








智东西(公众号:zhidxcom)
文 | 心缘
智东西6月22日报道,在今天的国际高性能计算大会(ISC 2020)上,NVIDIA推出PCIe版本的A100 GPU,并同多家全球领先的服务器制造商推出多款内置NVIDIA A100且具有不同设计和配置的服务器。

全新NVIDIA Mellanox UFM Cyber-AI平台和UFM系列第三款产品UFM Telemetry平台也于现场发布。
此外,NVIDIA宣布其RAPIDS数据科学软件在DGX A100之上以19.5倍TPCx-BB性能打破纪录。
一、NVIDIA科学计算平台在抗疫中发挥关键作用
NVIDIA首先分享了其科学计算平台在抗击疫情期间,如何为全球不同领域了解COVID-19和探索抗击疫情的测试与治疗方案提供加速。
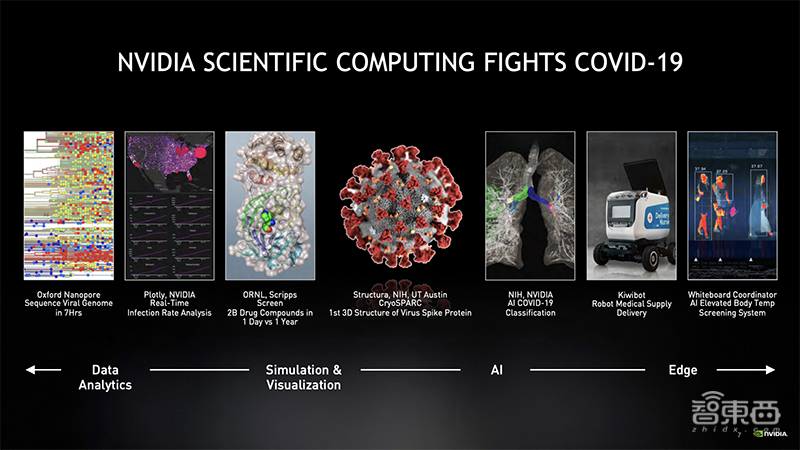
例如,在基因组学领域,Oxford Nanopore Technologies使用NVIDIA GPU在短短7个小时内完成了病毒基因组测序。
在感染分析和预测领域,NVIDIA RAPIDS团队使用GPU加速的数据可视化工具Plotly Dash为实时感染率分析提供更清晰的洞见。
在结构生物学领域,美国国立卫生研究院(U.S. National Institutes of Health)和德克萨斯大学奥斯汀分校(University of Texas, Austin)正在使用GPU加速软件CryoSPARC和低温电子显微镜重建首个病毒蛋白3D结构。
在治疗领域,NVIDIA与美国国立卫生研究院合作构建了一个AI模型,该AI可根据肺部扫描对COVID-19感染进行准备分类,从而制定有效的治疗方案。
在新药研究领域,橡树岭国家实验室在GPU加速的Summit超级计算机上运行了Scripps研究所的AutoDock,只用了短短12小时对十亿种潜在药物组合进行了筛选。
在边缘检测领域,Whiteboard Coordinator Inc.建立了一个可以自动测量和筛查人员体温升高的AI系统,每小时可筛查2000多名医护人员。
而之所以在这么多工作发挥作用,源自NVIDIA为科学计算社区提供端对端的工作流程。
在数据分析领域,NVIDIA通过使用用于数据分析的特定领域CUDA-X库以及来自Magnum IO的IO加速技术,为Spark3.0、RAPIDS和Dask等关键框架提速。
同样,NVIDIA为700多种HPC应用以及所有AI框架提速。凭借在视觉计算领域的深厚知识,NVIDIA还能提供加速可视化解决方案,因此可以实现TB级数据的可视化。
例如美国国家航空航天局(NASA)在全球最大的立体可视化项目中使用我们的加速堆栈实现了首次载人火星任务着陆过程的交互实时可视化。
二、推出PCIe版本的NVIDIA A100及多款内置A100的服务器
NVIDIA A100 Tensor Core GPU是NVIDIA今年推出的首款基于NVIDIA Ampere架构的GPU,也是NVIDIA迄今为止性能提升幅度最大的GPU。
其AI训练及推理性能较上一代提高多达20倍,高性能计算性能提升2.5倍,且采用多实例GPU技术,可将单个A100分割成最多7个独立GPU来处理各种计算任务。
为了补充完善上月发布的四卡和八卡NVIDIA HGX A100配置,NVIDIA今天推出PCIe版本的A100,使服务器制造商能提供从内置单个A100 GPU的系统到内置10个或10个以上GPU的服务器的丰富产品组合。
