








7月12日,智东西公开课推出的超级公开课NVIDIA专场进行完第十讲,由NVIDIA高级系统架构师张景贵主讲,主题为《在你的桌面端通过NVIDIA云端GPU开展深度学习》。张景贵老师详细介绍了当前Deep Learning软件部署的挑战与NGC解决方案,并通过实例深入讲解了如何利用NGC提供的容器镜像快速开展深度学习。本文为张景贵老师的主讲实录,共计9158字,预计10分钟读完。
主讲环节
张景贵:大家好,我是NVIDIA高级系统架构师张景贵。感谢智东西公开课提供这个分享交流的机会。今天我要介绍的主题是《Deep Learning On Your Desktop》,即在桌面端进行深度学习。这也是一门基础课程,主要给大家提供更便利的方式去使用NVIDIA的GPU进行深度学习。希望这堂课对大家有所帮助。
本次分享主要包括以下四个部分:
-当前Deep Learning软件部署的挑战与NGC解决方案;
-NGC的使用场景和软件堆栈情况;
-如何注册和使用NGC;
-NGC实战训练的演示。
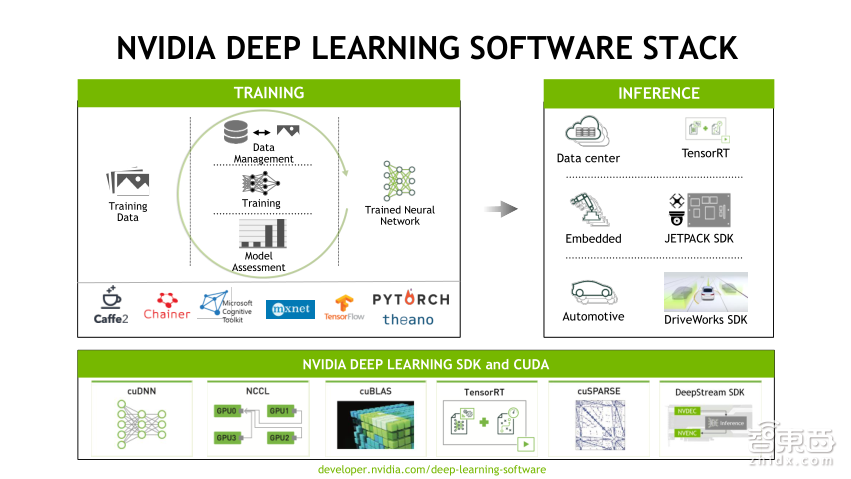
首先,给大家介绍下深度学习的软件堆栈。深度学习的软件非常多,目前大家接触的是最上层的深度学习框架,比如Caffe、TensorFlow等各种各样主流的深度学习框架。在深度学习框架下方会有各种各样的软件,为了更好地使用GPU,这种深度学习框架都去调用各种NVIDIA的GPU库,包括深度学习神经网络库cuDNN、GPU通讯函数库NCCL(是加速GPU和GPU之间通讯的库)、还有一些GPU基础线性代数库cuBLAS以及GPU推理加速引擎TensorRT,这是底层的一些主流深度学习框架调用的NVIDIA库。再往下层,大家还会用到CUDA,这是GPU编程库,还有GPU Driver以及OS。这里的软件非常复杂,软件版本种类繁多,配置起来也有很大的工作量。

这些复杂软件环境带来哪些挑战呢?具体来说,主要包含下面三个部分:
第一,对于GPU加速的AI、高性能计算来说,由于软件环境特别复杂,构建环境维护和测试用的时间比较多,对于一个新手来说,如果打算学习深度学习,那么安装就成为第一大障碍,这可能会导致大家没有兴趣进行下一步;
第二,对于熟练的工作人员来说,还是会用大量的时间进行安装以及测试调优。实际上,我们生产的目的是希望大家能够第一时间拿到一个优化的环境来使用。这就是复杂软件带来的问题,也是我们需要解决的问题;
第三,深度学习会用大量的开源软件,这些软件的版本变化非常快,比如2017年3月发布的TensorFlow1.0,到目前为止,这一年多的时间已经发布到了1.9,可以看出软件的更新迭代速度非常快,基本上一个月时间会有一个版本的更新。这些软件依赖于一些底层软件,其中关系特别复杂,每一次软件更新带来的工作量都是非常大的,比如TensorFlow更新,会考虑到CUDA的版本、cuDNN版本以及Driver版本,这些依赖关系非常复杂,需要有很丰富的经验才能做好优化以及配置工作。
对于这些问题,NVIDIA提供的解决方案是,提供基于NVIDIA的Docker容器,对于Docker,相信大家都比较熟悉,容器就是对软件依赖库进行了封装,可以做到软件环境的隔离并快速地使用软件,大家可以通过容器的方式快速部署自己想要的应用。NVIDIA容器是GPU加速的容器,包括AI Deep Learning容器和HPC容器等,将GPU加速的相关软件进行了打包封装,直接提供给用户使用。

这里提到了NGC的概念,NGC全称是NVIDIA GPU CLOUD。这里的Cloud与传统的Cloud是两个概念,传统的Cloud一般指的是一些工作云平台。而这里的Cloud提供的是针对深度学习和科学计算优化的GPU加速云平台,实际上,它本质上提供的是一个容器仓库,首先在NGC的页面上提供注册,同时也会提供一个下载NVIDIA优化的容器库地址供大家使用这个平台。
