








智东西(公众号:zhidxcom)
文 | 董温淑
智东西7月28日消息,今天,英国AI芯片创企Graphcore的高级副总裁兼中国区总经理卢涛、Graphcore中国区技术应用总负责人罗旭与智东西等媒体分享Graphcore产品的性能及Graphcore在中国的市场策略。
Graphcore成立于2016年,经过4年潜心研究,专为AI任务打造的第一代IPU(智能处理器)于2019年落地。本月中旬,Graphcore发布其第二代IPU产品。卢涛称,在运行图像分类训练任务时,8个基于IPU的刀片机性能相当于16个NVIDIA DGX A100 GPU,且价格更为低廉。
卢涛称,中国市场作为AI芯片发展的一个重要市场,也是Graphcore布局的重点。Graphcore将通过寻求云合作伙伴、OEM合作伙伴、渠道合作伙伴布局中国市场。
据悉,今年7月份以来,Graphcore接连推出多款软硬件产品,致力于在计算、数据、通信三方面实现颠覆性技术突破。
回顾Graphcore 7月份在中国市场的动作。7月7日,软件开发工具Graphcore Poplar SDK 1.2发布、Graphcore Poplar计算图库源代码正式开源;7月8日,Graphcore推出基于IPU的开发者云;7月15日,专为AI任务设计的第二代IPU、机器智能刀片式计算单元IPU-M2000面世。
一、IPU MK2:比MK1系统性能提升8倍以上
Graphcore推出的IPU(智能处理器)是一种专为AI训练、推理任务设计的新型处理器,采用大规模并行同构众核架构,卢涛将其描述为“世界上最复杂的处理器”。
Graphcore第一代IPU MK1于2019年推出,据称相比NVIDIA V100 GPU,能将自然语言处理(NLP)处理速度可提升20%~50%,为图像分类带来6倍的吞吐量而且是更低的时延,在一些金融模型方面训练速度能够提高26倍以上。
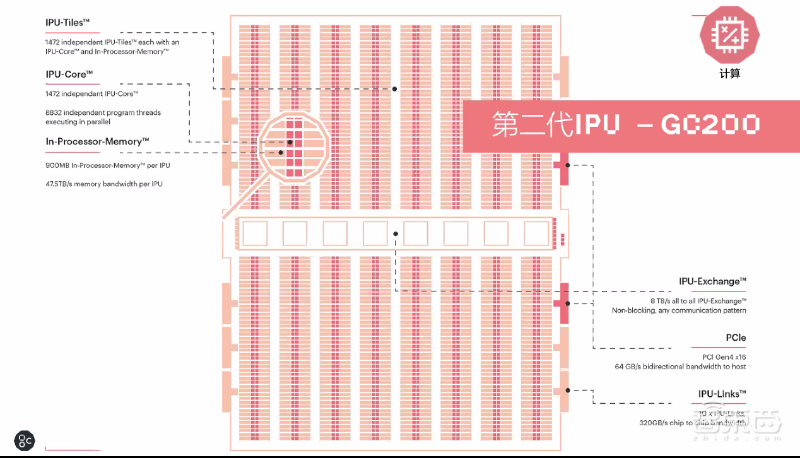
第二代IPU MK2采用台积电7nm制程技术,在823平方毫米的面积上集成594亿个晶体管,算力可达250TFlops,具有900MB处理器内存储,采用1472个独立处理器内核、8832个单独的并行线程。
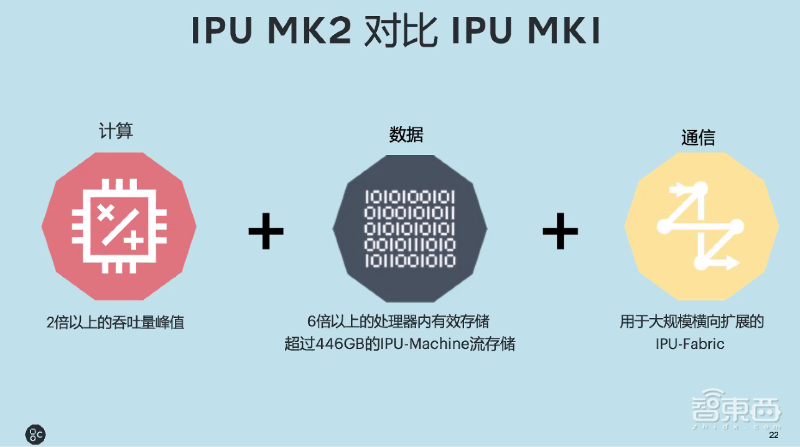
相比第一代IPU MK1,IPU MK2系统性能提升了8倍以上。相比MK1,MK2达到2倍以上的吞吐量峰值、6倍以上的处理器内有效存储,具有超过446GB的IPU-Machine流存储,支持用于大规模横向扩展的IPU-Fabric横向扩展结构。
在数据传输方面,Graphcore IPU采用的Exchange-Memory通信技术相比NVIDIA采用的HBM技术,带宽提升100多倍,容量提升大于10倍。
据悉,NVIDIA HBM技术的带宽为1.6TB/秒,IPU-Exchange-Memory技术带宽为180TB/秒;NVIDIA HBM技术的容量为40GByte,IPU-Exchange-Memory技术容量为450GByte。