这些系统可以为各种计算密集型任务加速,包括用于新药研发的分子动力学模拟、建立更好的按揭贷款审批财务模型等。

继上月NVIDIA Ampere架构和NVIDIA A100 GPU发布后,全球头部供应商预计将发布超过50款内置A100的服务器。其中30款系统预计将在今年夏天上市,余下20余款将于年底上市。
今天,NVIDIA与多家全球领先服务器制造商推出多款系统,具有多种不同的设计和配置。以下服务器制造商将提供内置NVIDIA A100的系统:
(1)华硕ESC4000A-E10服务器,每台可配置4个A100 PCIe GPU;
(2)Atos的BullSequana X2415系统,配置有4个NVIDIA A100 Tensor Core GPU。
(3)思科的Cisco Unified Computing System服务器和超融合架构系统Cisco HyperFlex,将支持NVIDIA A100 Tensor Core GPU。
(4)戴尔科技的PowerEdge服务器和解决方案将支持NVIDIA A100 Tensor Core GPU。
(5)富士通将在其PRIMERGY服务器系列中引入A100 GPU。
(6)技嘉科技G481-HA0、G492-Z50和G492-Z51服务器支持多达10个A100 PCIe GPU,G292-Z40服务器支持多达8个A100 PCIe GPU。
(7)HPE ProLiant DL380 Gen10服务器将支持A100 PCIe GPU,HPE Apollo 6500 Gen10系统也将依靠A100 PCIe GPU加速HPC和AI工作负载。
(8)浪潮发布了八款内置NVIDIA A100的系统,包括使用A100 PCIe GPU的NF5468M5、NF5468M6和NF5468A5,使用八路NVLink的NF5488M5-D、NF5488A5、NF5488M6和NF5688M6,以及使用十六路NVLink的NF5888M6。
(9)联想ThinkSystem SR670 AI-ready服务器等部分系统将支持A100 PCIe GPU。联想将在今年秋天扩大整个ThinkSystem和ThinkAgile产品系列的供应。
(10)One Stop Systems将为其OSS 4UV Gen 4 PCIe扩展系统提供多达8个NVIDIA A100 PCIe GPU,使AI和HPC客户可以横向扩展他们的Gen 4服务器。
(11)Quanta/QCT将提供D52BV-2U、D43KQ-2U和D52G-4U等多款QuantaGrid服务器系统,支持多达8个NVIDIA A100 PCIe GPU。
(12)Supermicro的4U A+ GPU系统将支持多达8个NVIDIA A100 PCIe GPU和2个附加高性能PCI-E 4.0扩展插槽。此外,该系统还支持其他1U、2U和4U GPU服务器。
NVIDIA正在扩展NGC-Ready认证系统产品组合。系统供应商可直接与NVIDIA合作,为内置A100的服务器取得NGC-Ready认证,从而可向客户保证,经过认证的系统具有运行AI工作负载所需的性能。
NGC-Ready系统使用来自NVIDIA NGC注册中心的GPU优化AI软件进行测试,该软件可用于数据中心、云端和边缘内置NVIDIA GPU的系统。
