








芯东西(ID:aichip001)
文 | 心缘
芯东西6月28日报道,2020年的突发事件拨乱了太多产业的阵脚,AI芯片产业也似乎热度渐熄。一家英国AI芯片创企却在这一时期,稳稳地切入国内科技巨头阿里和百度的生态圈。
就在今年5月,成立刚满四年的英国初创公司Graphcore分别公布和阿里巴巴、百度合作的新动向。阿里宣布Graphcore支持ODLA的接口标准,百度宣布Graphcore成为飞桨硬件生态圈的创始成员之一。
同月,在英国Intelligence Health峰会上,微软机器学习科学家分享用Graphcore的IPU芯片训练微软COVID-19影像分析算法CXR,能够在30分钟之内完成在NVIDIA GPU上需要5个小时的训练工作量。
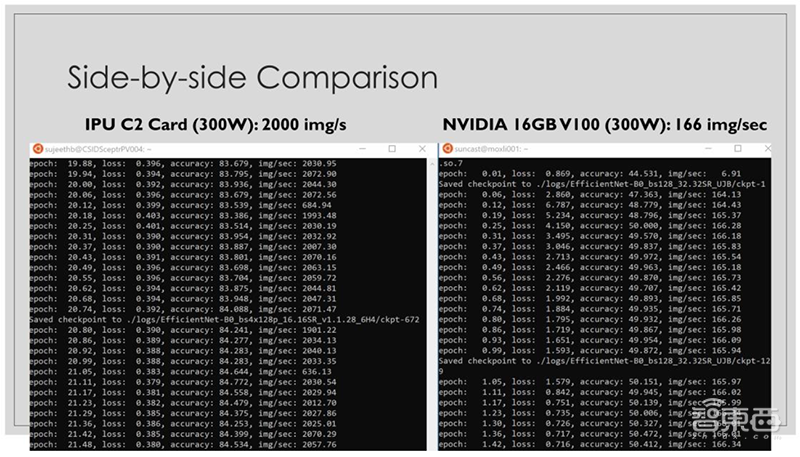 ▲300W功耗情况下,IPU(左)以2000 img/s的平均速率进行训练,NVIDIA V100平均速率约为166 img/s,速度相差10倍以上
▲300W功耗情况下,IPU(左)以2000 img/s的平均速率进行训练,NVIDIA V100平均速率约为166 img/s,速度相差10倍以上
也是在这个月,英伟达(NVIDIA)为AI和数据科学打造的最强GPU A100横空出世,给布局云端AI芯片市场的其他公司带来新的压力。
不过Graphcore显得相对淡定。Graphcore高级副总裁兼中国区总经理卢涛相信,即便是Graphcore第一代IPU产品也不会输于A100,今年他们还将发布下一代7nm处理器。
Graphcore的自信并非空穴来风,凭借创新芯片架构IPU,这家成立刚满四年的英国初创公司,不仅有DeepMind联合创始人Demis Hassabis、剑桥大学教授兼Uber首席科学家Zoubin Ghahramani、加州大学伯克利教授Pieter Abbeel、OpenAI多位联合创始人等多位AI大牛为其背书,还吸引到微软、博世、戴尔、三星、宝马等巨头注资。
这样一个在AI芯片界猛刷存在感的明星创企,背后有着怎样的底气?
