








智东西(公众号:zhidxcom)
编 | 云鹏
智东西11月6日消息,Facebook近日公开自动语音识别(ASR)领域的wave2vec机器学习算法细节,可以使用原始音频作为训练数据并提高准确性。
wave2vec于今年年初问世,经过一年打磨,Facebook基于wav2vec的模型实现了2.43%的单词错误率,准确率高于Deep Speech 2、监督迁移学习(Supervised Transfer Learning)等主流算法。以下是外媒相关报道的原文编译。
一、自动语音识别的新方向
自动语音识别(ASR)不仅是Apple Siri之类的语音助手的基础部分,还是Nuance Dragon之类的听写软件以及Google Contact Center AI这样的客户支持平台的基础部分。它使机器能够解析关键短语和单词的发音,并使它们能够通过语调和音调来区分人。
正因如此,ASR是Facebook研究的重点领域,Facebook的对话技术被用于支持Portal的语音识别,并且该技术也用于对平台上的内容进行分类。为此,Facebook在今年早些时候的InterSpeech会议上详细介绍了wave2vec,一种新颖的机器学习算法,通过使用未经转录的原始音频作为训练数据来提高ASR准确性。
Facebook表示它在常见的Benchmark测试中取得了最高分数,并且使用的训练数据少了两个数量级。同时与领先的Deep Speech 2相比,错误率降低了22%。
Wav2vec最初是作为开源建模工具包Fairseq的一个拓展包发布的。Facebook表示,他们计划用wav2vec让关键词识别和声音检测技术拥有更好的数据表现,并且希望通过打破现有准则来改进他们的系统。
Facebook研究科学家兼软件工程师Michael Auli,Siddhartha Shah,Alexei Baevski和克里斯蒂安·菲根(Christian Fuegen)在博客文章中提到,“Wav2vec代表了ASR领域的一大进步,并且是语音识别领域一个充满希望的研究方向,尤其是对于那些缺乏大量语音数据的AI系统训练。”
二、减小数据量,降低人工成本
正如Auli和团队成员在论文中说的,ASR系统通常在音频序列上以频谱图(spectrograms)和相应的文本进行训练。因此要获得这些样本,就需要手工标记大量音频数据,这将花费宝贵的时间和资源。相比之下,wav2vec是自监督(self-supervised)的,这意味着它可以将未标记数据和少量标记的数据结合起来使用。

▲wav2vec的运作流程范例
Wav2vec首先训练一个模型,以区分真实数据和干扰项样本,这可以帮助它学习训练的音频数据的数学表示形式。
有了这些表示形式,wav2vec可以通过剪辑和比较,从干扰物种分辨出准确的语音声音。
Wav2vec每秒执行数百次这样的操作,从而成为自身的转录器(transcriber),并且自动生成不正确版本的语音示例以测试系统并评估性能,从而无需手动注释训练数据。
三、少150倍训练数据,错误率降低22%
Facebook AI团队使用LibriSpeech(公共领域有声读物的一个语料库)数据集上不到1,000个小时的未标记语音示例对wav2vec进行了培训。然后再使用WSH1(《华尔街日报》大声朗读的集合)语料库中大约81小时带标签语音示例进行培训。
训练结果令人印象深刻。在Deep Speech 2上,Facebook基于wav2vec的模型实现了2.43%的单词错误率,而普通系统使用12,000小时(超过150倍)的转录数据训练后的单词错误率为3.1%,相比之下,wav2vec的错误率降低了22%。wav2vec训练的模型与缺少预训练的模型相比,单词错误率还可以提升30%。
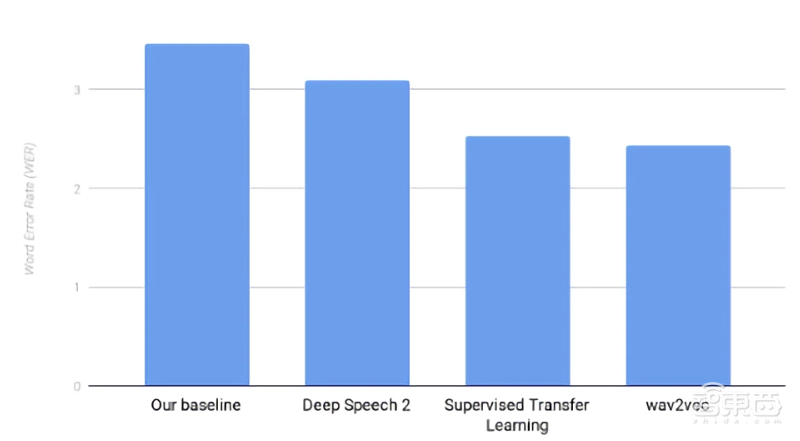
▲wav2vec与其他模型的单词错误率对比
根据Auli及其小组的研究表明,自监督技术可以将ASR功能扩展到转录语音资源有限语言中去。他们写道:“自监督不仅在语音领域,几乎在每个领域都在加速发展。以无标签培训数据为规则愈加成为主流。
结语:“自监督”算法为ASR注入新活力
全球有许多语言并没有英语、中文等主流语言那样庞大的语料库,因此自动语音识别技术的发展就会存在困境,而wav2vec自监督算法让该领域看到了新的突破方向。
Facebook在AI语音技术上的发力,与其本身的业务有着密切关系。未来,我们期待ASR领域能有更多新的突破。
原文来自:Venturebeat