支持NVIDIA A100的NVIDIA Ampere优化软件现已上市,包括CUDA11、50多个CUDA-X库的新版本、多模式对话式AI服务框架NVIDIA Jarvis、深度推荐应用框架NVIDIA Merlin、RAPIDS开源数据科学软件库套件、NVIDIA HPC SDK等。
凭借这些功能强大的软件工具,开发者们能够构建并加速HPC、基因组学、5G、数据科学、机器人学等领域的应用。
三、新款UFM新平台:用AI检测网络性能
今天NVIDIA还推出了NVIDIA Mellanox UFM Cyber-AI平台和UFM系列第三款产品UFM Telemetry平台。
UFM平台产品系列已管理InfiniBand系统近十年,UFM Cyber-AI平台对UFM Enterprise平台进行了补充,提供网络监视、管理、性能优化、配置检查和安全电缆管理功能,可检测安全威胁和运行问题,预测网络故障,并能大幅减少InfiniBand数据中心的停机时间。

UFM Telemetry平台具能够捕获实时网络遥测数据,该数据将被传输到本地或云端数据库,用于监视网络性能和验证网络配置。
UFM Cyber-AI平台运用AI分析技术,通过实时和历史遥测及工作负载数据来学习数据中心的运行节奏和网络工作负载模式,根据这一基准追踪系统的运行状况和网络修改并检测性能下降、使用情况和配置文件更改。
该全新平台可发出警报,提示系统和应用异常行为、潜在系统故障以及威胁,并执行纠正措施。它还能在系统遭受黑客攻击,安装恶意应用(例如加密币挖币软件)时发出安全警报。
这减少了数据中心的停机时间,而根据ITIC的研究,停机1小时所造成的成本通常在30万美元以上。
NVIDIA Mellanox网络事业部高级营销副总裁Gilad Shainer称,基于UFM Cyber-AI平台,系统管理员可以快速检测和响应潜在的安全威胁并解决即将发生的故障,从而节省成本,确保客户业务的连续性。
四、软硬件双管齐下,打破大数据分析基准记录
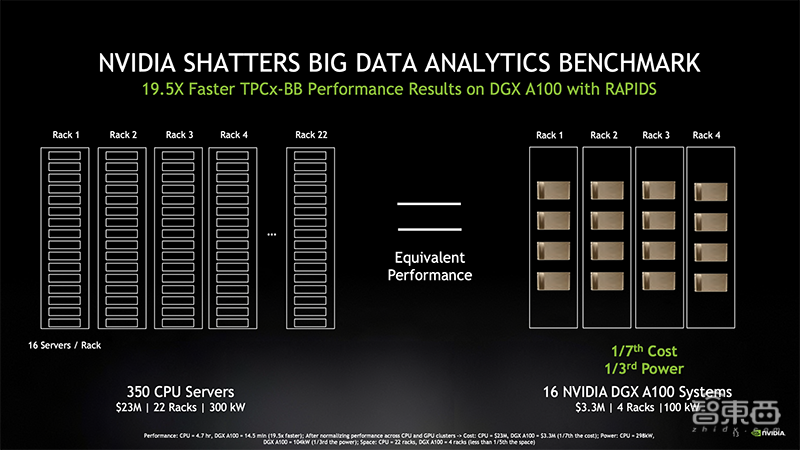
NVIDIA所展示的标准大数据分析基准(TPCx-BB)性能是此前纪录的近20倍。
TPCx-BB是用于实际ETL(提取、转换、加载)和机器学习工作流程的企业大数据基准测试,该基准测试的30个查询项目包含多种大数据分析用例。其特点是将SQL与结构化数据的机器学习、自然语言处理和非结构化数据相结合的查询,反映了现代数据分析工作流中的多样性。
过去该基准测试只在CPU系统上运行,但当运行规模非常大的数据工作负载时,CPU往往遇到瓶颈。
而NVIDIA在16台DGX A100系统组成的集群上使用RAPIDS开源数据科学软件库套件,仅用14.5分钟就完成了TPCx-BB基准测试,而目前在CPU系统上的运行记录是4.7小时。
为运行该基准测试,NVIDIA采用RAPIDS用于数据处理和机器学习,Dask用于水平扩展,使用UCX开源库进行超快速通信,所有这些软件工具都在DGX A100上得到了增强。
DGX A100系统将基于NVIDIA Ampere架构的NVIDIA A100 Tensor Core GPU和NVIDIA Mellanox网络功能整合到一套易于扩展的完整系统中,能高效地支持单一软件定义平台上的分析、AI训练和推理。
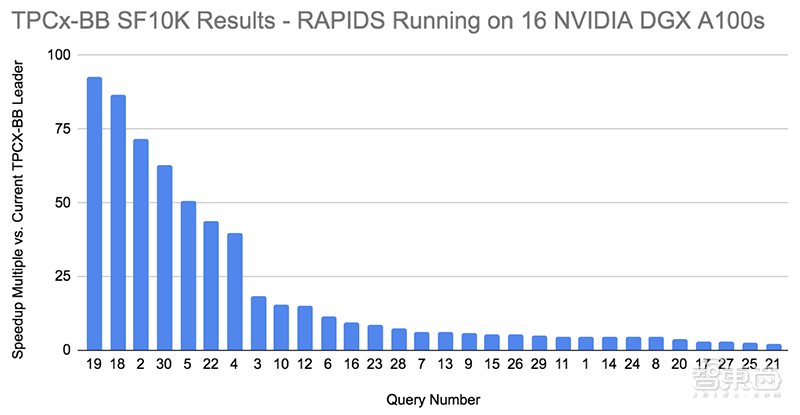 ▲30个TPCx BB基准测试查询结果。RAPIDS在16台DGX A100系统上运行,为每个10TB测试查询提供上述相对性能提升。
