的搭建和部署。
另外,NVIDIA就整个软件生态环境在DGX、DGX POD以及DGX SuperPOD上的运行做了很多工作,能够确保这些软件的顺利运行。
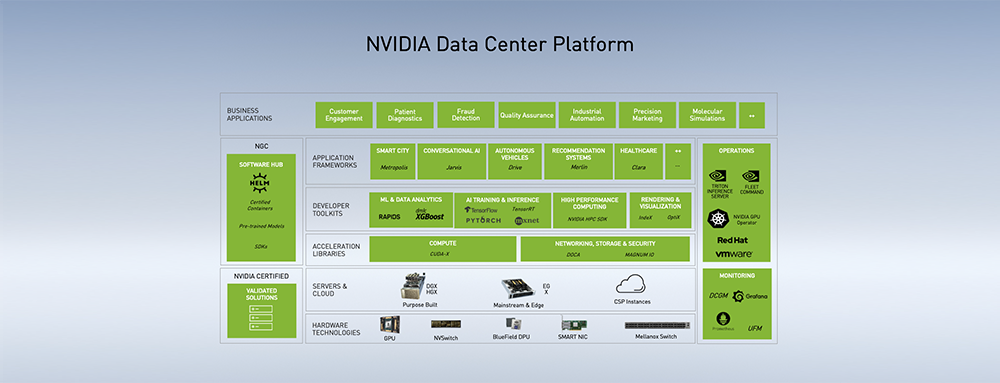
二、NVIDIA数据中心平台全景图
NVIDIA GPU计算专家团队亚太区总监李曦鹏着重介绍了NVIDIA在数据中心建站方面的布局。
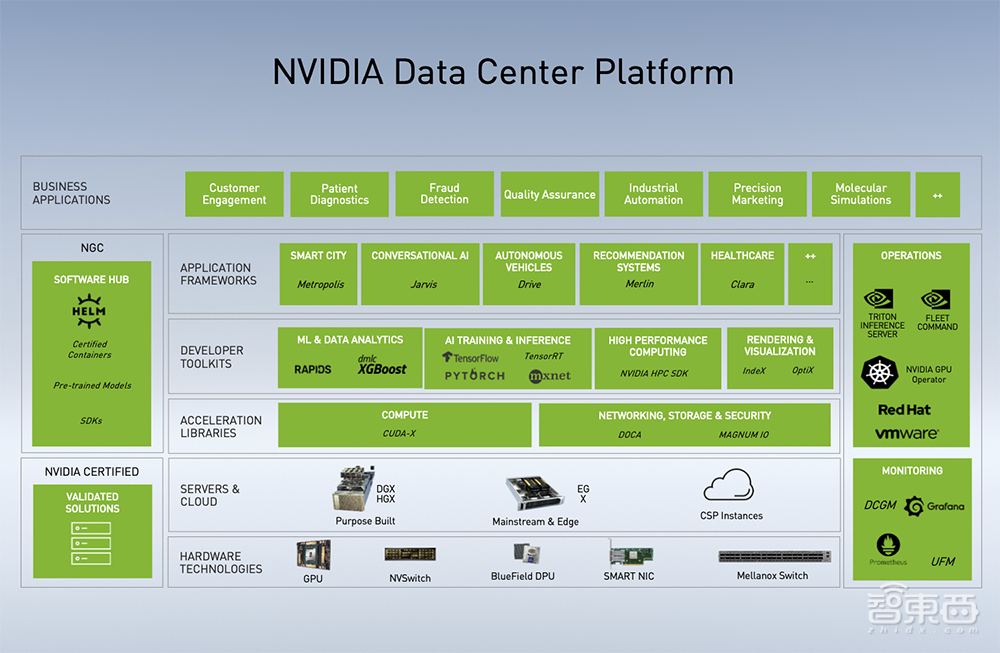
如图是NVIDIA数据中心平台图,从下到上依次是硬件、服务器和云、加速库、开发软件套件、应用框架、商业应用。
李曦鹏说,中小企业、创业公司或传统企业,通过NVIDIA提供的硬件、软件及应用框架,配合1-2个工程师,就能得到不错的对话机器人、语音识别等系统,真正做到普惠。
NVIDIA在应用层面持续完善训练及推理产品所需要的各种功能。在NVIDIA内部,也有完整的应用来推动训练和推理产品的迭代,做到下层技术为上层应用服务、面向应用开发产品,而非闭门造车。
比如,多模态对话式AI服务框架Jarvis不但提供语音识别、语音合成、自然语言处理等模型,也包括计算机视觉中的姿态识别、说话人识别等模型,并使用Triton推理服务器将模型和请求对应起来,在数据中心中进行部署。
NVIDIA Merlin是今年GTC春季时发布的框架,包括应用于ETL和数据读取的NVTabular、专门用于训练推荐系统模型的HugeCTR,其中HugeCTR是一个针对推荐系统和GPU高度优化的训练框架。通过NVTabular和HugeCTR,数据读取的速度可提高80倍、模型训练的速度可提高20倍,最后训练好的模型可基于Triton进行部署。
Triton是部署方面非常重要的软件,同时支持各类模型运行在GPU、CPU上,当不同模型组成服务时,还要考虑到不同服务对延时、吞吐的要求,以便支持更上层的AI应用开发人员。此外,Triton还有自动化动态Batching,对不同的请求进行打包以达到更高的吞吐,每一个模型拥有独立的调度队列以及灵活的模型加载。同时,Triton也提供了诸多利用率、吞吐、延时方面的指标,这些指标可以给到Kubernetes资源调度的工具使用。
三、定义未来数据中心的网络产品
