








出品 | 智东西公开课
讲师 | 魏勋 品览数据技术合伙人
提醒 | 关注智东西公开课公众号,并回复关键词“AI零售03“,即可获取课件。
导读:
6月8日晚,品览数据技术合伙人魏勋在智东西公开课进行了AI零售合辑第三讲的直播讲解,主题为《商品识别算法在货架商品智能巡检中的应用》。
在本次讲解中,魏勋老师首先分析新零售下货架巡检存在现状,给出了以图像识别和目标检测实现货架巡检的方案,之后分别从图像分类与目标检测发展历史,货架商品识别的难点、落地关键及实际应用案例等方面进行深入讲解。
本文为此次专场主讲环节的图文整理:
正文:
大家好,我是魏勋,是上海品览数据的技术合伙人,今天由我为大家带来在快消零售领域的一个具体落地方案,是讲货架商品的智能巡检的应用,今天分享的主题为《商品识别算法在货架商品智能巡检中的应用》,主要分以下5个部分:
1、新零售赛道:货架战争
2、图像分类与目标检测发展历史
3、货架商品识别的难点
4、货架商品识别落地实践
5、货架巡检应用实例
新零售赛道:货架战争
新零售的概念是马云于2016年提出,它是用大数据、人工智能等先进的技术手段,对商品的生产、流通与销售过程进行升级改造,进而重塑业态结构和生态圈,并对线上服务、线下体验以及现代物流进行深度融合的零售新模式。
按照传统,在零售领域可以分为三大元素,分别为人、货、场,人是指消费者,货是指商品,即SKU,场是指各种大卖场、超市、全家便利店或夫妻老婆店等。场可以再细分到最小的有机单元,就是货架。随着新零售时代到来,货架已经逐渐成为零售企业的战场。
货架的情况包括商品有多少,它被放在哪里?放在哪里比较适合?同时也包括陈列哪些品类,有没有竞品,竞品是如何放置?这些对于零售企业都很重要,对于未来销售、营销的策略有很大的参考意义,所以把它称为一场关于货架的战争。
举个简单的例子,比如当货架上的商品缺货了,作为一个消费者,会做什么样的行为?可能会买别的品牌,还可能去别处买,或者干脆不买,或买另一种类型替代。无论如何若货架上缺货时,品牌商可能会失去46%的购买者,而零售商可能会失去30%的购买者。
为了要打赢这场货架战争,我们必须要精确的获取线下商品的实际陈列信息。为了做到这一步,我们必须要对货架图像中的商品进行识别,这就会用到计算机视觉领域中的图像分类和目标检测技术。

如果在CV领域研究比较久的同学肯定清楚,图像分类跟目标检测是计算机视觉中非常基础的研究方向,且非常重要。图像分类是最基础的,例如上图显示的小猫,可以直接对它进行分类,判断到底是猫还是狗。检测就额外增加了一部分,必须进行定位,才知道它到底是在哪里,同时对定位的目标进行分类。
从图像分类和目标检测的发展历史来看,在2012年以前都是通过提取手工特征,比如SIFT、HOG、LBP等,然后才有后续的分类和检测。随着AlexNet在2012年横空出世,后面所有的方法都是用了CNN或者深度学习的方式来自动提取图像特征,进而帮助我们进行图像分类和目标检测。
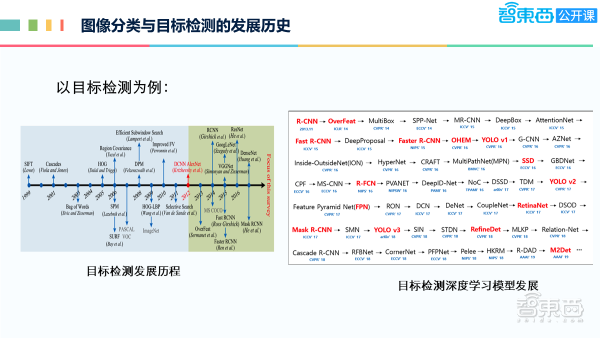
