








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西4月10日报道,昨夜,英特尔在年度Intel Vision大会上重磅推出新一代AI训练芯片Gaudi 3,正面向英伟达旗舰芯片发起挑战。
会上,英特尔CEO基辛格挥舞着Gaudi 3,跟随现场伴奏开心地摇晃起身体,随后宣布Gaudi 3的战绩:相比英伟达上一代旗舰H100 GPU,Gaudi 3的训练性能可提高70%,推理性能提高50%,能效提高40%,同时价格低得多。

在跑1800亿参数Falcon模型时,Gaudi 3的推理速度比英伟达H200快30%。
Gaudi 3采用台积电5nm制程、128GB HBM2e DRAM内存、第五代Tensor Core架构,内存带宽高达3.7TB/s,共有24个200Gb以太网端口。不过英特尔没有公布这块芯片的晶体管总数。

和英伟达、AMD一样,英特尔在最新AI芯片中通过“芯片拼装”设计来超越reticle极限。
Gaudi 3基于统一内存架构,将将64个Tensor Core封装在两个计算Tile中,共享96MB缓存池,借助高速互连技术,两个计算Tile能宛如一个完整芯片一样运行。
相比上一代Gaudi 2,Gaudi 3在BF16精度下可提供4倍的AI计算能力、1.5倍的内存带宽、2倍的网络带宽,支持大规模系统横向扩展,最多可扩展至8192个芯片的参考架构。

基辛格说,Gaudi 3将帮助AI经历三个阶段,从AI Copilot时代迈向AI Agent时代,然后抵达全功能AI时代,即用于自动化复杂的、企业范围的结果。
他预言当发展到第三阶段,功能自动化带来的效率意味着或将出现“一人拥有10亿美元资产的公司”。
英特尔计划从第一季度和第二季度分别开始向OEM/ODM合作伙伴提供风冷版和液冷版的Gaudi 3芯片样品,从第三季度开始加大风冷部件的出货量,第四季度加大液冷设计的出货量。英特尔还将在开发者云中提供Gaudi 3的支持。

Gaudi 3应该会是英特尔最后一代对标H100的AI训练芯片。毕竟对于今年刚发布过最新旗舰GPU芯片B200的英伟达来说,H100/H200已经是上一代的事了。英伟达Blackwell GPU将在今年晚些时候上市,可以想见Gaudi 3抢占市场份额的机会多狭窄,面临的竞争压力将有多大。
令人稍有困惑的是,根据英特尔路线图,Gaudi 3后续产品将变成IP融入到英特尔的Falcon Shores平台里,也就是说英特尔GPU Max和专用AI芯片产品线将在2025年融合。

按这个发展走向,很难说英特尔什么时候会推出下一代专用AI芯片,如果英特尔一直基于现有芯片参与市场竞争,或者将研发重心向GPU倾斜,Gaudi 3可能会成为“时代的眼泪”。

一、罕见披露FP8浮点性能,训练130亿参数模型比H100快70%
负责研发专用AI芯片的英特尔Habana团队一向不喜欢用FLOPS来展现AI性能,而是倾向于突出其在实际应用中的性能。
原因之一是,FLOPS限定条件多,比如测量精度、是稀疏型还是稠密型、利用率多高……这些因素会可能导致理论和实际性能差别很大。
不过这次,他们相当罕见地披露了Gaudi 3在FP8精度下的总吞吐量——1835TFLOPS,达到上一代FP8性能的2倍。