为了优化通信效果,Grapgcore采用专为AI设计的横向扩展结构IPU-Fabric。该结构能达到2.8Tbps的超低时延,支持64000个IPU之间的横向扩展,可直接连接和/或通过以太网交换机连接,支持集合和全缩减操作。
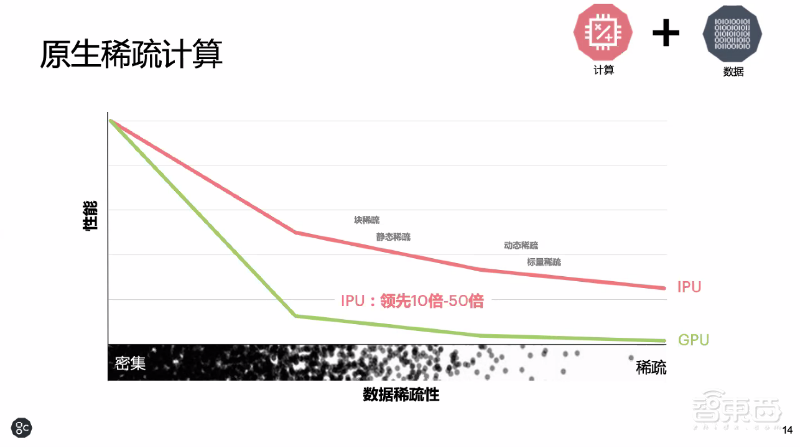
卢涛称,在运行AI任务时,数据稀疏性越高,IPU的优势越明显。随着数据稀疏性升高,IPU性能可领先GPU 10倍~50倍。
二、8个IPU-Machine M2000性能比肩16个NVIDIA A100
Graphcore IPU-Machine M2000是一款即插即用的机器智能刀片式计算单元,由Graphcore全新的7纳米Colossus第二代GC200 IPU提供动力,由Poplar软件栈提供支持。

IPU-Machine M2000可提供1个PetaFlop的机器智能计算、450GB的Exchange-Memory,具备2.8Tbps的IPU-Fabric超低时延通信。
另外,M2000的配置具备“弹性”,从配置1个M2000到配置64个M2000均可。

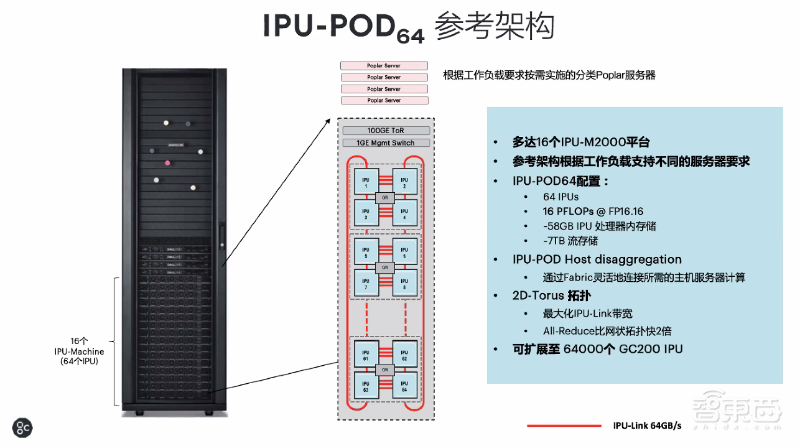
基于IPU-Machine M2000,Graphcore推出用于超大计算规模的模块化机架规模解决方案IPU-POD。IPU-POD基于IPU-POD64参考架构,每个机架最多部署两个IPU-POD64,最多可部署512个机架。
IPU-POD可无缝扩展多达64000个IPU,这些IPU作为一个整体或作为独立的细分分区,可以处理多个工作负载以及满足不同用户需求。