对于目标检测的发展脉络,可以从1999年SIFT的提出开始,还有Cascades、HOG、DPM等,这些都是2012年之前提出用来实现目标检测的手段。随着AlexNet提出之后,AlexNet最早用于图像分类。2013年后,开始有学者在想目标检测是否也可以用CNN来做,所以第一个作品是Overfeat,在与它很接近的时间里,出现了一个非常经典的网络RCNN,然后像Fast R-CNN、Faster R-CNN还有YOLO系列及SSD和RetinaNet等。诸如此类的很多网络可以从上图中看到,从13年到了19年,这段时间里涌现了非常多的网络,标红的都是些比较有影响力的网络。

目标检测的深度学习模型通常是分为两种,第一种是两阶段模型,有Overfeat和RCNN系列,它先要对目标框有一个比较粗的定位,然后再对粗的目标框进行精细的修正,同时进行分类识别。有学者觉得这太麻烦了,能不能一步到位,直接从图像里得到bounding box和它的类别信息。这就是YOLO系列,还有SSD和RetinaNet等。通常,两阶段模型的精度会比较高,但速度会比较慢;单阶段模型的精度通常要低些,但它的速度会很快,如上图右边所示,不仅是说两阶段、单阶段的问题,还考虑了backbone的问题,若backbone越大,速度可能越慢。我们可以看到同一个backbone,在单阶段的模型下,它的速度远远要快于两阶段模型,但是精度mAP会要低一些,这张图是在COCO数据集上计算的结果。
货架商品识别的难点
上面简要介绍了图像分类及目标检测的大致情况,下面直接进入具体场景,就是货架商品识别。识别包含检测和分类两部分。对于货架商品识别的难点分成两块,首先,是算法难点,主要有四点。第一是商品种类繁多,像ImageNet用来刷榜时,一般用到1000个种类,但商品的SKU种类基本上是上万,甚至是几十万,对真实世界里面的SKU数量可能是百万千万级;第二是在货架场景中,通常会摆放的非常密集;第三是某些商品非常相似,特征看上去没有明显的差异,这也是图像分类的难点,只是在货架上体现程度可能会更大;第四点比较特殊,同一款商品可能有不同的规格,比如可口可乐,它可能会有330毫升、500毫升,或一升的,它更像是等比例缩放,因为计算机视觉天然是要求有尺度不变性的,这种情况通常是很难区分的。

上图是具体的图片展示,最左边的图是一个调味料的货架,可以看到种类非常多,一排货架里面应该有几十种,摆放也非常密集,基本上是紧挨着的情况。中间的图是一个比较典型的情况,两个商品属于同一个商家,左边是一个常规的,右边的可能是为了某种活动促销特别特意加了100克,可以看到商品其实非常相像,除了中间多了“100克”之外,其他方面没有任何差异。因为在PPT的图比较大,看得比较清楚,如果是在货架上,是很难分辨出来的。右面的图片是同类商品具有多种规格,可以看到最左上角的酱油是300毫升,中间第二排的是500毫升,倒数第二排是800毫升。它们的外观很像,只是存在不同的规格,如果你只是用常规的分类模型去训练,或者用常规的操作去处理,这三种分错的概率很大。