这个平台包括三十多款软件,涉及到AI、HPC、可视化领域以及一些合作伙伴的容器镜像等。通过这些容器镜像,大家部署应用时在GPU上花费的时间就会大大缩短。另外,NGC连接公网的位置都是可以访问的,因此大家不用担心受限的问题,所以在家庭或者公司中,只要没有做一些防火墙的隔离都是可以访问的。同时,这个容器镜像目前是支持Pascal和Volta架构的GPU,也包括泰坦、GeForce以及Tesla等各种GPU。NGC容器镜像也可以运行在通过我们认证的服务器上,比如OEM合作伙伴的服务器、惠普、戴尔、IBM和国内的华为、浪潮、曙光都是可以运行NGC容器的。另外,也支持在NVIDIA认证的云服务上提供NGC容器服务。

NGC提供的容器镜像分为五类,支持35款软件镜像。其中有12深度学习框架或工具,里面包含了所有主流的深度学习框架、Inference中TensorRT的容器封装以及DIGITS。DIGITS是Deep Learning学习和生产的可视化平台,后面也会有DIGITS的演示介绍。
第二类是高性能计算。由于高性能计算的应用非常多,2017年的时候支持5款软件镜像,现在已经有13款HPC容器镜像以及HPC的可视化镜像。另外,目前新增的有Kubernetes容器镜像,Kubernetes是用于容器的集中管理调度,有一个开源版本,同时,NVIDIA维护了一个自己的版本Kubernetes on NVIDIA GPUS,我们也提供这个版本容器镜像的下载。另外,还有一些Partners容器镜像,包括百度的paddlepaddle以及mapd这些GPU数据库的容器镜像。

通过这些容器镜像,用户可以非常迅速地使用在HPC互联网场景或者一些工业应用场景中,由于很多工业领域用户的时间紧迫性比较高,因此可以直接使用容器镜像避免了自己的调试,目前应用比较多的领域有自动驾驶、医疗健康、医疗金融以及金融服务等,避免了每一个用户都要自己DIY软件的过程,节省了大量的时间。同时,NGC容器始终保持每个月的更新进度,目前是两到四周的版本更新速度,大家可以在网站上关注它的更新,条件允许的话建议使用最新的版本。
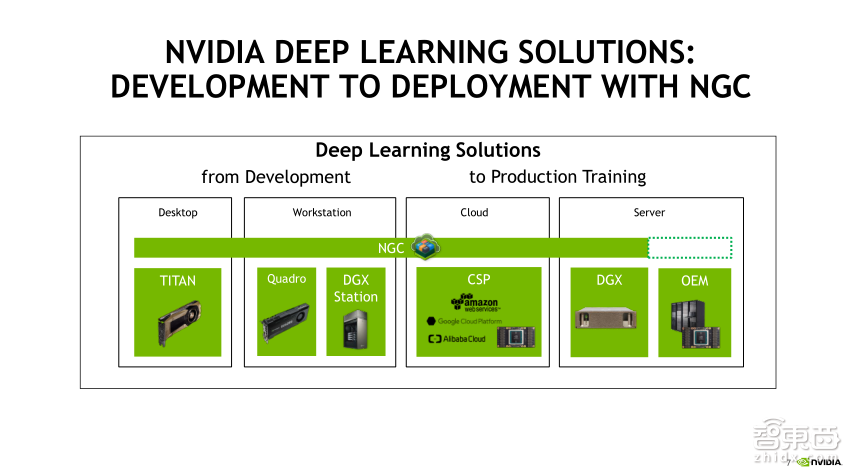
下面重点介绍一下NGC适用于哪些平台。刚才也大概的提到过,对于GPU来说,只要是Pascal架构之后的GPU都支持,还有NGC容器封装的CUDA版本以及一些软件版本。具体到产品上,我们的用户最先接触的一般是GeForce和TITAN类的,在个人桌面端支持TITAN,在WorkStation(工作站)端支持Quadro和DGX Station(一体机)。这两部分主要是用户个人端的,主要是用于开发。
如果是大规模商用和用于生产的方向,一般都放在数据中心或者云端。数据中心一般都放置在OEM厂商的服务器,其中服务器放的是Tesla的数据中心卡,Tesla支持在数据中心7×24小时运行,因此,在数据中心都是用Tesla卡。在公有云平台上,目前NGC支持的认证云平台有亚马逊的AWS、谷歌云平台以及阿里巴巴云平台,在他们的云平台上都授权了NGC容器的使用。

我们详细看一下支持的GPU卡。刚才提到桌面或者工作站,一个是TITAN,一个是Quadro。TITAN包括TITAN V、TITAN Xp以及TITAN X;Quadro包括Quadro GV100、Quadro GP100以及Quadro P6000。这些都是NVIDIA认证的GPU卡,都可以放心地使用NGC。