在稠密型FP16/BF16精度下,英特尔Gaudi 3的浮点性能可达到1835TFLOPS,高于英伟达H100/H200的989TFLOPS、AMD MI300X的1307TFLOPS。
但如果比FP8精度,H100/H200和MI300X的浮点算力较FP16翻倍到1979TFLOPS、2614TFLOPS,性能反超不支持稀疏化的Gaudi 3。
不过换个角度来看,Gaudi 3在FP16/BF16精度下能实现接近竞品FP8精度下的性能,已经足见其性能优势。
与英伟达旗舰GPU相比,英特尔新一代AI训练芯片Gaudi 3的性能提升如下:
1、训练Llama 7B、13B以及GPT-3 175B模型,速度比H100快40%~70%。
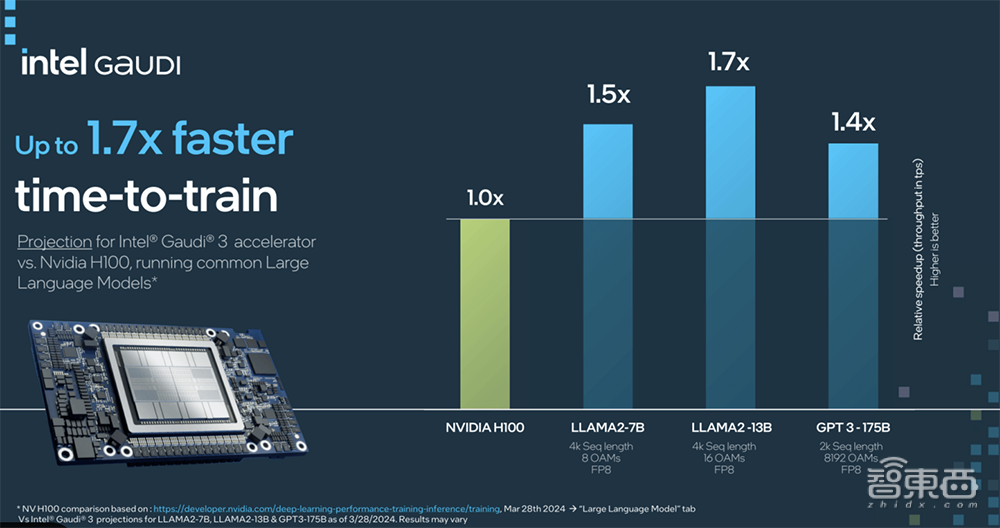
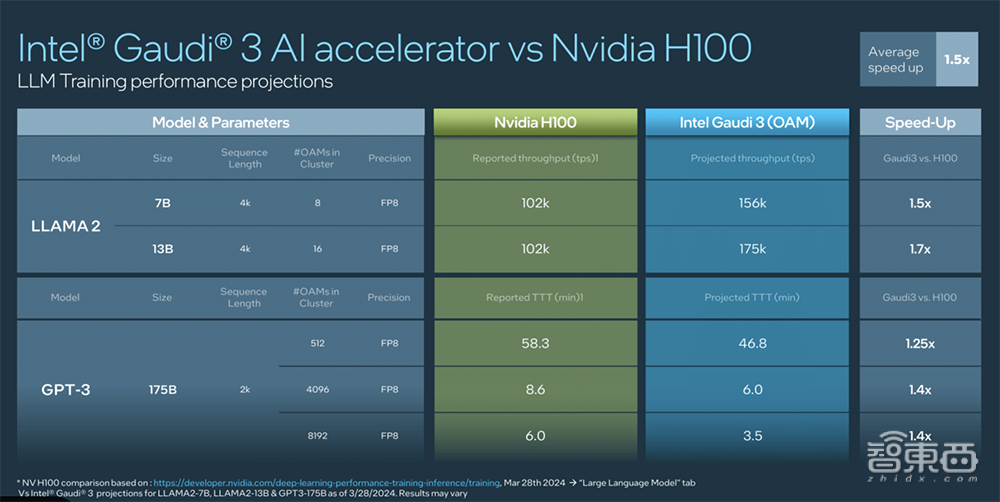
看起来,Gaudi 3在训练参数规模较小的模型时更能展现出训练优势,训练1750亿参数GPT-3模型是用了基于1028个节点、8192个Gaudi 3的集群。
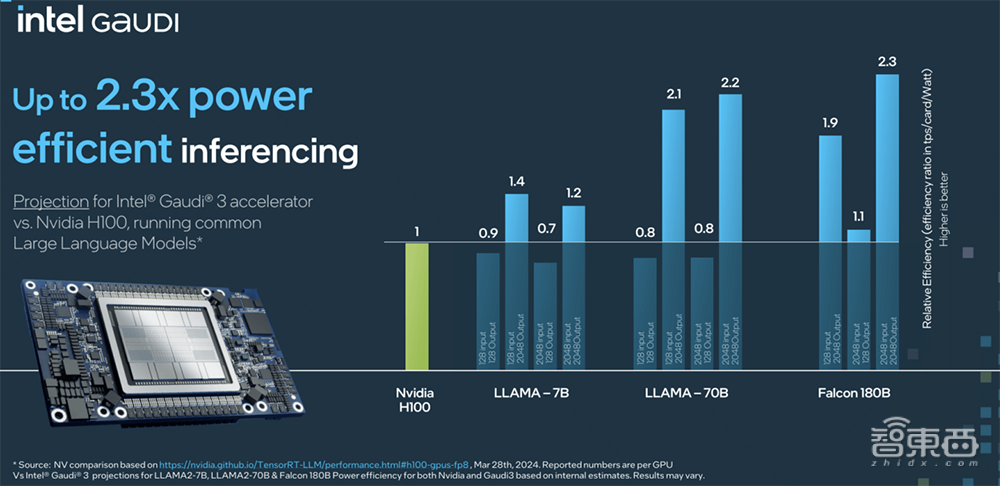
2、跑Llama 7B、70B以及Falcon 180B模型,推理速度比H100快50%,推理能效提高40%,在较长输入和输出序列上的推理性能优势更大。
