








智东西(公众号:zhidxcom)
文 | 季瑜生
打榜、噱头、争议、烧钱
创新、天才、明星、思辨
……
评价AI企业,有人说他们是烧钱的机器、科技行业的共享单车;
也有人说他们是中国科技之光,汇聚了最多的学术人才,屠榜了最多的行业记录,将一个最初只停留在科幻电影中的事物,在短短几年的时间内就这样鲜活且不容拒绝的拉到了每个人的生活之中。
但无论如何评价,我们都不得不承认,如果没有AI,中国如今的科技产业可能会黯淡一半的星光。
而如果少了旷视、商汤、依图、云从这些企业的存在,中国的AI行业则又要起码暗淡一半的星光。
无论如何,能够在这样一个汇集了各种顶尖人才且正处于加速发展的行业之中一直漂亮的生存下来,无论是估值,还是打榜或许都不是其真正的原因。
技术创新与产品落地是检验价值的两个最重要的维度,而支撑起一个真正AI企业的落地与创新的,一定离不开一个高效且灵活的人工智能算法平台的存在。
以旷视为例,在业务层面基于其Brain++人工智能算法平台,旷视相继开发出了AIoT数字化软件平台,洞鉴——智能城市管理操作系统,河图——机器人网络操作系统等一系列直接应用于商业化落地的产品与服务;
在技术层面,基于Brain++,旷视连续多年屠榜各大图像识别比赛的榜首位置,并创新性的提出了包括MegDet、ShuffleNet、AutoML (Single Path One-Shot NAS)等在内的最新科研成果。
甚至,旷视官方曾经这样总结其Brain++的重要意义:正是“Brain++让规模化算法训练成为可能。”
那么以Brain++为例,旷视是如何构建起的这样一个同时支撑研发与落地双重需求的AI算法平台?
支撑起Brain++的,又是怎样一些黑科技的身影?
与此同时,面向未来,Brain++又将产生怎样的进化?
最重要的是,在遍地开源算法的如今,透过Brain++,我们能看到的AI企业的存在意义又在何处?
争议与光环一同加身,技术与商业化齐头并进,读懂他们从来不是一件容易的事情。而以Brain++为代表的AI自研框架,则正是其行进过程中的一个绝佳观察样本。
一、历时五年,旷视的Brain++野心与成长
一边仰望着技术的星空,一边脚踏着商业化的实地。这对于一个真正的AI企业来说,或许正是一个最浪漫的姿态。
而创造出这个浪漫姿态的背后,则需要一个能够不断进化、不断开花结果的算法平台来进行科研与落地的支撑。
提起Brain++人工智能算法平台,旷视首席科学家、旷视研究院院长孙剑博士这样描述其对于企业的重要性:正是“Brain++让规模化算法训练成为可能。”与此同时,通过Brain++,旷视“能够针对不同垂直领域的碎片化需求定制出丰富且不断增长的算法组合,包括很多长尾需求。此外,我们能以更少的人力和更短的时间开发出各种新算法。”
对于Brain++,孙剑博士能够给出这样高的评价,绝对不是个偶然,毕竟早在刚成立不久的2014年前后,旷视就已经开始为自身的AI研发搭建起这样一个发动机——Brain++。
而环顾那时的AI行业,一切似乎还都处于刚起步的阶段。
那一年,训练一个AI模型,至少需要一两个月,开发者甚至要通过手敲C++来完成计算过程。
那一年,全行业的深度学习框架还只有一个早在2007年推出的近乎文物级别的Theano与一个2013年推出的Caffe 。
……
尽管放在如今看来,作为一个初代的深度学习框架,Caffe的出现无论对于业界还是对于学界都可谓是意义深远。不过,作为初代深度学习架构,Caffe的设计本身依旧有着一定的局限性。