这也给用户提供了低成本快速学习深度学习的方法以及开发调测的环境,大家可以通过一种低成本的方式进行深度学习网络的调优调测。

NGC还可以使用DGX服务器。DGX是NVIDIA自己的GPU服务器。实际上,DGX不只是一个服务器,也是软硬件一体机。DGX预装了ubuntu操作系统,同时预置了一些深度学习相关的软件,因此它是一个深度学习一体机,另外还提供一些定制化的服务。DGX包括8卡DGX-1、16卡DGX-2以及4卡DGX Station多种产品类型,这些产品都可以直接使用NGC容器。

下面介绍下如何在公有云平台上使用NGC。介绍两个目前国内使用比较多的公有云平台,一个是亚马逊的公有云平台,另一个是阿里巴巴的公有云平台。
在亚马逊公有云平台上,首先选择亚马逊的GPU实例,如P3,具体大家可以根据自己的实际需求选择实例,关键的一步操作要选择它的AMI(操作系统镜像),大家可以参照上图搜索NVIDIA Volta,这里提供了一NVIDIA Volta Deep Learning AMI,使用这个AMI直接启动之后默认可以下载NVIDIA Docker容器。同时,这个AMI是经过了大量测试认证的,比较稳定,大家如果要使用公有云运行NGC的话,需要使用这个操作系统镜像。
同样,在阿里云的平台上,在装操作系统镜像时,可以搜索NVIDIA GPU Cloud,这里会提供一个相对应的操作系统镜像,通过这个操作系统镜像就可以使用NVIDIA的容积镜像了。
这两个操作的详细步骤,大家可以参考图片上的网址,这是NGC的主页,上面有在个人端和云端使用NGC的详细介绍。
接下来介绍在实际使用时应该如何用NGC以及如何注册使用下载容器。

大家可以通过“nvidia.com/cloud”来查看NGC的整体介绍,然后通过“nvidia.com/ngcsignup”进行NGC的注册。
这是NGC登录页面,已经注册的用户,可以直接通过邮箱登录,登录后就可以进入NGC的主界面。如果是初次使用NGC的用户,下面有一个创建帐户的选项,大家可以选择创建账户。
创建账户的界面也比较简单,大家只要输入姓名、公司、自己的角色、用途、邮箱、所在的国家以及同意NVIDIA的协议就可以注册了。大家可以关注下这个协议的内容,重点提及的是,由于NGC容器是免费提供给大家的,但我们对它的分发作了一定的限制,大家在下载了NGC容器后,自己使用是没有问题的,但是如果你做了封装进行二次分发或者直接再做分发,将会受到限制,这也是我们对产权的一种保护方式。
在注册的时候,个人邮箱一定要真实,点击注册时,注册的邮箱就会收到一封校验邮件,点击校验之后就可以进行首次登录,登录后就可以看到主页面了。
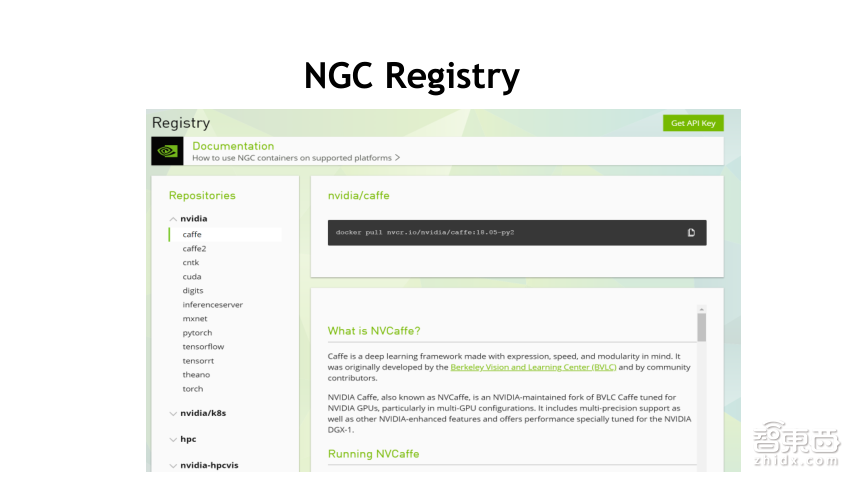
进入主界面后,大家就可以看到容器仓库的目录。左边是容器仓库,在这里可以看到刚才提到的几类容器,包括一些深度学习以及HPC的。当我们单选某一个容器镜像时,比如Caffe,右侧就会有详细使用介绍,首先,界面上黑色标注部分是下载命令,包含了docker pull下载;紧接着是容器镜像实际存放的地址nvcr.io,再后边是具体的子地址,Caffe是镜像的名字,18.05是镜像的版本,py2是python版本名代号。这个py-2是Python2版本,大多数容器镜像有py2和py3两个版本,分别对应Python2和Python3版本。
截图上的Caffe可以看到是NVCaffe,它不是开源社区原版的Caffe,开源社区原本由伯克利大学主导开发的伯克利版本,NVCaffe是NVIDAI在它的开源基础上又维护了一个版本,在NVIDAI GPU的环境上,我们建议使用的是NVCaffe。