第二个是数据难点,也包括四个部分。第一个是拍摄的货架可能是一种非常倾斜的状态,倾斜很容易导致透视,很多商品就会被遮挡,检测跟分类会受到很大的干扰;第二个是采集到的货架图片是模糊的,里面可辨识的特征基本上看不清,第三个是货架图片翻拍,有一些从业人员可能会偷懒,对着电脑拍一张图片作为工作业绩,然后上传图片,这就是翻拍的情况,这种翻拍也会影响模型的准确率,客户也会要求我们把这类图片识别出来;第四个是货架图片存在曝光过度或者曝光不足的情况,在这种情况下货架的商品基本上看不清的。

针对上面四点,再给大家展示下,第一张图是货架过度倾斜,在过度倾斜的情况下,靠右边的商品还可以看出,但靠左边的商品基本上被遮挡,即使能检测出来,它的类别也识别不了,因为大部分的特征都被遮挡。第二张图展示货架图片模糊的情况,模糊导致看不清商品的主要区分特征,尤其涉及到一些比较相似的商品,模糊基本上就看不清了。第三张图是翻拍的情况,通过肉眼能看出一些情况,它里面会有一条条纹理信息,一般叫摩尔纹,由屏幕的发射光和自然光不一样导致。最后是货架图片过暗或特别亮的情况,过亮时特征都被遮挡,你只能看到一片闪亮,过暗时可以隐约看到一点,但也不知道具体是什么商品。
货架商品识别落地实践
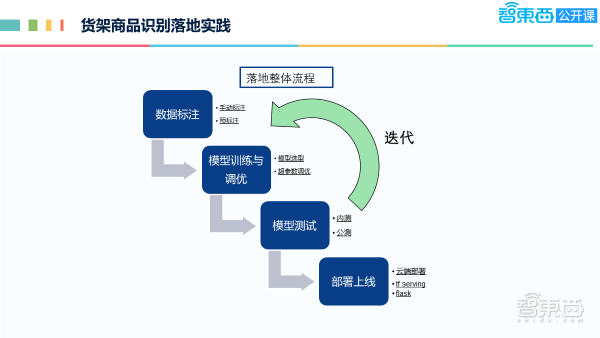
下面介绍下整体落地实践的流程,流程是比较通用的。首先是数据标注,这是深度学习不可避免的。通常先手标一部分,再利用一个比较弱的模型,进行一个预标注,最后是人工调整,这很大程度上节省人力的成本。
第二个是模型的训练调优,通过模型选型和超参的调整去训练模型。训练完后,先做内部测试,内部测完后,还要再做公测,根据公测的反馈,再去迭代上面的步骤,也可能会重新补一批数据,再重新训练模型,达到公测的要求之后,我们会部署上线。目前我们主要是云端部署的方式,模型的云端部署用的是tf serving的方式,外部端是 flask框架。
对于数据难点,其实有一句机器学习的名言:数据是模型的上限,必须要保证数据质量,你才能谈模型的准确率。所以对刚才的几种情况:货架倾斜、模糊、翻拍、过暗和过亮,再把图片送给模型之前,先对图像质量进行分析。实际情况可能还不止这4种。对于货架倾斜,我们会做一个货架检测,根据检测出来的货架层的一个角度来判断倾斜情况。后面三种是通过图像处理的方式来进行判断,一张图片必须通过质量检测,同时满足这4个条件后,才把它送到模型里面去做后续的检测和识别。
在最早期时,对于场景货架商品的识别,我们直接应用检测模型来做检测,但实际上,我们尝试了很多种检测模型,但是效果不太理想,mAP也很低,只有40%左右,与COCO的情况就差不多,SKU类别非常容易分错,根本无法商用。
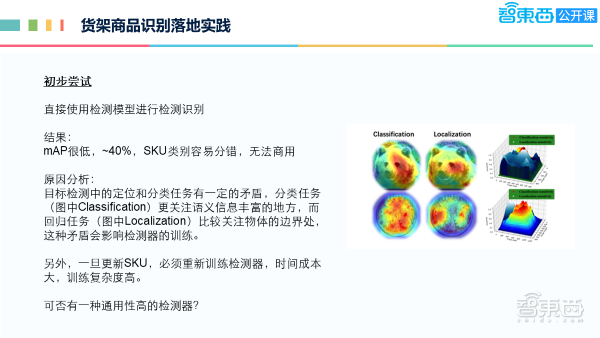
通过分析发现,首先,直接用检测模型去进行检测、识别,在COCO数据集上在SOTA模型上有54%左右的准确率。由于数据量及SKU的种类数量非常大,所以不容易实现。通过大量的阅读论文,发现目标检测里面的定位和分类,其实是有一定矛盾的,通过上图右边看到,若要检测北极熊,它关注的地方是语义信息比较丰富的,主要集中在中间的部分,对于定位通常是更倾向于去关注物体的边界处。对于检测相当于一个多任务学习,同时去做定位跟识别,是有一定的矛盾的,它会影响检测器的训练。
