








出品 | 智东西公开课
讲师 | NVIDIA 解决方案架构师王闪闪
提醒 | 关注智东西公开课公众号,并回复关键词“BERT“,即可获取课件。
导读:
6月3日晚,NVIDIA解决方案架构师王闪闪与循环智能解决方案专家王雷在智东西公开课共同参与了会话式AI&金融公开课NVIDIA专场的直播讲解。其中,王闪闪老师的主题为BERT模型详解。
在本次讲解中,王闪闪老师先为我们详细讲解了BERT模型原理及其成就,后为我们介绍了NVIDIA开发的Megatron-BERT。
本文为此次专场主讲环节的图文整理:
正文:
大家好,我是NVIDIA解决方案架构师王闪闪。今天主要和大家分享两个部分的内容:
1. BERT模型深度解析
2. 大规模参数的语言模型Megatron-BERT
我们今天主要是温故知新我先带大家复习一下BERT模型的整体架构,内容不会特别偏数学,主要把BERT一些要点给大家说清楚,包括BERT的输入/输出以及具体它是怎么工作的,然后介绍NVIDIA基于BERT开发出的一系列好的模型。
首先介绍一下自然语言处理常见的应用方向,第一类是序列标注,比如命名实体的识别、语义标注、词性标注,循环智能也是用了序列标注。第二类是分类任务,如文本分类和情感分析,这个方向目前在量化金融领域,尤其是对冲基金上应用性很强,尤其是情感分析。我记得3、4年前,有一条新闻说斯坦福大学的一个硕士生,暑期在他的宿舍里用几块GPU卡,自己搭建了一个小的超级计算机,他把Twitter上的信息全部录下来,每天更新。他使用了BERT进行情感分析,把每天每个人的信息分成三类:positive积极、neutral中性、negative消极。他把三类情感的量化信息和当天纳斯达克股票的升跌情况汇总,进行了统计分析,发现如果Twitter上的信息大部分都是积极的,那么股票就有很大的概率会上涨。我们现在把这类数据叫做情感分析因子,它在股票分析上是一个特别重要的推进方向,能让模型越发准确。第三类NLP应用方向就是对句子关系的判断,如自然语言的推理、问答系统,还有文本语义相似性的判断。最后一类,是生成式任务,如机器翻译、文本摘要,还有创造型的任务比如机器写诗、造句等。
一、BERT模型深度解析
现在我们进入正题:对BERT的讲解。要了解BERT,首先我们要说一下Transformer,因为BERT最主要就是基于Transformer和注意力机制,这两点也是BERT能从GPT、RNN、LSTM等一系列架构中能脱颖而出的很大原因。Attention,专业的叫法是Attention Mechanism,Attention 是一个Encoder + Decoder的模型机制。Encoder-Decoder模型是在深度学习中比较常见的模型结构:在计算机视觉中这个模型的应用是CNN+RNN的编辑码框架;在神经网络机器翻译的应用是sequence to sequence模型,也就是seq2seq。而编码(Encoder)就是将序列编码成一个固定长度的向量,解码(Decoder)就是将之前生成的向量再还原成序列。
那么问题来了,为什么要在Encoder-Decoder模型机制中引入Attention呢?因为 Encoder-Decoder模型有两个比较显著的弊端。1)是Encoder会把序列信息压缩成一个固定长度的向量,那么在Encoder的输出中,我们暂且把它叫做语义编码c,c就有可能无法完全地表示出全部序列的信息,尤其是当信息特别长时。2)先输入到网络中的信息会被后输入的信息覆盖掉,输入的信息越长,对先前输入信息的遗忘程度就越大。因为这两个弊端,Decoder在解码的一开始就没有获得一个相对完整的信息,也就是语义编码c没有一个相对完整的信息输入,那么它解码的效果自然就不好。有的同学可能会说想要解决RNN记忆力差的问题,可以考虑用LSTM。我们的确可以考虑LSTM,但LSTM对超长距离的信息记忆,效果也不是很好。
