








智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
智东西4月11日报道,今日,面壁智能宣布完成新一轮数亿元融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。本轮由光源资本担任独家财务顾问。
这是华为哈勃又一次出手投资大模型企业。此前它在去年8月参与了AI4Science独角兽企业深势科技超7亿元的股权融资。深势科技曾推出分子大模型Uni-Mol、科学文献多模态大模型Uni-SMART等。
华为哈勃最新投资的面壁智能,成立于2022年8月,总部在北京,是国内最早开始探索大模型和AGI的团队之一。去年4月,面壁智能完成数千万元天使轮融资,知乎领投,智谱AI跟投。
面壁智能的核心研发团队脱胎于清华NLP实验室,团队还有来自阿里、字节、百度等国内外知名公司的人才。在创立初始阶段,面壁即开始Agent研究探索,2023年发布了大模型驱动下的Al Agent “三驾马车”,全面覆盖单体智能、群体智能和智能体应用框架领域。
在高效推理方面,面壁率先以“衔尾蛇投机采样”为代表的协同推理技术,在云侧建立起大小模型之间的协同,极大提升云侧大模型的服务速度。与面壁端侧模型相结合,有望通过端云协同推理来进一步降低大模型使用成本。
目前面壁智能已完成了贯彻高效训练、高效落地与高效推理的大模型全栈技术生产线布局,与招商银行、数科网维、知乎等合作伙伴一同将大模型与Agent技术部署落地于金融、教育、政务、智能终端等应用场景。
继今年2月开源发布端侧模型面壁MiniCPM后,面壁智能今日推出了新一代MiniCPM 2系列模型,包括4款模型:
 ▲面壁智能联合创始人、CEO李大海发布MiniCPM 2系列模型
▲面壁智能联合创始人、CEO李大海发布MiniCPM 2系列模型
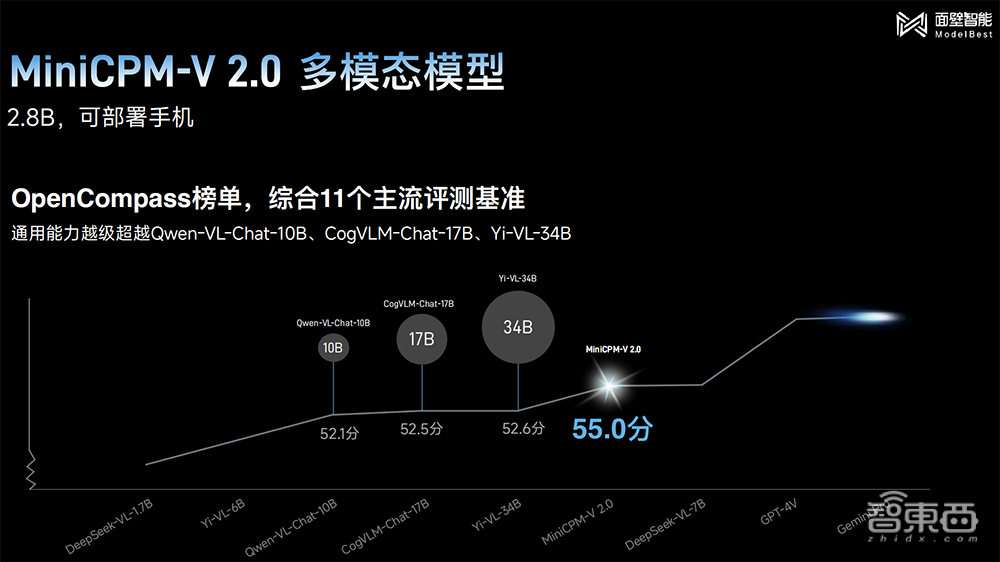
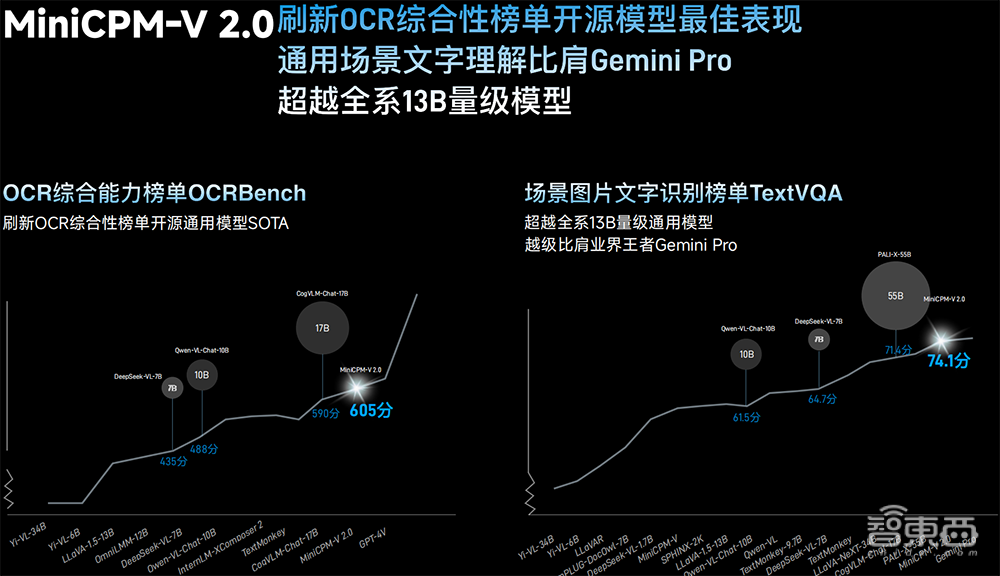
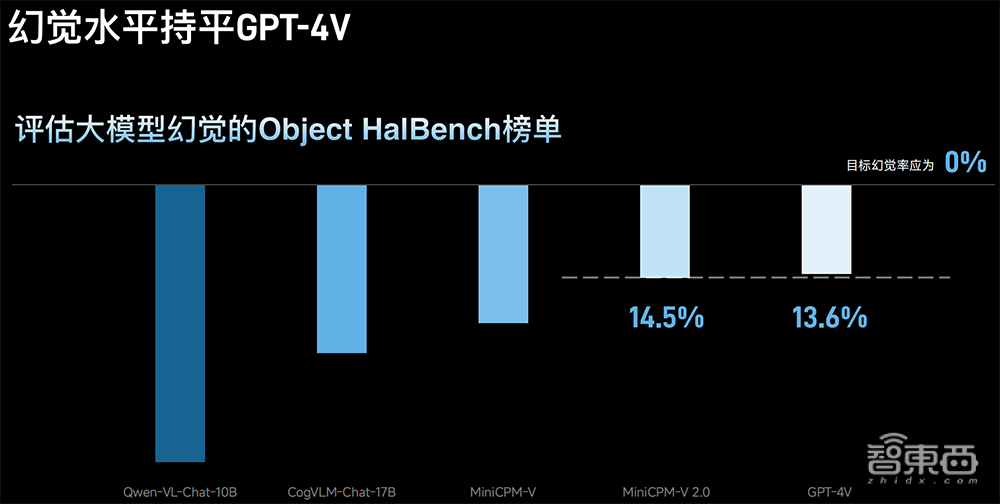