近日,Graphcore高级副总裁兼中国区总经理卢涛、 Graphcore销售总监朱江第一次在中国详尽地介绍了Graphcore的核心芯片架构及产品、配套软件工具链,并分享了其芯片在五类垂直场景的应用实例及性能表现。
一、英国小镇里诞生的AI芯片独角兽
2012年1月,雪后的英国小镇巴斯,Nigel Toon与Simon Knowles正在讨论一个改变AI芯片架构的创新设想。
 ▲Graphcore CEO Nigel Toon和CTO Simon Knowles
▲Graphcore CEO Nigel Toon和CTO Simon Knowles
经过四年模拟了数百种芯片布局的计算机测试方法,两人于2016年6月在英国布里斯托成立AI芯片公司Graphcore,此后继续处于神秘的研发状态。
知名资本伸出的橄榄枝,使得这家创企始终处于聚光灯下,宝马、博世、戴尔、微软、三星等巨头纷纷参与投资,至今Graphcore累计融资超过4.5亿美元,整体估值约为19.5亿美元。

不仅如此,数位AI大牛对其IPU芯片架构赞誉有加。
英国半导体之父、Arm联合创始人Hermann爵士曾评价说:“在计算机历史上只发生过三次革命,一次是70年代的CPU,第二次是90年代的 GPU,而Graphcore就是第三次革命。”
AI教父Geoff Hinton教授也说过:“我们需要不同类型的计算机来处理一些新的机器学习的系统。”他指出IPU就是这样一个系统。
到2019年11月,Graphcore潜心打造的IPU产品官宣量产,随后与微软、百度、Qwant、Citadel、帝国理工学院、牛津大学等多个合作伙伴、云计算厂商、研究实验室以及高校等展开了相关合作。
如今,Graphcore所做的产品包括了硬件、软件和IPU的系统解决方案。
IPU是Graphcore专为机器智能设计的创新处理器架构,宣称在现有及下一代模型上,性能远超NVIDIA V100 GPU。
例如它能将自然语言处理(NLP)处理速度可提升20%-50%,为图像分类带来6倍的吞吐量而且是更低的时延,在一些金融模型方面训练速度能够提高26倍以上。
目前IPU已实现量产,通过访问微软Azure等云计算平台,或者购买戴尔服务器等产品,均可获取IPU资源。在国内,Graphcore也正在与金山云合作,拟上线一个针对中国开发者和创新者的云业务。
除了芯片产品走向落地,在过去6-12个月,Graphcore在全球版图快速铺开,迄今有全球员工450人,分布在北京、上海、深圳、台北、布里斯托、伦敦、剑桥、挪威、奥斯陆、西雅图、帕拉奥图、纽约、奥斯汀、东京、首尔等地。
二、以计算图为表征的创新AI芯片架构
Graphcore的自研芯片架构诞生的背景,源于过去几年AI算法模型规模呈指数级增长,需要更适宜的全新处理器架构。
相较传统科学计算或高性能计算(HPC),AI或者说机器智能有一些特性,包括大规模并行就散、稀疏数据结构、低精度计算,以及在训练推理过程中的数据参数复用、静态图结构。
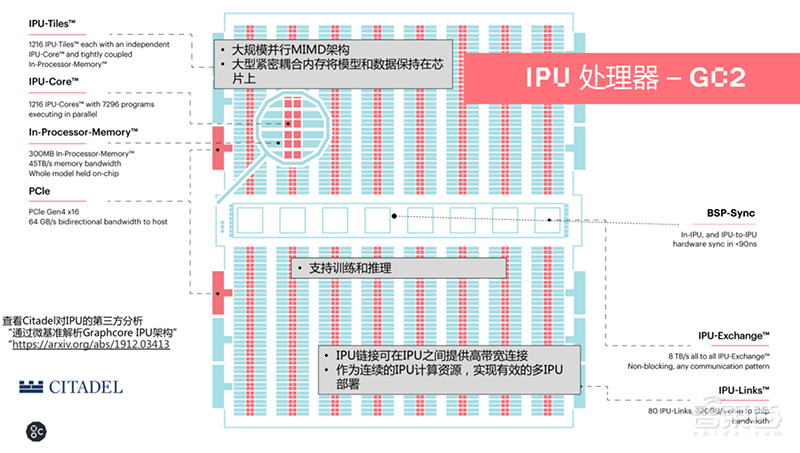
Graphcore IPU即是针对计算图的处理设计而成,相比传统智能处理器,IPU有三个核心区别:采用MIMD架构、所有模型在片内处理、可解决大规模并行计算处理器核之间的通信效率。