我们再来看看Attention为什么能够解决这个问题。Attention,顾名思义是注意力。它是模仿人类的注意力,人类在处理一个问题时会把注意力放到那个特别重要的地方,比如我们在短时间内去看一张照片,第一眼落到照片上的位置可能是某个建筑物或者是某个人,这取决于我们不同的目的和兴趣等。我们不会在短时间之内记清楚甚至是看清楚照片上的全部细节,但是我们会将注意力聚焦在某个特定的细节上并记住它。Attention模型最终输出结果也是能够达到这么一个效果。
Attention的机制最早也是应用在计算机视觉上面,然后是在自然语言处理上面发扬光大。由于2018年在GPT模型上的效果非常显著,所以Attention和 Transformer才会成为大家比较关注的焦点。之所以Attention的能力在NLP领域得到了彻底释放,是因为它解决了RNN不能并行计算的弊端,Attention使其每一步的计算不依赖于上一步的计算,达到和CNN一样的并行处理效果。并且由于Attention只关注部分的信息,所以它的参数较少,速度就会快。其次RNN记忆能力较差,所以大家一开始想到的解决方式都是用LSTM和GRU(Gated Recurrent Unit)来解决长距离信息记忆的问题,但是都没有起到很好的效果。Attention由于只关注长文本中的一个小部分,可以准确地识别出关键信息,所以取得了特别不错的效果。
下面我们来说一下Attention是怎么实现的聚焦。主要是因为它是采用了双向的RNN,能够同时处理每个单词前后的信息。在Decoder中,它首先计算每一个Encoder在编码隐藏层的状态,然后会和Decoder隐藏层状态比较,做出相关程度的评定。得到的权值会通过softmax归一化得到使用的权重,也就是我们前面所说的编码向量c。然后对Encoder中对应的不同状态的权重进行加权求和,有了编码c之后,我们就可以先计算Decoder隐藏层的状态,然后再计算Decoder的输出。这就是一个比较完整的在BERT当中运用Attention以及Encoder-Decoder模型的使用案例。Attention根据计算区域、权值的计算方式等会有很多不同变种。
不止是在NLP领域,在其他很多领域中,Transformer的模型由于很好用都是大家首选的,主要的一个运用机制就是Attention。我们之后会说到的Transformer模型会用到 Multi-head Attention和Self-Attention。首先说一下Self-Attention,Self-Attention是将原文中每个词和该句子中所有单词之间进行注意力的计算,主要是为了寻找原文内部的关系。对应到阅读理解任务,这个模型就可以判定一篇文章中的两段话是不是同一个意思。Multi-head Attention,则是对一段原文使用多次的注意力,每次会关注到原文的不同部分,相当于多次地在单层中使用Attention,然后把结果给拼接起来。
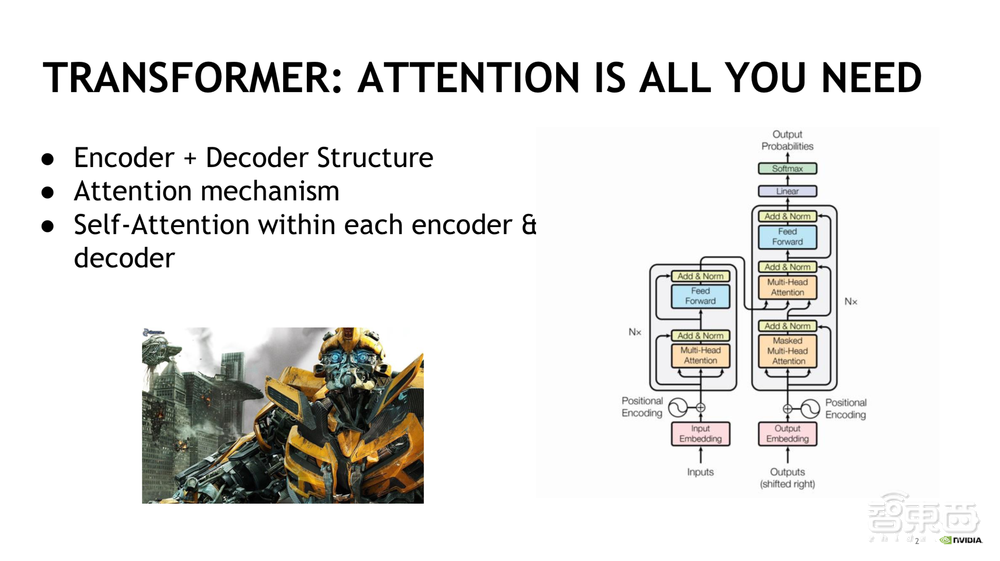
现在我们来讲一下Transformer,如PPT右侧图所示:
1)图左侧的是Encoder, Nx这里N=6,表示其是由6个layer组成的,每个layer里面的操作过程是一样的。而每个layer又是由两个sub-layer组成的,分别是Multi-head Attention和Fully Connected Feedforward Network。 每一个sub-layer都增加了Residual Connection和Normalization。
2)图右侧的是Decoder,与Encoder结构相似,但Decoder新加了Masked Multi-Head Attention,训练时output都是ground truth,为了确保预测的第n个位置不会接触到未来的信息,因此我们要把它mask掉,这也是为什么它叫做Masked Multi-Head Attention.