1、MiniCPM-V2.0多模态模型:参数规模仅2.8B,小到可以部署在手机上,显著增强了OCR(光学字符识别)能力,刷新OCR综合性榜单开源模型表现,通用场景文字理解能力比肩Gemini Pro,超过Owen-VL-Chat-10B、CogVLM-Chat-17B等百亿级参数量的模型,中文OCR识别能力显著超过GPT-4V,幻觉水平与GPT-4V持平。
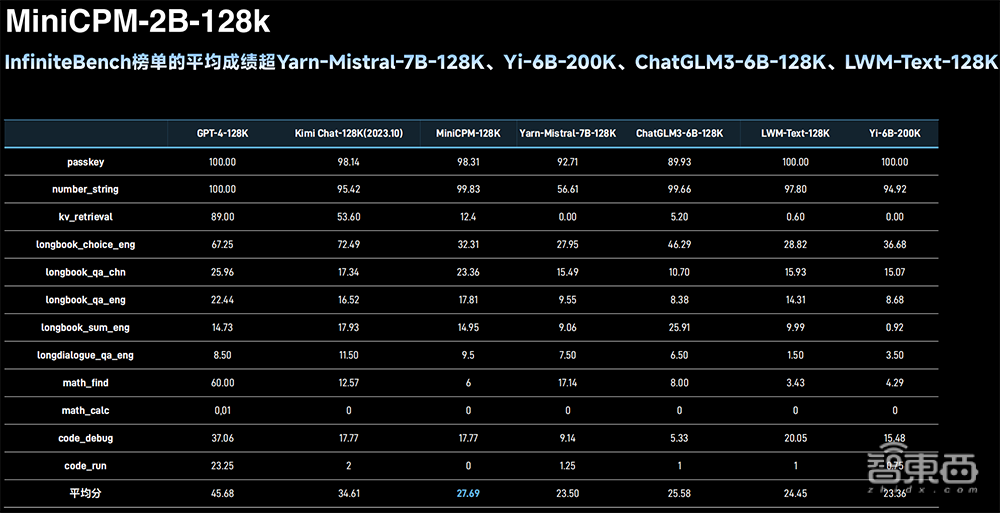
2、MiniCPM-2B-128k长文本模型:最小的128K长文本,将原有的4K上下文窗口扩展到了128K,在InfiniteBench榜单上的平均成绩超过了Yarn-Mistral-7B-128K、Yi-6B-200K、ChatGLM3-6B-128K、LWM-Text-128K等6B、7B量级模型。
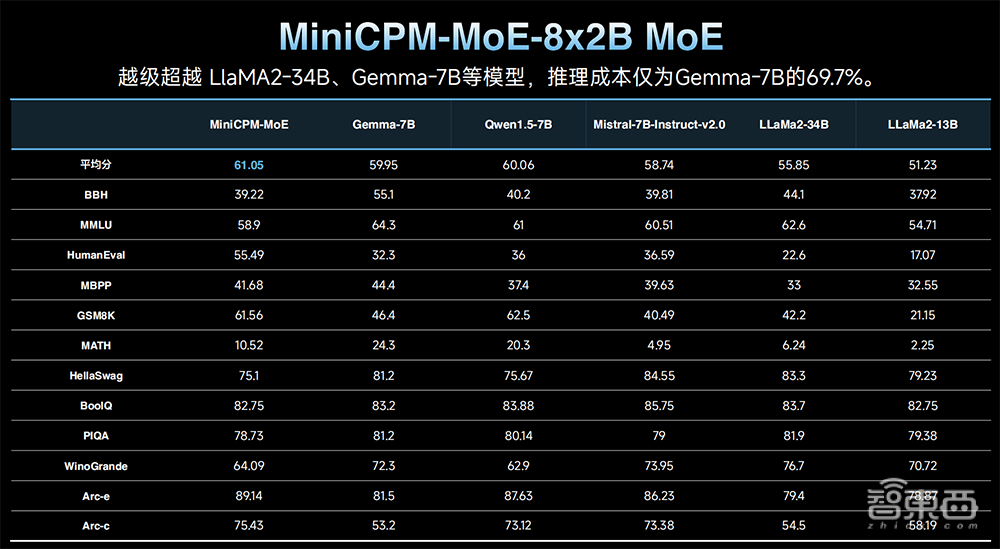