在下载使用NGC前,有一步操作是鉴权,在Linux使用时会有一个鉴权操作,鉴权操作是通过API Key的方式,在上一页PPT界面上有一个获取API Key的方式,获取后到达上图展示的界面上,在这个界面上可以根据详细的提示生成API Key。在Linux系统上,通过docker login nvcr.io进行登陆。
在login时,首先提示的是用户名,对于用户名,所有的用户名是一致的,各个用户都是默认的用户名;Password是生成的API Key,在API Key的右下边有一个复制的按钮,复制API Key之后粘贴上即可登录成功。
登录成功后我们就可以下载NGC上的各个容器了。由于我们面向的是初次使用的用户,因此也提供了一些实际的事例,来告诉大家如何使用NGC容器快速地进行训练或者推理。

首先,我们看一下训练的情况。上图展示用的是大家最常用的TensorFlow,目前TensorFlow最新的版本是18.6,示例图为是18.5。大家可以在NGC网站上看到每一个版本的下载链接,不同版本的标识为后缀不同,可以根据自己的需求选择对应的版本。
其中18.5是容器镜像的版本,它里面的版本配套关系是怎么样的呢?在下载的页面上找到“ XXX Release Notes Documentation website”链接,通过文档可以看到这个容器镜像的详细介绍,包括使用的CUDA版本、NCCL版本、cuDNN版本以及TensorFlow或者Caffe的版本。
容器镜像的下载的速度和大家的网络环境有很大的关系,如果网络环境不是很好或者该容器镜像是在国外,都有可能导致下载偏慢,每个容器镜像的大小大约在2-4G之间,大家可以预留一定的时间。
下载了TensorFlow容器镜像后,通过Docker命令可以进入容器镜像的内部。上图的Training就是进入镜像内部进行操作的。对于Docker操作命令,如果用的是Docker2.0,则可以直接用docker命令,如果是NVIDIA Docker1.0,则需要用nvidia-docker的命令来进入GPU环境。它们之间的主要区别在于,如果是Docker1.0的情况下,不加入nvidia-docker命令,Docker是无法将库驱动等信息加载到容器镜像中,则GPU也是没法使用的,因此在这里,大家可以留意一下GPU的环境。
通过nvidia-docker run进入镜像,后边的参数跟docker的参数是相同的。name后面是给镜像起的名字,”e878e4ef1882”字符串是刚才下载容器镜像的代码,这个代码唯一指向这个容器镜像。启动这个容器镜像进入它的bash环境之后,可以看到这里进入了一个nvidia-examples的文件夹,这个文件夹内有大量的NVIDIA Examples;如果是做语音的,可以选择与语音相关的深度学习脚本;如果做图像的,可以选择CNN的脚本。
大家可以根据这些示例脚本来做一些自己的Demo进行初步学习,在Demo跑通之后,可以对这个脚本做进一步的优化,然后定制自己的Training。因此NVIDIA的容器镜像,不仅仅是提供了一个所有软件的封装,还提供了一些事例帮助大家快速地学习Training。
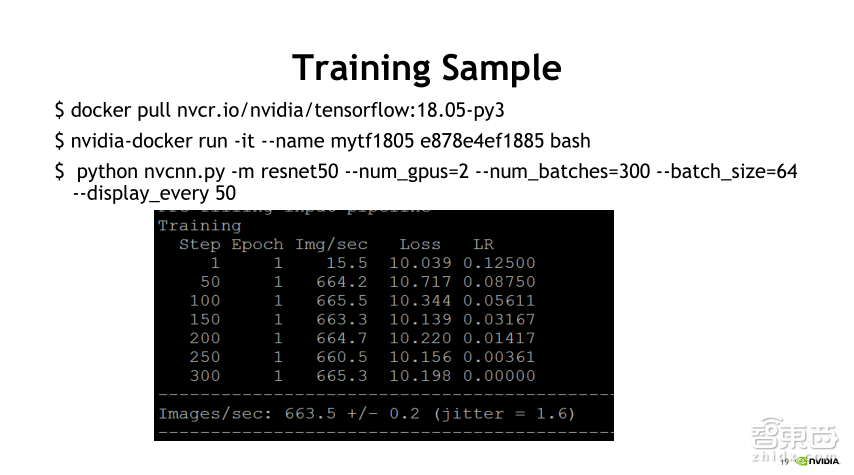
接下来看一个具体的Training实例。刚才有提到CNN实例,上图中有个nvcnn.py,使用这个python脚本可以做一个简单的Training练习。给大家普及一下,选择python nvcnn.py,然后指定网络类型(支持MXNet、AlexNet),大家可以根据自己的实际情况选择自己需要使用的网络类型和GPU个数。上图的例子中选择了两块GPU,300个batch以及64 batch_size进行训练,对于训练,大家会关注两块,第一是数据源,第二是Label。关于数据源,由于TensorFlow本身是支持模拟数据的,因此它用了模拟数据来进行仿真,这个测试结果可以看到,在两个GPU上的模拟情况,每秒钟处理的图片数是663.5张图片。