第二点是一旦更新了某些SKU,就必须要重新训练检测器。若大家对目标检测比较熟悉,发现检测器的训练会花费很长时间,时间成本很大,训练复杂度也很高。所以,是否有一种比较通用的检测器,可以避免了上面提到的两种情况。
经过多方讨论,我们决定对SKU不按具体的类别去标注,而是按它的包装对它进行标注,比如像调味品,主要以瓶装、罐装、盒装主为主,然后以这个标注再去训练检测器,定位到具体的SKU位置,之后对定位出来的SKU进行crop操作,对抠出的小图进行后续的识别,相当于是把它分为两个阶段来做。
为什么要这样做?第一点看使用包装,包装相当于SKU的形状,我们在对SKU形状进行定位及分类时,会削弱定位及分类之间的矛盾。第二点是SKU的种类是成千上万甚至十几万,但是它的包装种类数量是有限的,通常不到10种,具有很强的通用性。一旦训练完成后,如果有SKU的更新,我们不需要再重新训练。除非包装发生了很大的变化,才会重新训练检测模型。
到底要使用一个什么样的检测模型呢?在模型选型时,同时还要兼顾检测精度和速度,目前以云端部署为主,虽然不要求实时性,但也希望尽量快的响应,客户通过web请求,上传图片、做检测分类,还有后续一系列的逻辑处理,在这种情况下,希望能够在几秒内有一个实时响应。
在V100上测试过,早期时分别尝试了Faster-RCNN、RetinaNet、YOLO v3。可以看到Faster-RCNN的backbone用的是ResNet50+FPM,它的检出率能达到能到97.1%,但是它的速度很慢,因为是一个二阶段的模型,只有6FPS;RetinaNet经过调优之后,能达到一个96.7的检出率,速度为15FPS;YOLO v3的效果也不是特别理想,检出率只有94.5%,但是它的FPS很高,能超过30。右图是RetinaNet和YOLO v3对同一张图的检测效果,可以看到YOLO v3会把上面的两个箱体漏掉,而且右边会多检测出非商品的东西,这个与YOLO v3的机制有关,它对如此密集的商品摆放支持不太友好,而RetinaNet使用了一个更密集的Anchor设置,效果上会更好。
介绍完检测后,下一步如何对成千上万的SKU进行有效的识别?最开始考虑用图像检索的方式,这也是比较自然、省力的想法,只需要训练一个比较通用的提特征模型,如有一个新的SKU,只需要提供几张样例图片作为检索库,然后对一个小图进行识别,直接去检索库里面检索即可。所以先通过模型先提取特征,提完后跟检索特征库进行匹配,比如可以直接计算余弦距离或者欧式距离,然后去找Top1。经过多次实验,它的识别准确率最高也只能达到90%左右,这是无法达到商用标准,商用标准一般至少得到97%、98%,对有些客户比较严格会要求99%以上。
原因分析下来发现,首先是不同商品之间的特征差异很大,现实场景很复杂,训练提取特征的模型无法达到很强的鲁棒性。而且业界SOTA的图像检索方法准确率也只有90%左右。最终,还是通过图像分类的方式对小图进行识别。
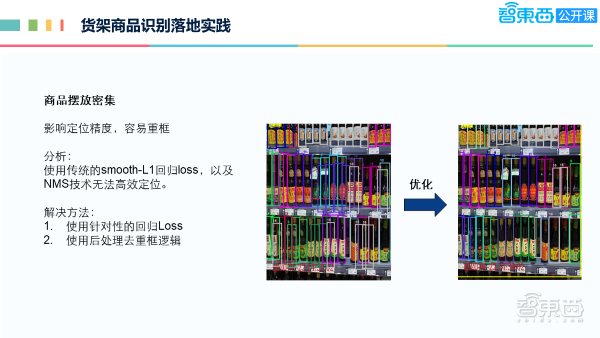