具体而言,IPU采用大规模并行MIMD的处理核,抛弃了外部DDR,在片内做到300MB的大规模分布式片上SRAM,以打破内存带宽对整体性能构成的瓶颈。
相较CPU的DDR2子系统或是GPU的GDDR、HBM来说,IPU这一设计可将性能提升10-320倍。与访问外存相比较,时延基本为1%,可忽略不计。

当前已量产的IPU处理器为GC2,拥有256亿个晶体管,在120瓦功耗下,混合精度算力可达125TFLOPS。
GC2采用台积电16nm工艺,片内包含1216个独立的IPU处理器核心(Tile),整个GC2包含7296个线程,支持7296个程序并行运行。其内存带宽为45TB/s、片上交换是8TB/s,片间IPU-Links为2.5Tbps。
为了解决并行硬件的高效编程问题,IPU通过硬件支持BSP协议,并通过BSP协议把整个计算逻辑分成了计算、同步、交换。
这对软件工程师和开发者来说非常易于编程,因为不必处理locks这个概念,也不必管任务具体在哪个核上运行。
目前IPU是世界上目前第一款BSP处理器,BSP技术在谷歌、Facebook、百度之类的大规模数据中心均有使用。
卢涛介绍说,IPU重点面向云端训练以及对精度和延时要求高的推理场景,还有一些训练和推理混合的场景。
在精度方面,IPU当前不支持整数int8,主要支持FP16、FP32以及混合精度。
当前应用较大的主流计算机视觉类模型以int8为主,而自然语言处理推理以FP16、FP32为主流数据格式,IPU使用FP16精度在ResNeXt、EfficientNet等新兴视觉模型中性能功耗比同样具有优势。
未来,Graphcore的推进策略还是训练和推理并行,但会更聚焦于一些对精度和时延要求更低、对吞吐量要求更高的场景。另外,他们也看到在推荐算法等应用出现一些希望同时实现训练和推理的需求。
三、软件支持容器化部署,上线开发者社区
硬件芯片架构是基础,而软件则是提升用户体验的关键利器。
对于AI芯片来说,芯片研发出来只是第一部分,要能落地到产业中,还需展现出色的可移植性、可开发性、可部署性,能提供完善的工具链和丰富的软件库,可实现与主流机器学习框架无缝衔接,而整个链条全部打通需要非常大的投入。
今年5月26日,全球知名科技分析机构Moor Insights & Strategy曾发表了一篇研究论文 《Graphcore的软件栈:Build To Scale》,其中写道:“Graphcore是我们目前已知的唯一一家将产品扩展到囊括如此庞大的部署软件和基础架构套件的初创公司。”
卢涛认为,对于AI芯片来说,真正商业化的衡量标准在于三点:是否有平台化软件的支持、是否有大规模商用部署软件的支持、是否能实现产品化的部署。

对此,Graphcore的Poplar SDK提供了完整的软件堆栈来执行其计算图工具链,有四个主要特性:
(1)开放且可扩展的Poplar库:目前已提供750个高性能计算元素的50多种优化功能,修改和编写自定义库。
(2)直接部署:支持容器化部署,可快速启动并且运行。标准生态方面,可支持Docker、Kubernetes,还有像微软的Hyper-v等虚拟化的技术和安全技术。
(3)机器学习框架支持:支持TensorFlow 1、TensorFlow 2、ONNX和PyTorch等标准机器学习框架,很快也将支持百度飞桨。