3)Positional Encoding也是一个非常重要的组成部分,主要是有两个思路方向:一是用不同频率的sin/cos三角函数来计算,二是做 Positional Embedding。大牛的研究论文表明用三角函数能带来两个较大的好处:一是无论序列有多长,由于sin/cos函数的使用,值域都会固定在-1~1上,于是就免除了Extrapolation(外推)的问题;二是它不受超长序列的限制。所以目前Positional Encoding都是选用sin(α+β)的公式。
再来讲一下Transformer的优势。首先在复杂度方面,它可以进行分层的计算。其次,由于Attention机制的使用,它可以进行并行化计算,Self-Attention可以直接计算序列中任意两点的点乘,而RNN只能按照词的位置逐一计算。
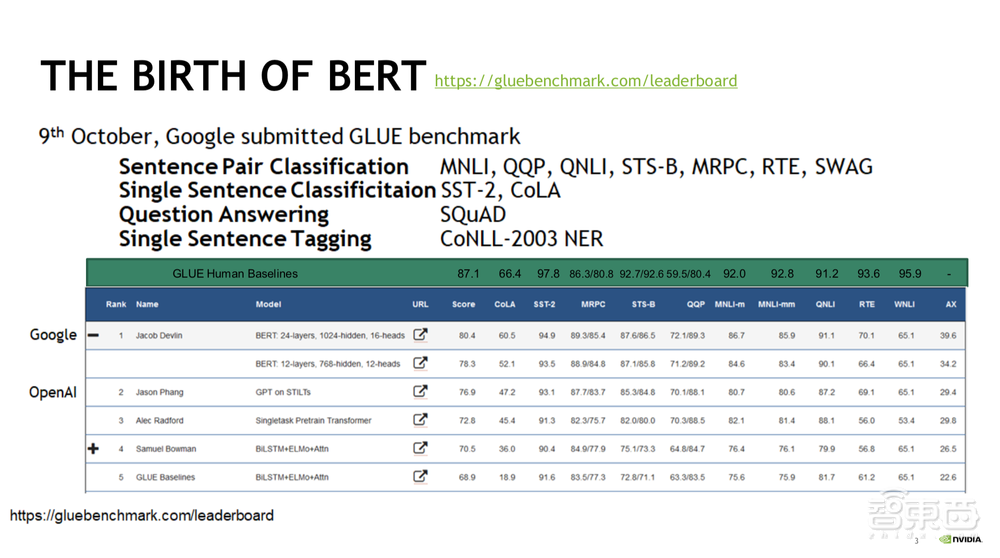
下面我们来看BERT都在哪些方面取得骄人成绩。2018年10月9日,谷歌提交了GLUE的benchmark,GLUE指的是通用语言理解评估基准,主要用来测试模型在广泛的自然语言理解任务中的鲁棒性。Sentence Pair Classification就是比较两句话是不是同一个意思。Single Sentence Classification是把句子进行归类,按照情绪或其他特征分类。Question Answering是问答系统。Single Sentence Tagging相当于命名实体的识别。主要用到的BERT有两类:一是BERT 12-layers(BERT-Base) ,二是BERT 24-layers(BERT-Large),比前者更深,有1024个hidden layer,16个Multi-Head Attention Mechanism。
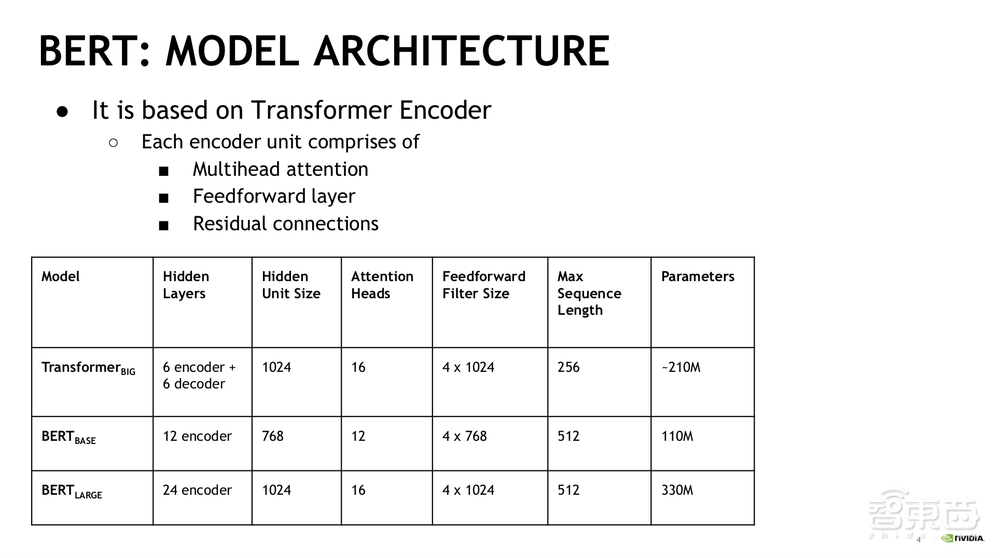
这张表格显示Transformer在Hidden Unit、Attention Heads、Feedforward Filter方面的尺寸与BERT-Large都是一样的。Max Sequence Length方面,BERT-Large能做到更长。Transformer大概有2.1亿个参数,BERT-Large有3.3亿个,BERT-Base大概有1.1亿个参数。