比如在使用时,Caffe网络结构都是以配置文件形式定义,缺乏以计算图为代表的相对自由灵活、可视化的算法表达。而截止2015年,以152 层的 ResNet为代表的一些大型神经网络已经出现,而恰恰针对这种对于大型神经网络,Caffe使用起来会变得十分繁琐。
因此,针对Caffe架构中的一些不足,旷视Brain++在一开始就确立了要以计算图的方式来进行框架搭建的思路。
放眼行业,这种基于计算图的方式,也正是目前以TensorFlow、PyTorch等为代表的第二代AI框架的一大特色所在。不过不同的是,Brain++的出现比TensorFlow早了半年,对于旷视内部的视觉图像研发人员而言,也更具有针对性优势与亲切感。
此外,日后的诸多采访中,我们也可以隐隐窥见旷视对于构建一个完全自主可用的AI架构的野心与付出。
在2017年的一次C轮融资采访中,旷视的创始人印奇谈起自研的AI算法平台时便讲到,行业“需要一个更好的、类似TensorFlow的引擎。一个All in One的系统,是我们花了最大精力在做的事情。”
发展到如今,旷视研究院院长孙剑向我们表示,Brain++已经逐步迭代升级到了8.0版本,无论在稳定性还是技术的先进性都具备了非常大的优势。
与此同时,在旷视内部,上千名研发人员全部都在使用内部的Brain++进行技术研发。而基于Brain++的大树之上,旷视还相继生长出了MegDet、AutoML等技术的果实。
借此,一个庞大的算法帝国,正脉络清晰的向我们展现出了它生生不息的动力来源与未来的无限可能。
二、深度解读,Brain++背后的黑科技与生态构建
拆解Brain++的组成,其中总共包含了人工智能数据平台、人工智能基础(训练)框架,以及人工智能计算平台三大部分的内容,分别对应着AI发展中的三大要素:数据、算法以及算力。
据孙剑表示,在数据平台中,旷视通过让算法与数据一同工作,借助算法来辅助数据清洗和标注,可以大大提升数据标注的速率与成本。
其具体方式是先以少量的标注训练出一个初级的算法,然后以这个算法来标注数据,接着对于算法标注过程中遇到的不确定的数据,人工的对其中最不确定的数据进行标注,算法则再一次对剩余数据进行自动标注,进而以最小的时间与成本代价获得了更高效更快速的标注结果。
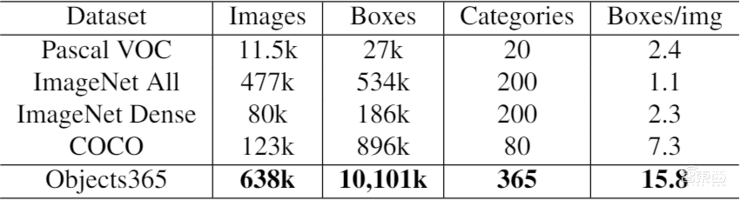
此外,在数据方面,旷视还在今年年初联合北京智源人工智能研究院发布了一个包含70万张图片的数据集Objects365,其中包含了365中常见的物体以及超过一千万个标注框,是目前世界上最大的物体检测数据集,相较此前最大的COCO数据集,是其十倍之多。
Brain++中的人工智能基础框架则可以简单地认为是旷视完全自研的TensorFlow或者PyTorch。
作为一个典型的第二代AI开发框架,Brain++相较“前辈”Caffe更灵活,可定义的程度也更高。另外,旷视还结合了其自主研发的旷视AutoML技术可以为神经网络针对不同平台进行自动的优化,进一步提升了算法的灵活性。
使用者每个人都能像登录虚拟机一样登录计算平台。而且不必调试好之后再提交任务,只要自动申请需要的CPU/GPU数量,而且还可以在训练的过程中随时停下来进行调试,找出错误的地方后然后继续训练。
另外,多任务与多用户调度能力也是Brain++的一个特色。旷视针对算力分配利用透明计算的原理,开发了一层软件进行计算资源的管理与调度优化,可以在用户空闲时临时收回资源分配,进而支持数百研究人员同时在上万块GPU上进行上从数百到数千个训练任务。
两种方式互相结合,可以在保证训练效率的情况下让算力能够被最高限度的利用。
那么这样一个由三大部分构成的Brain++,相比Caffe、TensorFlow有什么不同呢?