IPU-POD64参考架构可进行大规模、分散的横向扩展,从而将高性能的机器智能计算扩展到超级计算规模。
根据Graphcore官方数据,M2000性能优于NVIDIA A100 GPU。
用8个NVIDIA A100 GPU与8个Graphcore M2000进行比较,结果显示M2000解决方案的FP32算力超过A100解决方案12倍、AI计算算力超过A100解决方案3倍、AI存储能力大于A100解决方案10倍。

在运行EfficientNet-B4图像分类训练任务时,8个IPU-M2000可达到与16个NVIDIA DGX A100相同的运行效果。
价格方面,8个IPU-M2000建议售价为259600美元,16个NVIDIA DGX A100售价超过三百万美元。

三、IPU开发者云:支持5种先进AI模型训练、推理任务
7月8日,Graphcore推出中国首款基于IPU的开发者云。Graphcore IPU开发者云部署在金山云上,使用了IPU-POD64、浪潮IPU服务器NF5568M5和戴尔IPU服务器DSS8440。
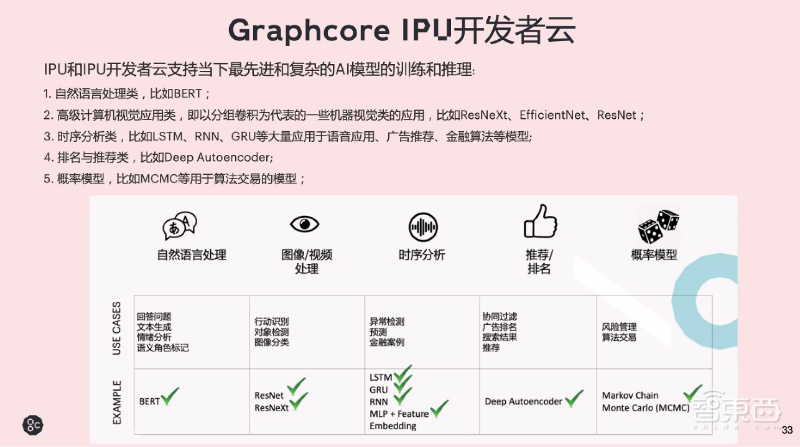
IPU开发者云支持一些当前最先进和复杂的AI模型的训练和推理。具体包括:
1、自然语言处理类,比如BERT;2、高级计算机视觉应用类,即以分组卷积为代表的一些机器视觉类的应用,比如ResNeXt、EfficientNet、ResNet;3、时序分析类,比如LSTM、RNN、GRU等大量应用于语音应用、广告推荐、金融算法的模型;4、排名与推荐类,比如Deep Autoencoder;5、概率模型,比如MCMC等用于算法交易的模型。
目前,Graphcore IPU开发者云面向商业用户评测、高校研究项目、部分个人开发者提供免费试用。
四、Poplar SDK:已开源计算图库源代码
底层硬件形态之上,Graphcore还推出了软件开发包Poplar SDK 1.2。
Poplar SDK 1.2与领先的机器学习框架集成,具有强大灵活的低级别API,增强了用于IPU上的PyTorch和Keras框架支持,具备新的库支持和功能,可用于改善机器学习模型的性能,支持用TensorFlow和PopART中的多机数据进行并行训练,公开Exchange-Memory的管理功能。
目前,Graphcore Poplar计算图库源代码已经开源,并可在GitHub上使用。罗旭称,Poplar工具将助力各位开发者“创建下一代机器智能”。

结语:Graphcore发力全球市场,将开设东京办公室
经过前期的潜心研发,Graphcore的IPU产品已迭代至第二代。与GPU不同,Graphcore研发的IPU是专为AI任务设计的处理器,在运行特定AI任务时性能优于传统的GPU。
卢涛指出,目前Graphcore还未实现盈利,但对于一个新产品来说,前期的大量投入是不可避免的。他认为随着AI训练、推理的发展,IPU将拥有更大的市场。
在产品更新迭代的同时,Graphcore开始在全球市场布局。目前,Graphcore在全球拥有13个分支机构,下一步计划在日本东京开设办公室。