由上图可以看出,货架上的商品摆放是非常密集的,很容易影响定位精度,造成重框的现象,左边这张图是早期的情况,可以看到第二排下有很多的重框,第三排也是类似的情况。经过优化之后,基本上都能够把重框去掉。分析发现用传统的 smooth-l1的回归loss,以及传统NMS技术无法高效的定位去除重复的框。我们的改进方法是使用一种针对性的回归loss,使得这种密集的商品摆放能够有比较好的回归定位。第二是使用后处理的去重框逻辑,经过这两部分操作后,最终能达到像右边的一个效果。
针对商品十分相似的情况,比如1000种的SKU类别,里面可能有几十种是很相似的,相似商品之间的类间距会很小,它混在大量的类间距很大的类别中,比如酱油跟豆瓣酱,它们可能差异会很大,因为一个是瓶装,一个是罐装;比如两种酱油,一种是红烧酱油,另一种是天然酱油,它们就很接近,可能只是颜色上有差异。之前也实验过用细粒度图像分类来做,但发现细粒度分类是有要求的,必须要求图片的分辨率很高,才能去做细粒度分类,货架图片通常是几百万到千万级的像素,再从里面抠出来的小图,宽、高可能就200×200,是无法满足用细粒度分类要求的。
可以通过一个分治的方法,对SKU进行层级划分,非相似的划在一起,相似的划在一起,相似的都统一一个label,统一完label后,再把相似的具体细划分。相当于在同一层级之下,它们的类间距是在一个量级,至少分类器是不容易去忽视这样的情况。
对于同一类商品具有不同的规格,跟刚才略有差异,因为刚刚只有相似,但还有一些特征差异的,这里并没有太大的特征差异,只是等比例缩放的情况,分析下来发现,对于2D计算机视觉,它本身需要满足尺度不变性,仅靠视觉特征基本是无解的,所以必须要借助非视觉特征。我们会采用机器学习的方法来提取一些关键有用的特征,比如高度、宽度等进行区分,当然这种情况必须得满足拍摄距离是比较固定的。通常拍摄距离不会有大幅的改变,而且我们不仅有高度这样的特征来进行机器学习模型的训练,还会有一些别的非视觉特征。可能有同学会问,如果2D视觉解决不了,为什们不用3D视觉?这受限于我们的场景,图像本身其实主要是由客户来提供,他来调用我们的服务,所以我们是无法要求他持一个3D的设备去进行数据采集,这是无法做到的,也限制了我们的一个技术实施。
货架巡检应用实例

上面介绍了把货架商品识别的难点,以及所采取的方案,下面简单介绍下货架巡检的应用实例。比如跟欣和的合作,它主要生产各种调味料,像酱油、豆瓣酱等。我们给他做好商品识别后可以用来做什么?首先,他们内部的一些陈列规则,比如看它的排面是否少于竞品,当看到同一排里面少于竞品的,这说明什么?他们要加强这家店或者这些相关货架的陈列数量;第二个是说不在黄金位置,黄金位置是你能进到一个店里,或者是在货架面前最容易拿到或者最容易看到的货架层的位置,通常5层货架,第二层、第三层是黄金位置,第一层可能很不好拿得到,下面两层弯腰也不方便,所以黄金位置,对于商家来说也是很重要的一个指标;第三是缺货、陈列不合格,看货架是否能陈列饱满;第四个是本品没有集中陈列,就是商品不应该隔开来放,应该放在一起。
同时也跟国内味全果汁也有合作,我们主要是在AI巡店通上做的产品,味全果汁包装的更新速度非常快。所以,我们迭代的速度必须要满足他们更新速度。我们基本能够精确地识别出他们具体有哪些果汁,以及它的一个陈列位置,以及各种陈列信息。