首先是完全自主研发。孙剑表示,Brain++的意义在于更加适配旷视自身的研发以及开发需求,否则针对TensorFlow等框架去“改现有的东西,其实是很难改或低效的。当代码已经很庞大时,你很难快速的去做这些调整。而我们自己的东西,你可以很容易的去做修改,去验证这些东西。”
其次是针对计算机视觉任务的定制化优化:在Brain++中,旷视针对计算机视觉做了很多的优化。
以2018年孙剑发布的CVPR文章为例,这篇文章从mini-batch角度为加速深度神经网络训练提供了一种叫做“MegDet”的新型检测。这个技术第一次实现了在训练物体检测时可以用一个多达256多个样本的“大mini-batch”的检测器,用128张GPU卡训练任务,进而将训练时间从33小时减少到4小时。
但除了这些黑科技之外,事实上,搭建起这样一个庞大的汇集了算法、算力、数据、框架于一体的AI平台,其难度不仅来自技术与资金的投入,更大的难度是在于如何从企业创立的伊始便搭建起这样一个开放,但却无法预估回报的长期生态。
有位业内专家向我们做了这样一个比喻:
一个企业想要做好AI平台,其难度与重要意义可以类比如今的华为想要搭建一个鸿蒙操作系统+生态。
而要拆解其难度,摆在面前的第一关就是怎么将其搭建起来,这本就是一个非常庞大的工程。
其次,还有时间的问题,起步早不仅意味着有更多的时间从底层起一步步构筑完善,同时也意味着不必面对一堆已经累计多年的庞大代码库,就像已经布置好了软装,才发现家里的钢筋水泥结构没搭好。
最重要的,则是生态的构建,如何汇聚起优质的开发者,如何保证框架的高效可用,即使是企业内部使用,这依旧是无法绕开的难题。
三、Brain++之上,旷视的荣耀与未来
基于Brain++,旷视究竟做了什么?
孙剑表示目前旷视的所有研究都是基于Brain++做的。最直观的表现就是,2017、2018连续两年,旷视都基于Brain++在国际上最权威的图像识别大赛中夺冠。
算法层面,以Brain++为基础,旷视还开发出了可部署在云端、边缘侧以及移动端的深度神经网络。
在云端,2015 年,孙剑在微软工作时领导的团队首次提出深度残差网络ResNet,使得训练数百甚至数千层的网络,机器视觉超越人眼成为可能,并大幅提升了云端算法的性能与天花板。
边缘侧,2016年,旷视开发出了适用于芯片的轻量级深度神经网络模型DorefaNet,通过低精度方法,使得卷积计算在芯片上通过简单的位运算就能完成计算。
而在移动端计算平台,2017年,旷视研发了轻量化卷积神经网络ShuffleNet。通过逐点群卷积和通道混洗等方式,ShuffleNet在确定计算复杂度预算的条件下,允许使用更多的特征映射通道,故而实现了在轻量化网络上编码更多信息的设计,可以专门应用于计算力受限的移动设备。
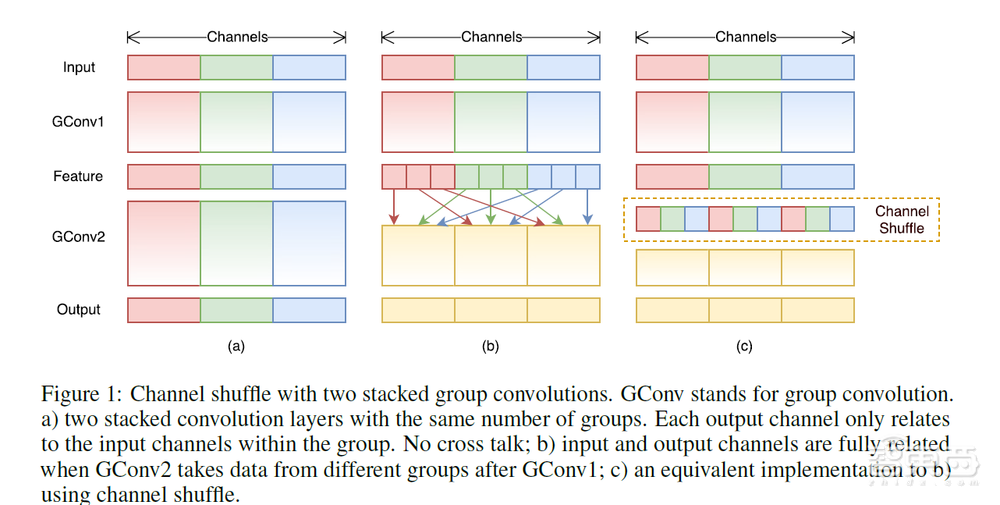
▲ShuffleNet基本原理图
从 2017 年至今,ShuffleNet已经发展了ShuffleNet V1、ShuffleNet V2、ShuffleNet V2+这 3 个版本:在基于ARM的移动设备上,ShuffleNet在保证相似精度的情况下实现比经典的AlexNet快二十倍的速度。并在GitHub之上获得了741星的成绩。
以 Google AI 团队开发的网络优化结构 MobileNet 为对比(根据Google AI团队的公开技术报告),ShuffleNet V2 在实际运行速度上经常比 MobileNet V2 快 30 – 50%。
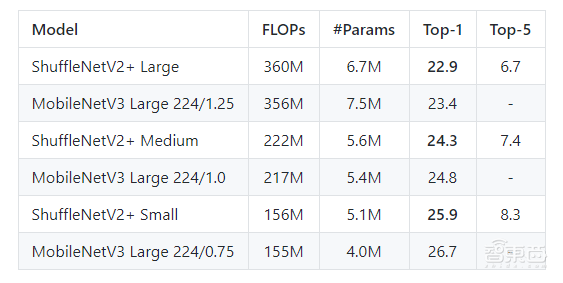