下面我们通过对比来看一下为什么BERT成为了最好用的NLP模型。首先来看ELMo(Embedding from Language Models),是对word embedding的动态调整,是双向神经网络语言模型。然后是GPT(Generative Pre-Training),是Open AI提出来的基于生成式预训练的单向模型,只能从左到右,而BERT和ELMo都是双向模型。有人评价BERT是用Word2Vec加上ELMo再加上GPT得到的,同时吸取了GPT跟ELMo的优点。比如在完形填空学习模型,需要迫使模型更多地依赖上下文信息来预测单词的情景中,BERT有非常强的纠错能力。
相比ELMo的LSTM模型, Transformer没有了长度限制的问题,由于Attention机制使得它能更好地捕获上下文信息的特征,它相比GPT的单向训练模式能对上下文信息理解得更加全面。这也是为什么BERT模型能够在很多方面达到SOTA(state-of-the-art)的水平。BERT的训练过程主要是用的Wikipedia(25亿词汇),文本信息很规整,除此还使用了8亿词汇的BooksCorpus,也是非常大的文本集。然后使用了无监督来做的分析,主要分为两种:Intra-sentence和Inter-sentence。Intra-sentence就相当于我把某个词mask掉,然后让BERT分析mask掉的词。Inter-sentence就是对于下一句话的预测(prediction)。
BERT的整个模型训练主要采用的就是刚才说的 Masked Language Model(MLM)来作为预训练模型。 BERT训练主要分为两步就是Pre-train和Fine-tuning:1)Pre-train主要是为了训练token-level的语义理解,NSP(Next-Sentence Prediction)就是旨在分析出被盖掉的词以及在sentence-level分析出下一句话。2)Fine-tuning是用训练好的参数进行模型初始化,使用Task-Specific Label的数据对整个模型进行训练,也就是说根据不同领域如金融医疗等,重新进行有针对性的训练。这也是为什么我们说BERT是Task-Specific的模型。