3、MiniCPM-MoE-8x2B MoE模型:引入MoE架构,性能增强,超过Llama 2-34B及全系7B量级模型,推理成本仅为Gemma-7B的69.7%。
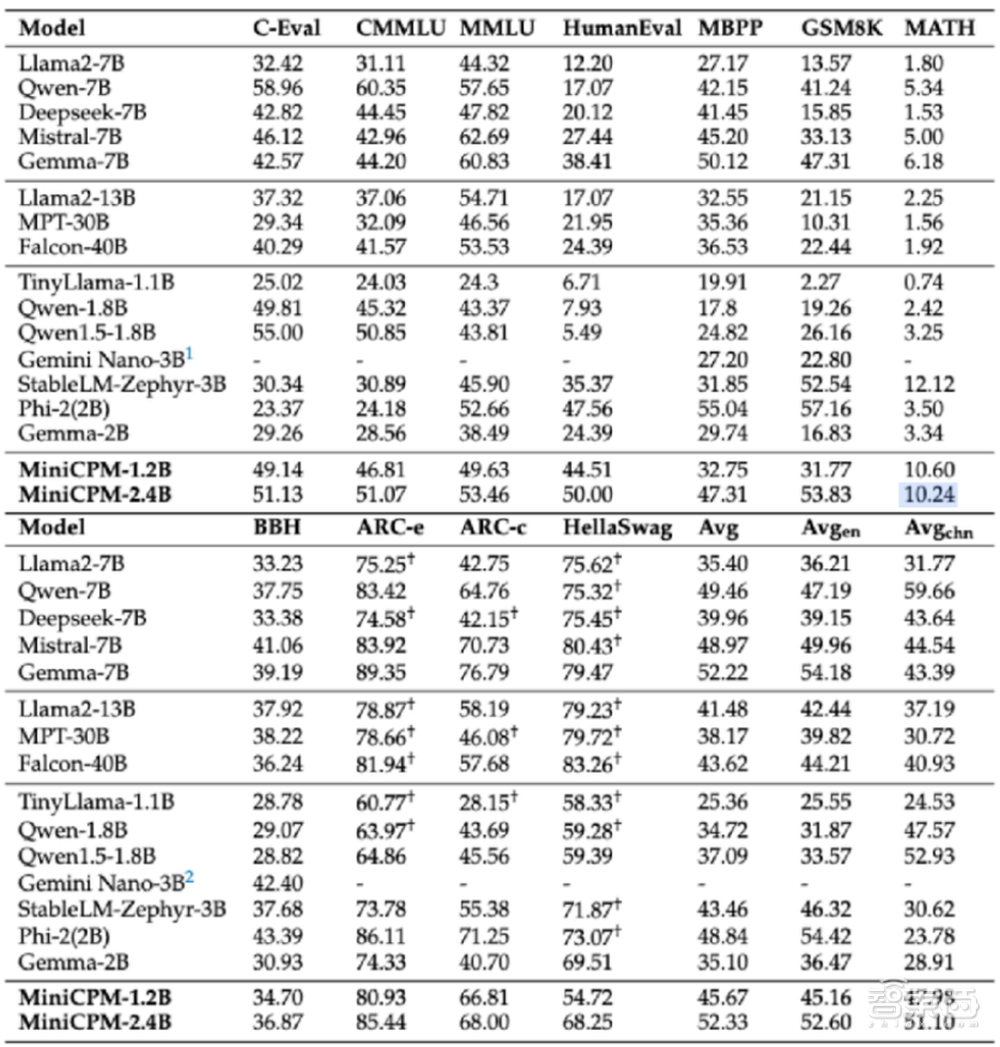
4、MiniCPM-1.2B模型:参数减少一半,仍保持上一代2.4B模型87%的综合性能,比上一代推理速度提高38%。在多个公开权威测试榜单上,取得了综合性能超过Qwen-1.8B、Llama 2-7B甚至超过Llama 2-13B的成绩。在iOS上,MiniCPM-2.4B的量化模型是2.10G,而MiniCPM-1.2B只有1.01G,占用内存减少51.9%,估算成本下降60%。
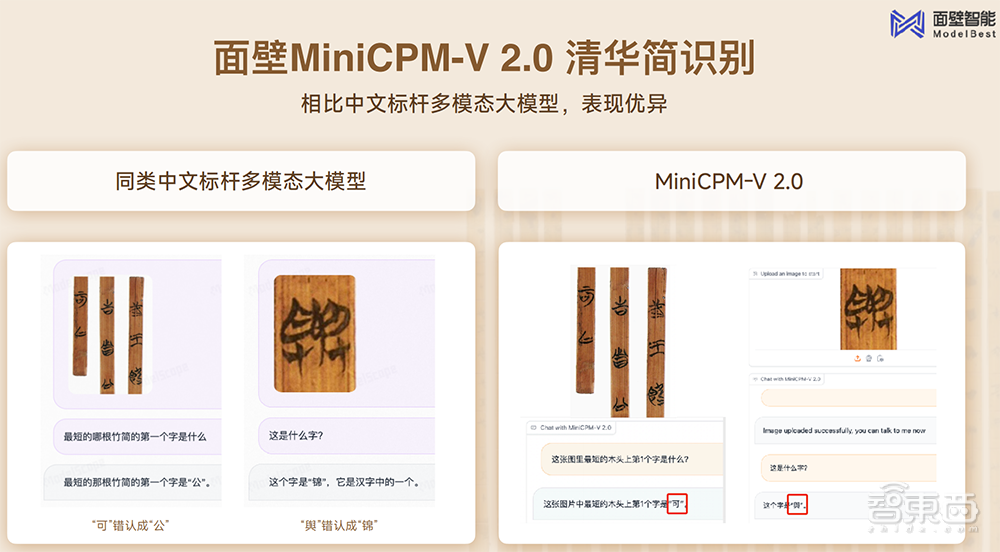
上述模型中,新一代MiniCPM-V 2.0多模态大模型的通用能力大大增强, 结合古文字语料,尝试破解古籍中的谜团,对清华大学收藏的一批战国竹简——清华简进行了字迹识别,相比同类中文标杆多模态大模型,表现更优异。
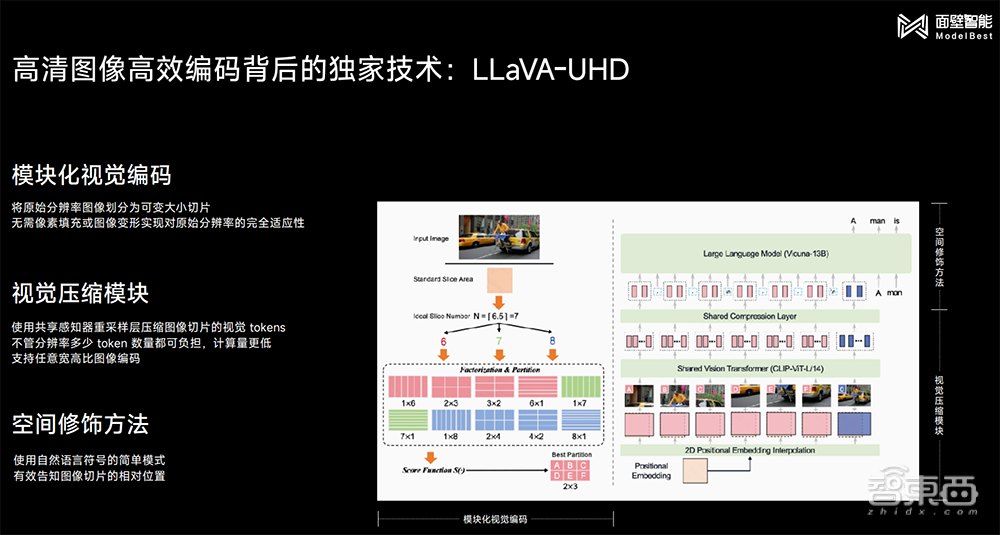