(4)标准生态支持:通过微软Azure部署、Kubernetes编排、Docker容器以及Hyper-V虚拟化和安全性,已生产就绪。
目前Poplar SDK支持最主要的三个Linux操作系统发行版本:ubuntu、RedHat Enterprise Linux、CentOS。
ubuntu是迄今在AWS上最流行的一个操作系统,RedHat Enterprise Linux对一些企业级用户做私有云非常重要,而CentOS在中国互联网公司中应用广泛。
今年5月,Graphcore推出分析工具PopVision Graph Analyser,并上线Poplar开发者文档和社区。
使用IPU编程时,可借助PopVision可视化图形展示工具来分析软件运行的情况、效率调试调优等。
Poplar开发者文档和社区中提供了大量的Poplar user guide和文档。开发者可通过www.graphcore.ai/developer访问。

此外,Graphcore在Stack Overflow上也有针对IPU开发者的知识门户网站,并在知乎上开辟了新的创新者社区,未来通过知乎将更多深度文章呈现给开发者和用户。
据卢涛介绍,有些国内用户反馈,认为Poplar的应用性优于CUDA,执行同样的任务,在Poplar上开发速度更快。
四、案例源代码可下载,秀五大垂直应用
当前基于IPU的应用已覆盖了机器学习的各个应用领域,包括自然语言处理(NLP)算法、图像/视频处理、时序分析、推荐/排名以及概率模型。
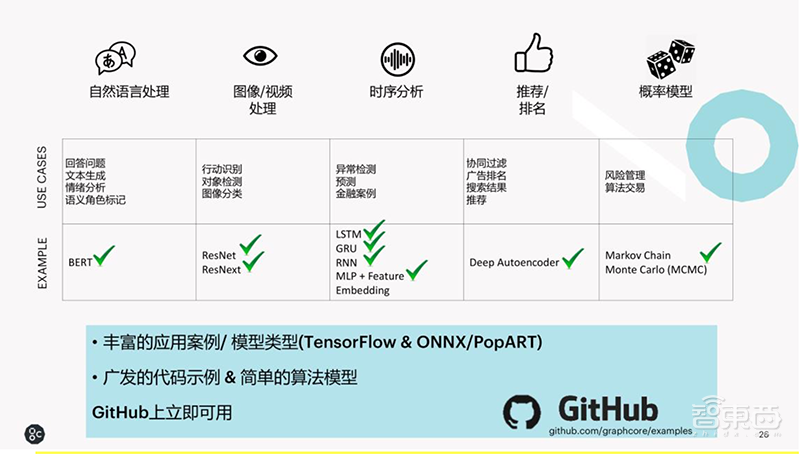
这些应用案例和模型已在TensorFlow、ONNX和Graphcore PopARTTM上可用,所有源代码均可在Github上下载。
相较NVIDIA V100,IPU在自然语言处理、概率算法、计算机视觉算法等应用均展现出性能优势。

▲对比GPU,IPU在运行时展现的性能优势
例如训练BERT,在NVLink-enabled的平台上大约要50多小时才能做到一定精度,而在基于IPU的戴尔DSS-8440服务器上只需36.3小时,速度提高25%。
做BERT推理时,同一时延,IPU吞吐量比V100高一倍;在训练MCMC时,IPU可将性能提升至V100的26倍。
运行ResNeXt推理时,IPU可实现6倍的吞吐量和1/22的延时。一些搜索引擎公司、医疗影像公司用户已通过IPU来使用ResNeXt的服务。
Graphcore销售总监朱江分享了IPU在金融、医疗、电信、机器人、云与互联网等五类垂直领域的应用实例。
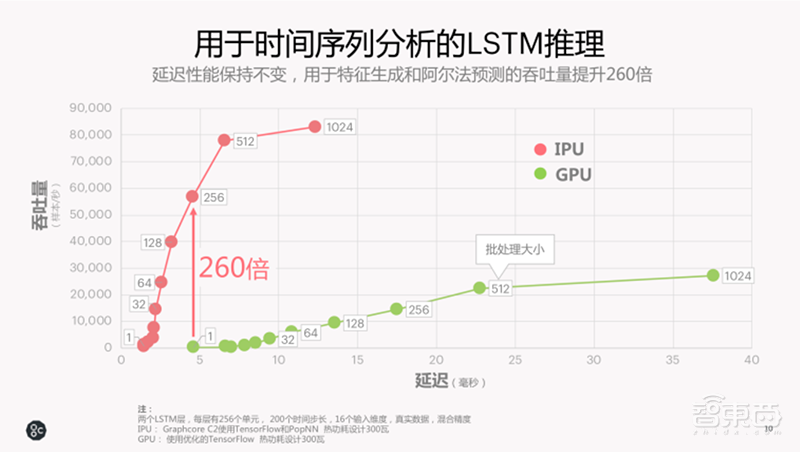
1、金融:LSTM推理性能提升260倍
IPU在算法交易、投资管理、风险管理及诈骗识别领域等主要金融领域均表现出显著优势。
例如在推理方面,延迟性能不变时,IPU可将长短期记忆(LSTM)模型吞吐量提升260倍,对于不可向量化模型亦能取得非常好的效果。
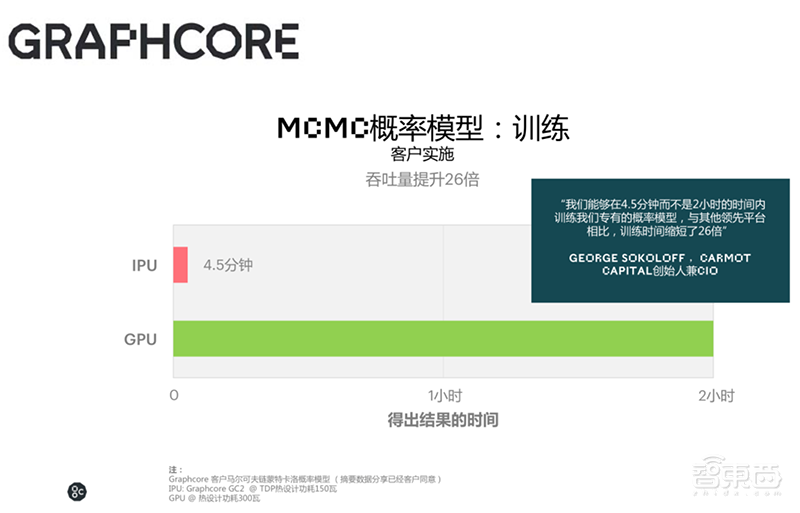
在训练方面,IPU可将MCMC概率模型的采样速度提高26倍,可进行阿尔法预测和期权定价,并能将强化学习的训练速度提升13倍。