NVIDIA亚太区网络市场开发高级总监宋庆春重点分享了NVIDIA的NDR InfiniBand产品和DPU产品。
其中NDR InfiniBand产品充分体现了未来的网络架构——软件定义、硬件加速、云原生、网络计算的网络。NVIDA NDR产品是业界首款400Gb/s的端到端网络解决方案,实现了网络通信中最难的AllReduce和All2All集合通信硬件卸载,能将集群非常轻松的扩展到上百万个节点。
数据中心级芯片NVIDIA DPU是集整个数据中心功能于单芯片的处理器,被定义为与CPU、GPU一起组成未来构建高性能、可扩展、安全数据中心的三大要素。DPU可以将计算、存储、安全、网络等功能于一身,同时也实现了业务域和安全域的分离。
硬件背后还需要软件的支持。NVIDIA为DPU所定义的DOCA SDK,能将DPU硬件加速引擎充分调用,从而将DPU的性能发挥极致。
另外宋庆春观察到,在使用NVIDIA DPU时,无论是ASAP2还是SNAP,都提供了更多的灵活性和更高的性能。
四、迄今实时渲染图形领域最好的技术方案
在NVIDIA声望颇高的图形渲染方面,从前一代Turing架构到最新的Ampere架构,都显著增强了硬件实时光线追踪的渲染能力和AI加速能力。
据NVIDIA中国区工程和解决方案高级总监李浩南介绍,动态全局光照(RTXGI)和深度学习超采样技术(DLSS)被业界认为是迄今在实时渲染图形方面最好的技术方案。
RTXGI的优点是能大幅降低光线追踪的性能开销,并且没有噪点,也能很好的解决“漏光”的问题,其全局光照技术可以很好地兼顾性能和画质。NDLSS的原理是在超算上通过训练数以万计的高品质渲染图片得到网络模型,然后将这个模型用在三维应用和游戏渲染中,在较低的分辨率上进行画面的重构,从而GPU渲染的桢率得到大幅度的提升,其最新2.1版本的画面重构能力从此前的4倍可以提升到9倍。
此外,针对企业级AR/VR应用及VR云游戏等需求,NVIDIA提供了NVIDIA CloudXR软件套件,基于RTX GPU技术可帮助客户在云端构建AR/VR应用。借助NVIDIA CloudXR,用户无需在前端使用高性能PC,就可以驱动沉浸式渲染场景。
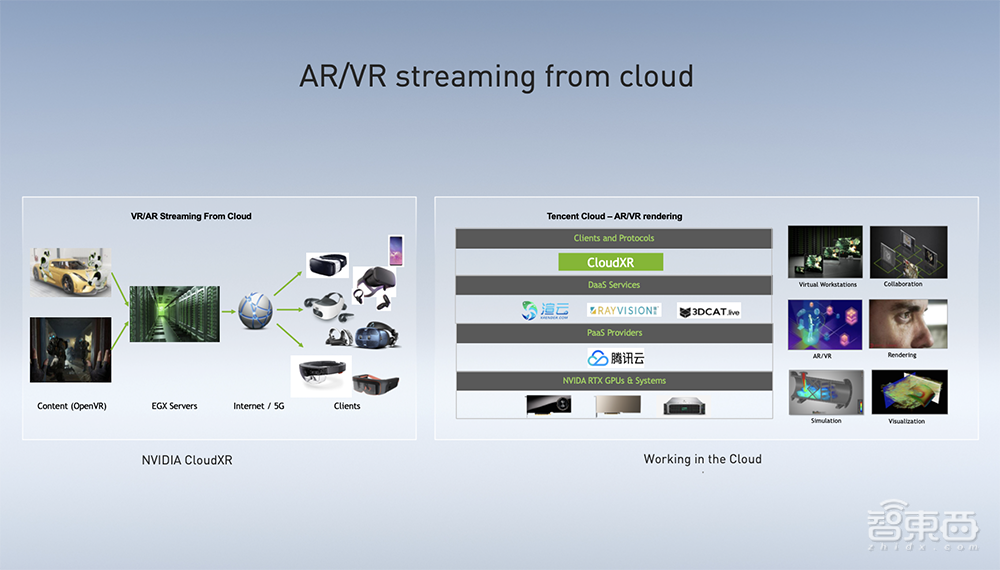