另外,这里的精度用的是FP32精度。通过FP32的精度可以达到665张图片每秒的Training速度。接下来引申一个知识点,叫做混合精度。大家都知道,Volta在AI里面特别加入了TensorCore,TensorCore支持张量计算并且是专门用于AI加速的加速单元。如果上图中使用TensorCore,这时就需要用混合精度来计算,而nvcnn.py也支持通过混合精度来进行训练,至于具体加哪些参数,大家可以在NGC网站上搜索相对应的混合精度训练资源,官网上也会有相对应的演示,包括我们当前使用假数据和大家平时用的真数据,大家可以根据演示的情况来选择实际要用的脚本和参数。

接下来是Inference实例,这一堂课的重点不在于比较各个Inference的区别,如果用GPU,我们建议使用TensorRT推理加速引擎。TensorRT是NVIDIA的推理引擎加速库,它的作用比其他的默认Inference性能要高,由于它的加速性能比较明显,因此在TensorFlow1.7版本之后,就默认集成了TensorRT进行Inference。
首先下载TensorRT的容器镜像,这个命令跟前面是一样。另外,使用这个容器镜像的命令是NV_GPU=0,在host上,如果有多个GPU,而我们不想让Docker镜像使用,只想让它使用一个或者两个甚至指定的某一个GPU,可以在前面加入参数NV_GPU=0进行使用0个GPU,这样容器镜像进入系统后只会看到0个GPU。上图使用”NV_GPU=0,nvidia-docker run –rm -p 8000:8000”,表示通过在host的8000端口映射到容器内部的8000端口的方式来启动镜像。
启动容器镜像之后,因为容器本身默认是没有IP地址的,它是通过端口映射的方式进行访问的。大家访问的时候使用主系统的IP加端口就可以访问容器镜像的服务了,这样避免了过多的配置工作,同时也减轻了Docker的负载。
另外,由于在很多公司的网络环境中,都有设置防火墙,可能8000端口是被封的,这时端口的映射就可以用到了。TensorRT中用的端口是8000,如果公司的网络环境开放了6666的端口,就可以在host前面用6666:8000,在访问TensorRT的时候使用主系统的IP加端口就可以映射到TensorRT里边的8000端口。
这个容器镜像中有一个mnist实例,在mnist启动后,后台实际调用很多的参数,其中tensorrt_server是可执行文件,通过server去指定是caffe类型、指定用float32的方式来进行Inference、指定INPUT数据、网络的类型、权重文件、labels文件等相关输入,就可以使用TensorRT来进行Inference解析,这些都是后台操作的,我们执行的时候只需要执行caffe_mnist命令,后端就会调用具体的参数,也是通过在后台运行的方式,执行完成之后,在浏览器上输入主系统的IP加端口就可以进入TensorRT主界面的mnist图片识别服务,首先需要选择图片,mnist是手写0到9的图片识别任务,这是最简单的Inference任务,可以先选择一张图片,让它做Inference,观察这个图片的识别情况;可以自己在画图板上画一张图片让机器识别,观察它的准确率。如果刚开始使用的时候,发现你画的数字机器识别率非常差,主要原因是由于它本身所有的元素库是28×28的灰色模式图片,当这个图片的尺寸太大太小或者是做成了彩色,就会导致它的识别错误率非常高。