采用多层感知器(MLP)预测销售结果时,相较Batch Size为512K的GPU,IPU吞吐量可提升5.9倍以上。
2、医疗和生命科学:影像分析能效提升4倍
医疗和生命科学包括新药研发、医学图像、医学研究、精准医疗等领域,涉及大量复杂的实验,加速计算过程对一些医学成果的更快产出至为重要。
微软用ResNeXt模型做颅内出血医学影像分析时,使用IPU较V100 GPU速度提高2倍,而功耗仅为V100的一半。

3、电信:加速5G创新应用
在电信领域,智慧网络、5G创新、预测性维护和客户体验方面均可应用IPU带来加速体验。
例如,机器智能可帮助分析无线数据的一些变化,运行LSTM模型进行网络流量矩阵预测时,采用IPU性能比GPU提升超过260倍。
网络切片和资源管理是5G中的一个特色,需要大量学习没被标记过的数据,需要应用强化学习模型,而在IPU上运行强化学习,训练吞吐量相较GPU最多可提高13倍。
4、机器人:解决经典光束法平差加速问题
在机器人领域,伦敦帝国理工学院Andrew Davison教授带领的机器人视觉小组在今年3月发表的论文中采用IPU来开发新算法,用以优化空间人工智能的效率。
相较使用Ceres中央处理器库的1450毫秒,IPU处理器仅在40毫秒内就解决了真正的光束法平差(Bundle Adjustment)这一经典的计算机视觉问题。
5、云与互联网:通过微软Azure开放
云与互联网是Graphcore早期及现在一直主要推广的一个重要领域。
当前微软在Azure公有云上已面向全球客户开放IPU公有云服务。此外,微软在一些自然语言处理、计算机视觉应用中已使用IPU实现加速。
另外欧洲搜索引擎公司也使用IPU进行ResNeXt模型推理,做了一个搜图识别应用,将性能提升3.5倍以上。
结语:即将接受中国市场的检验
今年疫情拖累全球许多行业的发展,但在卢涛看来,AI领域非但不会走向低潮,反而会有很大发展,尤其是自然语言处理类算法的发展会催生大量新应用。
疫情在全球范围内推动了数字化的加速,亦会推动数据中心等算力基础设施的建设进程。
卢涛认为,2020年是对AI芯片非常关键的一年,如果企业拿不出AI芯片产品,或者对软件不够重视,对后续持续化投入或将是很大的挑战。
从Graphcore与阿里、百度的合作来看,该公司今年在中国市场的推进明显提速。
尽管Graphcore在中国市场的整体启动较北美地区晚了一年左右,但卢涛期望,中国市场能在Graphcore全球市场占比达40%-50%。
此外,Graphcore也希望针对中国市场的需求,做产品的定制化演进。
据卢涛介绍,Graphcore有两支技术团队,一个是以定制开发为主的工程技术团队,另一个是以对用户的技术服务为主的现场应用团队。
其中工程技术团队承担两个方面的工作:一是根据中国本地AI应用的特点及需求,将一些AI算法模型在IPU上实现落地;二是根据中国本地用户对于AI的稳定性学习框架平台软件方面的需求,做功能性的一些开发加强的工作。
从上述种种应用案例来看,Graphcore已初步证明其创新IPU架构在多类AI应用上的出色训练和推理表现。而Graphcore还会继续“练内功、打基础”,攻克技术难题,加固技术实力。
不过芯片和相关软件工具的落地只是第一步,真正商业化战果如何,还要看市场给出的回音。