传统方法通常只能处理448×448像素的小图,难以读取被压缩到模糊的文字信息。而有着复杂画面及文字细节的街景长图,通常得是高清大图,才能将这些细节充分呈现。

MiniCPM-V 2.0基于在高清图高效编码方面的技术,可以处理高至180万像素(1344×1344)的高清大图,而且可以是这一像素内任意宽高比的图像,并能支持448×4032这种1:9的极端宽高比无损编码。它也能快速识别长图文字,捕捉重点信息。

其高清图高效编码背后的独家技术是LLaVA-UHD。
基于跨语言多模态泛化技术,新一代MiniCPM-V 2.0可以快速识别全英文菜谱,这样一来,出国但外语不好的人就能用手机轻松点菜。
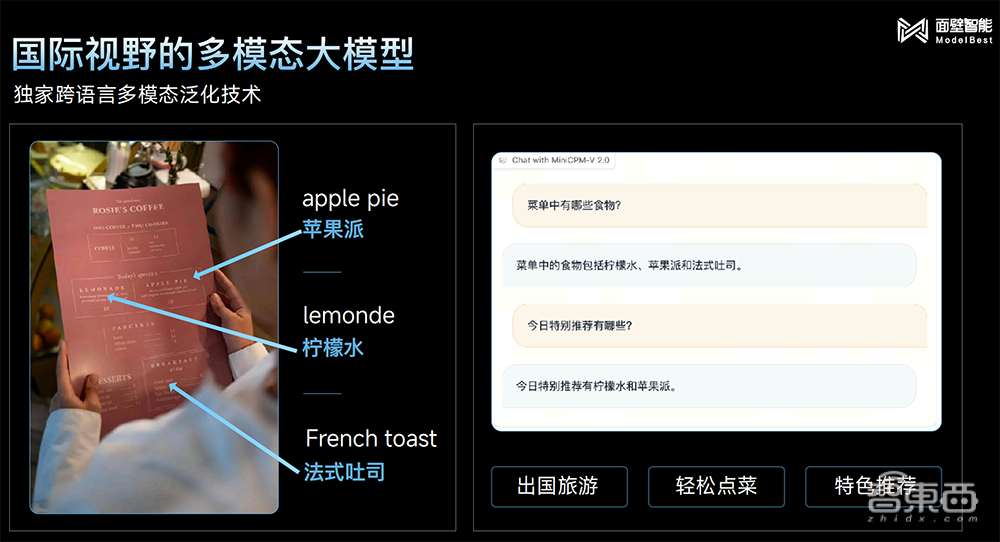
该技术的研究论文发表于ICLR 2024,旨在解决中文领域缺乏高质量、大规模多模态数据的挑战,基于基座模型中英双语能力,仅通过英文通用域图文对数据进行预训练,实现多模态基础能力从英文到中文的跨语言泛化。