目前NVIDA已在腾讯云上提供基于NVIDIA CloudXR的SDK,可为腾讯云客户供虚拟现实、增强现实及混合现实的一些高级别图形应用。
李浩南说,未来Cloud XR的愿景是通过任何网络链接将XR内容和显示设备连起来,而公有云将是相当重要的一部分。
五、自主机器平台Jetson已吸引70万开发者
NVIDIA亚太区开发者发展总监李铭透露说,截至现在,NVIDIA自主机器平台Jetson已经吸引了全球70万开发者,这一数字每天还在增长中。中国和北美都是Jetson产品占比较大的两个市场。
之所以能吸引如此多开发者和初学者,得益于NVIDIA一直致力于打造一套相对上手容易且功能丰富的SDK,也就是JetPack。开发者及合作伙伴可以通过这些产品,将想在边缘计算上实现的各种应用、算法加以实施,且通过验证阶段后,可根据优化结果或客户需求再进一步做调整。
Jetson的算力选择非常丰富,覆盖从0.5TOPS至30TOPS,能满足不同阶段的产品化落地需求。另外,NVIDIA还在自主机器上做相应的云原生支持,使得原先孤立的边缘端与云端打通。

李铭还提到活跃度非常高的Jetson开发者社区,他说目前在社区中,NVIDIA全球工程师会7×24小时提供支持,帮助开发者快速实现想法。
在李铭看来,AI真正的引爆点在于图像或视频中的一些关键元素分析。NVIDIA在嵌入式市场、边缘市场上的投入到现在为止已有五六年时间,踩过很多“嵌入式”上的坑并将过往经验都沉淀下来,能提供专业的支持和保证。
结语:AI加速和GPU领域的技术风向标
在AI加速、GPU领域,NVIDIA是业界的代表玩家,它在GTC大会上所展示的前沿技术也代表了现在或将来的许多技术趋势。在接下来两天的GTC China大会上,NVIDIA还将分享更多关于技术成果及行业创新应用的干货内容。
除了前文提及的技术及应用方向外,这些技术专家也提到NVIDIA已实现与中国市场的主要Arm服务器生态体系进行更多的适配,以及一些重要OEM厂商的合作,下一步NVIDIA将进一步把GPU加速的Arm服务器方案在各场景中夯实,并覆盖到更多场景。
另外,NVIDIA研究部门正在探索更多的芯片设计空间,例如MAGNet实验项目即通过对芯片上数据流及计算单元的功耗仿真模拟,来优化计算单元、存储单元的设计以及缓存策略,从而提高芯片在AI相关计算中的计算效率。