如果想要详细地使用TensorRT,需要进入TensorRT的Docker容器中,里面有大量的example,大家可以根据example来做TensorRT的分布,里面也有大量详细的文档,都可以参考。
对于很多初学者来说,第一个问题就是对操作全流程不是很了解,怎么做这个全流程的训练推理,这一步一步操作是怎么出来的,训练后生成了什么数据,在推理的时候用到了哪些结果数据等问题。这里介绍一个比较好的学习平台——DIGIST。
DIGIST是NVIDIA深度习学院的一个教学平台。深度学习学院有大量的课程都是基于DIGIST来进行设计的。大家可以在DIGIST的可视化界面上一步一步地学习,这样更容易理解各个环节相互之间的逻辑关系。
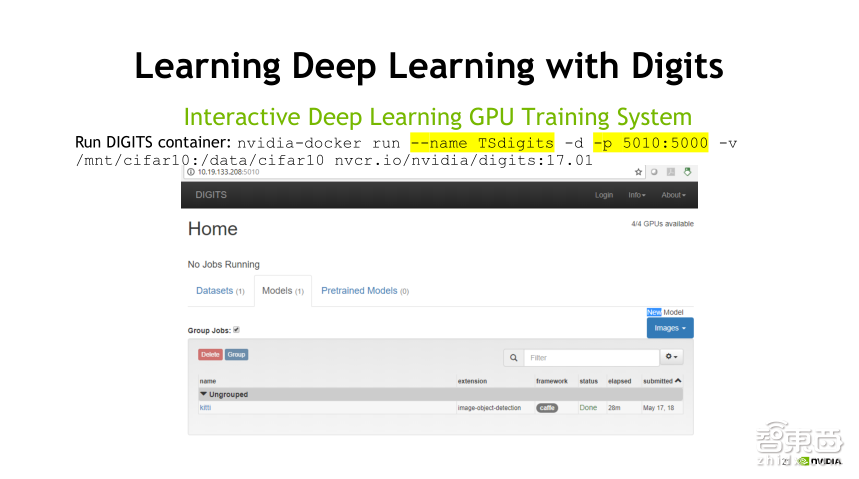
DIGITS容器同样支持NGC下载,首先,是DIGIST的下载,这里的pull我省掉了,即使是省掉,在执行这个命令的时候,发现本地没有这个数据源,它也会自动从网站上去拉取这个镜像。5010是我起的端口,和刚才TensorRT有点类似,在本机上就可以通过IP加端口的方式进行访问DIGIST外部界面,在这个界面的右上方可以看到,一个Docker中识别到了4个GPU。
做深度学习,首先是数据,第二是算法。在这个界面上,首先是数据的准备,对于数据的准备,如果大家拿到的是裸数据以及标签,数据准备会将这些数据转换成training需要的数据格式,生成需要的数据之后,通过点击刚才的数据源选择要使用的网络类型,如果想自定义网络,DIGITS支持对网络进行手工修改。另外,平台还支持训练结果和Inference结果的查看。通过这个平台可以做到全流程使用。
如果要详细地学习这个平台,可以关注一下深度学习学院DLI;如果是想自学,也可以注册账户NGC,自己在本地下载DIGITS来进行深度学习。这种方式对于初学者来说是非常容易上手的。
前面我们讲的是这些软件的基础以及让大家更好地了解这个软件。实际上,对于一些深层次的用户来说,更多的是把这个软件整体地用好。比如刚才说的混合精度怎么用、TensorRT支持多种格式(支持float32、float16、int8),如何才能用好TensorRT以及如何优化自定义网络等问题,这些涉及到开发性的东西,大家可以参照NVIDIA Developer这个网站,在网站上大家可以选择自己感兴趣的子项,里面会有大量的子链接分到各个领域,同时里边也有Deep Learning各种库的使用,包括一些底层的API介绍等。
以上就是我分享的全部内容,希望对大家的工作和学习有所帮助,谢谢大家。
Q&A
问题一
张宗强-小米-工程师
使用NGC的过程中,由于我们不知道image里面安装了什么,导致想制作自定义image的时候不好开发,NGC的docker容器是否会开放dockerfile?
张景贵:刚才在课程上提到了一点,在下载这个容器镜像的界面上,会有一个 “XXX Release Notes Documentation website”.的链接。点击这个链接可以看到详细的介绍,包括了封装的内容以及封装的主要软件的版本等,但是里面不涉及到每个软件的优化都做了什么,而只是把最主要的软件写上去。由于涉及到NGC是我们版权的问题,在NGC授权协议上提到,个人用户可以使用免费使用,但是不能二次分发,因此没有开放dockerfile这种方式。
问题二
王晨亮-超图软件-研发主任
1.个人Linux下的docker能否可以使用NVIDIA优化的深度学习容器?
2.优化前后的深度学习框架有没有一个详细的benchmark数据,比如进行一些目标检测,分割等任务上的对比,在一些效果上的提升有没有比较详细的介绍?
3.部分框架由于时间较早一般用py2实现,因此有些涉及到代码迁移的工作,NGC上有没有比较好的方案帮助快速迁移 ?