▲图源:GitHub:https://github.com/megvii-model/ShuffleNet-Series
另外,孙剑还重点向我们介绍了旷视的AutoML(机器自动学习)技术 — “Single Path One-Shot NAS”。
长期以来,业内都会有一个调侃叫做所谓人工智能,有多少智能,背后就有多少人工。但是通过AutoML技术,则可以让机器自动进行端到端的优化,从而大幅减少人力的成本投入。

此前,在AutoML领域的研究,一直都被国外谷歌AutoML Vision、微软Microsoft Custom Vision、亚马逊Amazon SageMaker等企业以及平台所“垄断”,近两年国内百度的EasyDL也在进行相关的探索。而旷视则是当前创业企业之中在该领域的领头羊。
具体落实到应用中来说,旷视曾经在业界推出一个名叫超画质的项目。
通过以深度学习技术替代原来的ISP流程,旷视可以对原始图像进行检测、分析、降噪和融合等处理,能够解决用户在夜晚和低光照环境下拍摄照片时产生的画面亮度偏暗、噪点过多、动态范围不佳等画质问题,并通过人工智能学习高画质数码相机的成像特性,还原景物原有的细节纹理,使画面品质得到整体提升。
但是新一代算法的一大问题则在于计算量非常大,使用时就需要在计算量与效果之间进行权衡。
孙剑表示,旷视通过AutoML可以针对不同平台对神经网络进行自动的优化,进而保留下最高效的算子,同时在不影响整体效果的前提下,将一些低效的算子减少或者舍弃,从而使得算法可以在相应的平台中发挥最高的效用。

▲右图为经过超画质处理后的结果
不过孙剑也表示,对于目前的Brain++他可以打分80,因为放眼未来,Brain++还有很多需要做的事情。
比如,旷视从去年起就在规划一种用于深度学习训练的专属语言,从而协调训练所需要的灵活性以及推理所需的性能的要求。这是当前深度学习、深度框架领域带头企业都在做一些前沿性的探索,不过进度上来看,目前大家都还处于比较早期的阶段。
结语:读懂Brain++,不仅是AI框架,更是时代节点下中国产业的抗衡底气
在对话孙剑之前,我曾经内心预演过无数种AI企业可能的死亡姿态:比拼AI技术,或许阿里云、腾讯云、百度都可以通过资金、规模优势将其碾压;但是比拼落地,掌握了开源技术的传统行业玩家似乎又占据了最好的市场与经验优势。
但是一个AI企业存在的意义在于哪里?或许除了将技术落地这样脚踏实地的事情之外,我们还需要多看一看星空。
以一个坚实的AI算法平台为基础,可以不断探索一些前路充满坎坷的未知算法与技术;布局一些前人未涉及的语言与应用。与此同时,它也在不断的进化,一路不停的反哺着最切合用户需求的应用。
或许,进一步将时间拉长到五十年、一百年,我们现在所仰望的、所质疑的、所遗忘的所有明星与企业都终将面目全非,但是总有一些东西会留下了,或许是一个算法、一个语言又或许是一个灵活的框架、一个开放的生态。
更进一步来说,曾经在芯片在操作系统乃至在浏览器领域,我们都长期受制于人,但是在新兴的AI领域我们却做到了能够与对手一同起跑,并在多个节点之上超越对手,所凭借的不正是这样一个又一个如操作系统般默默存在但是却影响深远的AI平台与框架的存在吗?
以Brain++为代表,它们作为中国AI企业极少数的自主可控的算法框架,不仅影响着企业自身的科研与商业化步伐,同时更是直接决定着整个国家的产业在这个新时代节点之中与海外抗衡的底气。
至于商业化的未来路在何方?打榜、噱头、争议、烧钱;创新、天才、明星、思辨?
答案在每个身处这场变革之中与每一个围观者的心中。