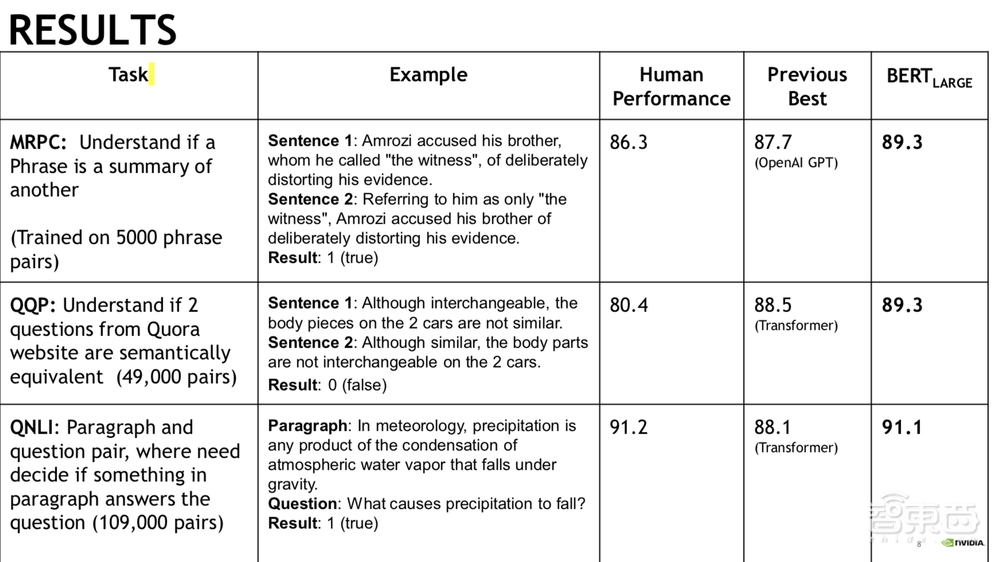
下面我们来看一下结果。在判定两个句子含义是否一样的任务中,human performance(人类水平)达到了86.3分,GPT可以实现到87.7,而BERT-Large达到了89.3分,超过了人类。在使用Quora数据集来判断两句话相关性的任务中,BERT-Large超过了人类的预测水平。在对于段落中寻找问题回答的任务中,BERT-Large和人类水平基本持平。在分类任务方面,BERT-Large的表现远超之前的SOTA所能达到的水平;在斯坦福问答集(SQuAD v1.1)任务中,BERT-Large破了记录,且在命名实体识别方面也效果卓越。SWAG是指给定一个句子,让模型在四个选项中选出这句话后最有可能出现的下文,这是一个很难的任务,ESIM+ELMo只达到了59.1分,BERT取得了86.6分。
二、大规模参数的语言模型— Megatron-BERT
Megatron-BERT是英伟达的工程师做的,有两个较大的方向:1)在NLP模型中,随着模型参数越来越大、模型体积越来越大,性能会越好但是就不可能只用一块GPU就可以进行数据并行化的训练过程,比如GPT3.0就是这样一个很大的模型。并行计算有两种,一是数据并行,二是模型并行。从BERT-Base到BERT-Large的过程中,模型性能得到了很大提升,但是我们发现当模型参数一旦超过了3.36亿个,收敛的效果就会变得非常差。一个有效的解决办法就是,如在GPT2中,我们将Layer Normalization和Residual Connections交换位置,这样当我们将参数从3.3亿个扩充到7.5亿个的时候,系统的收敛效果是越来越好的。(如下图所示)
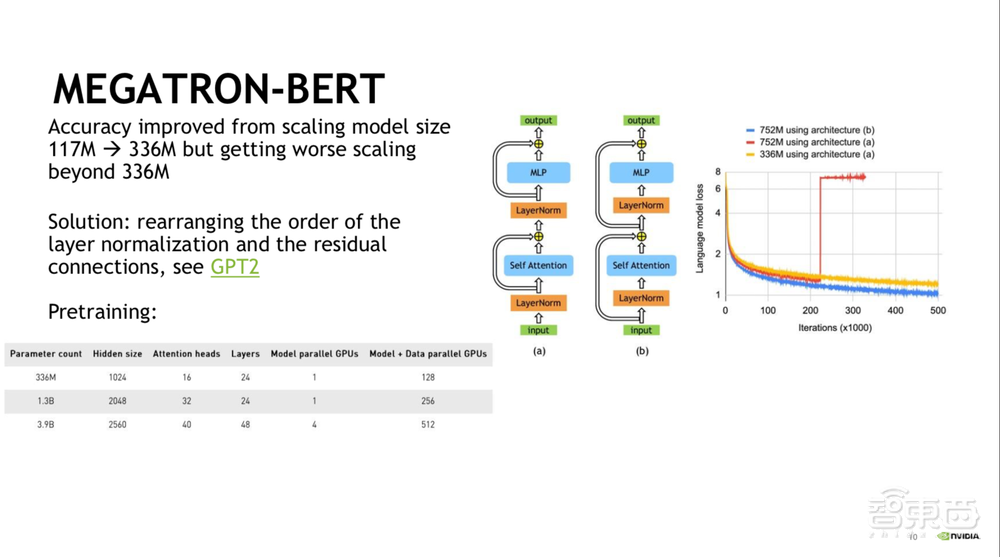
英伟达的工程师也由此产生了一个好奇:BERT模型到底可以做到多大?以3.3亿个参数为基准,我们做了一个非常疯狂的试验,也就是Megatron-BERT,将参数分别上升到了13亿和39亿,多卡训练,模型并行是很难攻破的,目前也是学术界在积极推进的研究方向,好的模型并行方式有两种:GPipe和Mesh-Tensorflow。