4.NGC的收费形式是怎样的,以及aws中国区能否使用,如果现在不能的话什么时候预计可以?我们未来可能和aws中国有ai方面的合作
张景贵:1、可以使用,我们对于操作系统的版本没有明确说明,一般来说,使用主流的版本都没问题。
2、实际上,我们暂时还没有详细的对比数据。这里有一页资料介绍了Caffe版本变化带来的性能变化。
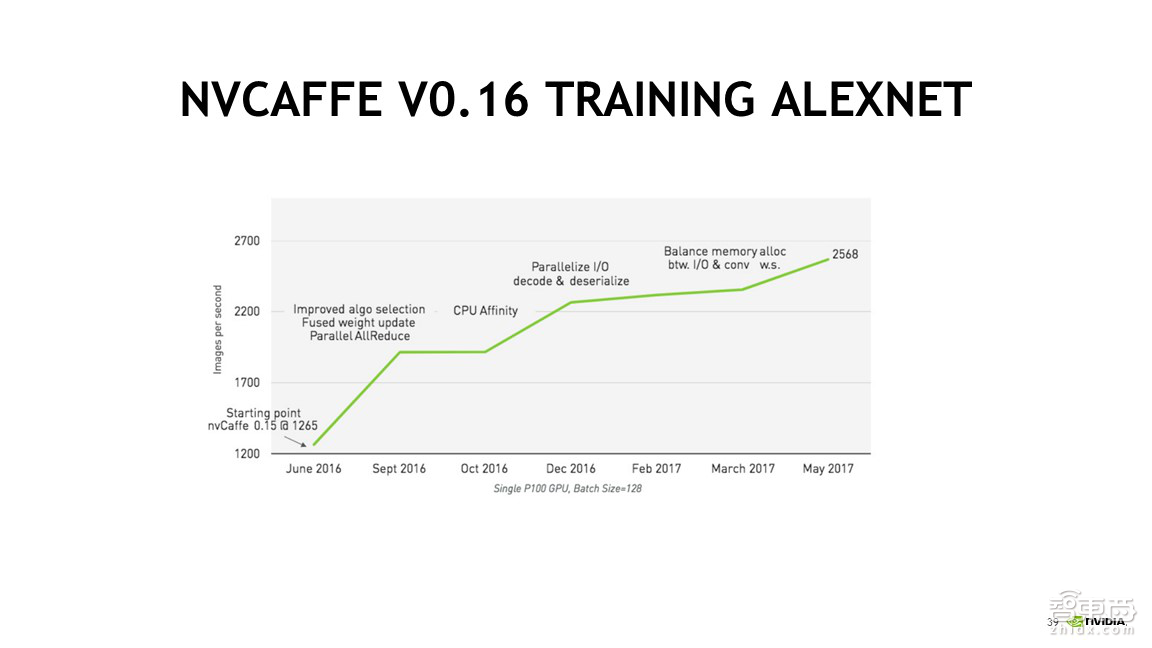
可以看到。原来NVCaffe0.15的时候,Training的速度是1265,到了0.16,经过一年左右时间的优化,0.16性能达到了翻倍。其中,第一个是版本升级和软件版本升级带来了性能的提升;第二,还有很多相关的软件参数调优以及内存访问的均衡性等,这里通过大量的调优工作导致性能达到了翻倍。因此,大家在拿到一个新的容器时,基本主要有两个目的:使用它的新功能和使用它带来的性能提升,这也是使用容器的一个原因。
3、NGC本身不涉及迁移服务,我们更多的是提供两个版本。比如NGC上会提供Python2和Python3这两个版本的容器镜像,如果需要用哪个版本就优选哪个版本。如果确实涉及到迁移业务,NVIDIA也有一些做迁移相关工作的团队,可以跟销售取得联系后去寻求他们的帮助。
4、NGC是免费的,AWS的使用也是没有问题的。
问题三
郭远昊-汇医慧影-工程师
1.如何在客户端和云端传输大规模训练数据,如何保证云端数据的安全性?
2.训练过程异常,程序中断情况下,是否可以在云端重启训练?
3.NGC如何保证用户任务的优先级?
4.云端是否支持docker?
张景贵:1、实际上,这个问题应该由公有云提供商来回答的。我们只能凭一些经验来跟大家分享。对于公有云厂商来说,首先要强调的是保证用户的数据安全,因此这些数据对于云厂商来说也是不可见的,因为这个数据只属于用户。可以跟云厂商要一下相关的说明书。另外也可以通过法律的途径来进行保障安全性的问题。
2、对于据传输,由于训练的数据量非常大,训练的调优时间也非常长。训练和推理有一个不同的特点在于,训练是非实时性的,而Inference是实时性的,因此大家需要提前预留好传输时间;第二,尽量申请更大的带宽,这方面没有特别好的途径,如果有一些非常特殊的场景,可以考虑跟公有云提供商商量通过一些方式将数据导入进去。