▲30个TPCx BB基准测试查询结果。RAPIDS在16台DGX A100系统上运行,为每个10TB测试查询提供上述相对性能提升。
在SF10000 TPCx-BB级别,NVIDIA测试可得出10 TB以上数据工作负载的结果。
这一规模下,查询的复杂策划高难度会迅速增加执行时间,从而增加数据中心的支出。而具有弹性的DGX A100架构可以解决这些问题。
借助来自NVIDIA硬件合作伙伴的全新NVIDIA A100 Tensor Core GPU系统,数据科学家们将甚至能够选择通过A100的突破性性能加速工作负载。
RAPIDS TPCx-BB基准是一个由众多合作伙伴和开源社区共同参与的项目。
TPCx-BB查询通过一系列Python脚本实现,这些脚本使用RAPIDS数据帧库、cuDF、RAPIDS机器学习库、cuML、cuPy、BlazingSQL和Dask作为主库。Numba被用于在用户定义的函数中实现自定义逻辑,spaCy被用于命名实体识别。
可以说,RAPIDS和整个PyData生态系统,是打破大数据分析TPCx-BB基准记录所不可获缺的基础。
五、先进互连技术为全球顶尖天气预报机构的超算提供支持
超级计算正在改变天气预报与模拟。气象和气候模型都是计算和数据密集型模型,预测质量取决于模型的复杂性和高分辨率。
其中分辨率取决于超级计算机的性能,而超级计算机的性能又取决于互连技术是否能够在各计算资源之间快速、有效并且以可扩展的方式移动数据。
相较其他互连技术,NVIDIA Mellanox InfiniBand网络具有更高的性能、可扩展性和弹性,是目前市面上唯一的200Gb/s高速互连产品,通过先进的端对端自适应路由、拥塞控制和服务质量实现最高网络效率。
凭借技术优势,NVIDIA Mellanox InfiniBand网络已成为气候研究和天气预报应用的实际标准。
西班牙气象局、中国气象局、芬兰气象局、NASA和荷兰皇家气象局等许多全球领先的气象服务机构都选择NVIDIA Mellanox InfiniBand网络加速其超级计算平台。

例如,北京市气象台选择200 Gigabit HDR InfiniBand互连技术加速其全新超级计算平台。该平台将被用于增强天气预报、改进气候和环境研究,并将被用于2022年北京冬季奥运会的天气预报。
法国国家气象局(Meteo France)选择HDR InfiniBand加速其两台全新的大型超级计算机。该机构为交通运输、农业、能源和许多其他行业的公司以及众多新闻媒体与全球体育和文化活动提供天气预报服务。
欧洲中程天气预报中心(ECMWF)的全新超级计算机将在今年部署,为欧洲30多个国家的天气预报和预测研究人员提供支持,而在HDR InfiniBand技术的支持下,该超级计算机有望使该中心的气象和气候研究计算能力提高5倍。
据悉,更多全球领先的气象和气候机构将于今年宣布部署使用HDR InfiniBand的新超级计算平台。
结语:引领新的计算革命
无论是AI、云计算等新兴产业的持续发展,还是越来越多传统企业走向数字化和智能化转型,数据和加速计算日益成为决定企业洞察力、效率以及创新速度的关键要素。
今年GTC大会上推出的A100 GPU已如一颗惊雷响彻AI和数据科学领域,而随着更多内置A100的多款服务器的问世,NVIDIA正与服务器制造商等合作伙伴一起, 解决AI、数据科学和科学计算领域最复杂的挑战,引领新的计算革命。