而Megatron-BERT采用的是Mesh-Tensorflow的方式,关注每个layer里面进行融合的GEMM来减少同步,其次代码语言是Python并采用了PyTorch,PyTorch的并行效果会比Tensorflow好很多。除此还采用了最新的混合精度,就是用Tensor Core,是在Volta和图灵架构的GPU上可实现的,用FP16数据,在卡与卡之间采用CUDA通讯库,卡与卡之间通讯速度非常快,可以把它想象成一块大的GPU卡来进行训练。最后我们在39亿参数量上,采用4个GPU进行模型并行,再加上数据并行共计使用512块GPU。
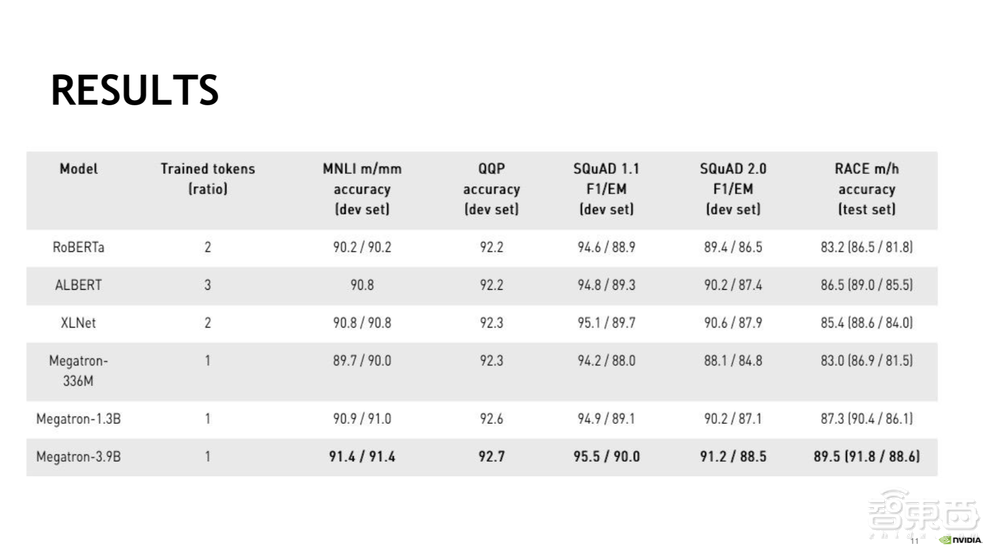
我们来看一下这页展示的结果,MNLI和QQP都采用了GLUE的标准并在development set上进行的测试,整个测试过程是与RoBERTa一样的,通过调整寻找最佳的batch size和learning rate。鉴于每一次跑都希望有randomness,所以我们选择了5个seed来做初始化。最后我们是选择5个训练结果的中位数来做对比。在此,Megatron-3.9B在MNLI、QQP、斯坦福问答集、阅读理解几个任务上都刷新了记录。
两个星期之前英伟达的CEO黄仁勋介绍了NVIDIA最新的显卡:安培架构的A100,基于此我们也发布了会话式AI服务的应用框架-Jarvis,是开源的,方便大家进行尝试,可以建立ASR 、NLU、TTS等语音识别、自然语言理解推论模型。NLU就是基于我们的BERT模型,ASR用的是英伟达自己的Jasper和QuartzNet,TTS用的是WaveGlow模型。我们还在Megatron-BERT中采用了GPT2,使用了83亿的参数量,在8x A100上做了测试,用FP16加模型优化,结果显示Megatron-GPT2比V100在速度方面提升了2.5倍。所以,我们可以看到BERT模型现在的性能提升主要有两个方向:一是算力,在强大算力基础上,摩尔定律逐渐消亡,CPU完全没有办法在人工智能领域再起到主导作用,GPU由于有并行加速的作用要承担起主导地位。在NLP领域,V100和A100由于其强大的算力,相信在未来也会为BERT发展起到推动作用。