3.您可能对NGC的理解有点偏差,NGC只是一个容器的仓库,它不是一个云平台,没有优先级这个概念。
4.云端是支持docker的。
问题四
王武峰-七彩虹-技术经理
1. NVIDIA云端GPU深度学习与国内竞品对比的主要优势是什么?
2. GPU training的云端部署和本地部署在未来5-10年的 比例预估是各占多少?
张景贵:1、在没有介绍NGC之前,可能大家对NGC的理解有些偏差。我们跟国内这些云公司不存在竞争关系,而是合作的关系,云公司通过使用NGC容器可以让用户更好地使用他们云上的GPU。
3、对于这个问题,我们目前暂时没有相关的数据,也没有看到第三方关于这个数据的报告,大家可以多留意NGC的报告,如果拿到的话,大家也可以多分享,同时多关注智东西等公众号,这些公众号上也会经常会推送一些分析的文章。
问题五
刘文-北京工业大学-计算机专业
NGC相比其他工具性能如何?NGC提供的GPU是否只能用来做深度学习?
张景贵:我的理解可能是开源的与自己搭建的相比。对于NVIDIA来说,首先是跟深度学习框架的厂商会有些联合创新开发;第二,如果是有一些硬件的新特性或者软件的新特性,我们内部以及深度学习框架上的是会优先知道,因此在一块,我们开发会步入得比较早。当然,如果大家的技术实力比较强,可以自己搭建调优,也可以进行一些尝试。NGC容器主要目的让大家快速地使用一个性能比较好的版本,如果有兴趣的同行,可以继续深入研究;刚才课堂上讲到,容器包含有五类,除了深度学习,还有高性能计算、可视化以及合作伙伴的一些容器等等,因此NGC提供的GPU不只是用来深度学习的。
问题六
Bob-欧盛自动化-软件工程师
1.NGC支持哪些平台?
2.NGC 视觉处理的速度是多少?峰值是多少?
张景贵:1、从硬件层面上,只要是NVIDIA GPU Pascal之上的都可以运行,包括桌面端和服务器端的;从软件层面上,目前我们并没有明确列出,因为对于Docker来说,它在软件层面是比较开放的,一般主流的操作系统比如Ubuntu等都是支持的。
2、NDC是对相关的软件做了优化,它运行的速度需要看实际使用的硬件平台,如果视觉使用的是一个性能比较高的卡,再加上软件优化,那么性能肯定比较高;如果视觉使用的是落后一代或者几代的卡,仅仅靠软件优化是达不到很好的优化效果的。因此,软件优化只是一部分,运行处理速度需要看综合情况。
问题七
彭勇-新高兴-算法工程师
在进行项目开发时,当需要调用容器中没有的软件依赖包时,是否可以灵活添加软件依赖包?
张景贵:NGC是授权给个人用户使用NGC容器的,也允许你在这个容器里进行自己的一些配置以及升级软件包。另外,NGC容器中默认是没有IP地址的,如果是你想在容器里配置IP,则需要下载一些相关软件包,这些都是可以安装的,安装了之后内部使用是没有问题的,但是是不允许商业性的分发操作。
课件获取
第一讲,NVIDIA大中华区高性能计算及Applied Deep Learning部门技术总监主讲赖俊杰,主题为《如何搭建适合自己的深度学习平台》
第二讲,NVIDIA高级系统架构师吴磊主讲,主题为《如何为深度学习和HPC提供更高算力》
第三讲,NVIDIA DLI认证讲师侯宇涛主讲,主题为《不需要写代码,如何用开源软件DIGITS实现图像分类》(线上实践课程,无课件)
第四讲,图玛深维首席科学家陈韵强、NVIDIA高级系统架构师付庆平共同主讲,主题为《深度学习如何改变医疗影像分析》
第五讲,NVIDIA DLI认证讲师侯宇涛主讲,主题为《手把手教你使用开源软件DIGITS实现目标检测》(线上实践课程,无课件)
第六讲,西安交大人工智能与机器人研究所博士陶小语、NVIDIA高级系统架构师易成共同主讲,主题为《智能监控场景下的大规模并行化视频分析方法》
第七讲,清华大学计算机系副教授都志辉、NVIDIA高级系统架构师易成共同主讲,主题为《GPU加速的空间天气预报》
第八讲,希氏异构人工智能首席科学家周斌主讲,主题为《如何利用最强GPU搭建医疗人工智能计算平台——医学图像AI领域最强超级计算机首次解密》
第九讲,NVIDIA中国GPU应用市场总监侯宇涛主讲,主题为《揭秘深度学习》
第十讲,NVIDIA高级系统架构师张景贵主讲,主题为《在你的桌面端通过NVIDIA云端GPU开展深度学习》
第十一讲,百度AI技术生态部高级算法工程师赵鹏昊主讲,主题为《如何借助GPU集群搭建AI训练和推理平台》
第十二讲,NVIDIA 深度学习解决方案架构师罗晟主讲,主题为《医疗领域的深度学习》
扫描下方二维码关注智东西公开课服务号,回复关键字“NVIDIA”获取往期课件