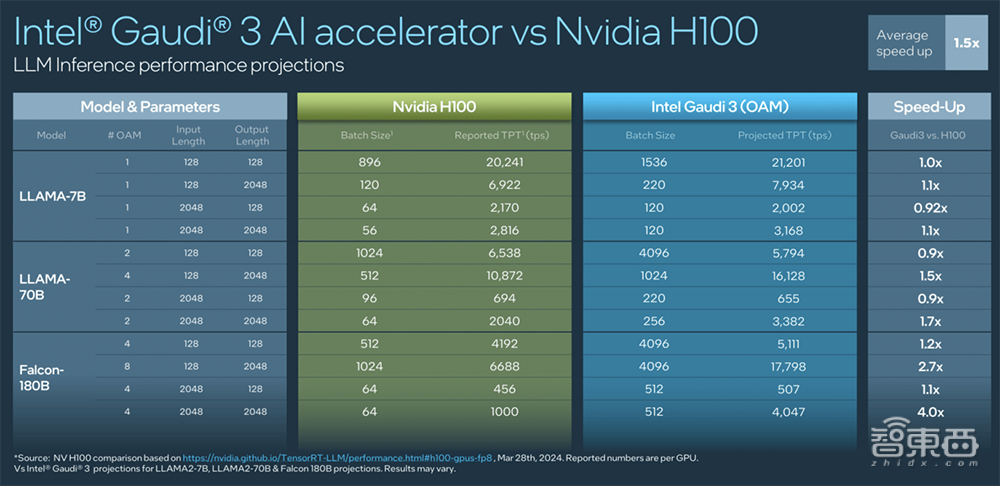
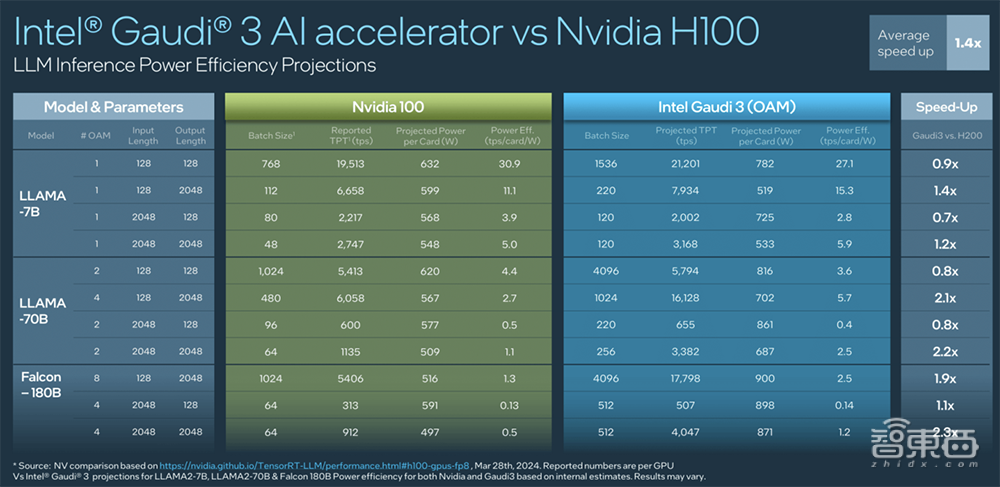
3、跑Llama 7B、70B以及Falcon 180B模型,推理速度最多可以比H200快30%。
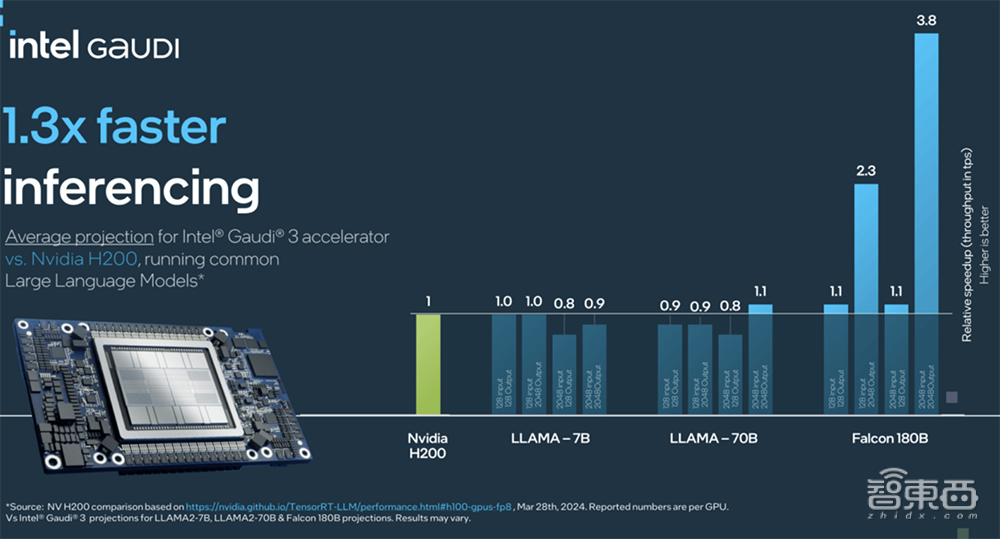
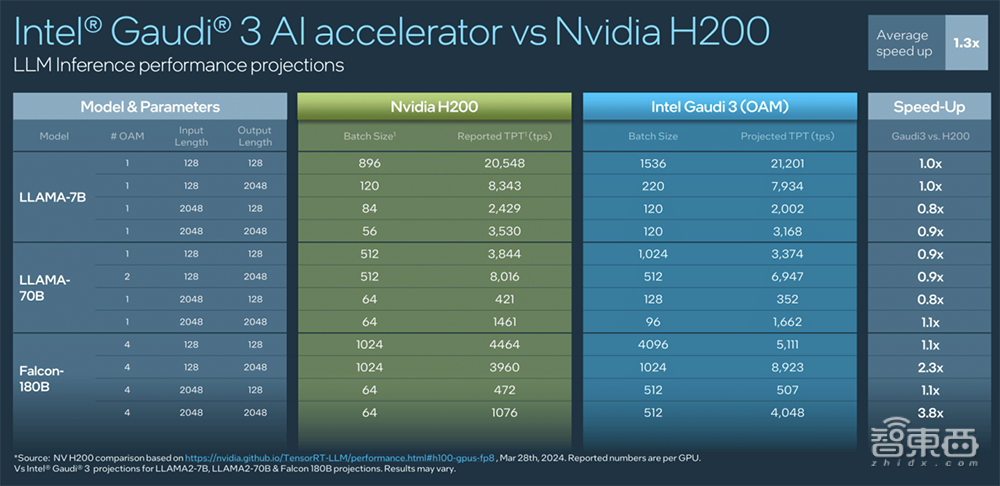
从图表中可以看到,在跑Llama 7B、70B时,Gaudi 3与H200 PK得略显吃力。
虽然英特尔披露的这些数据不好验证真实性,但从过往来看,英特尔一向光明磊落,积极参与权威基准测试MLPerf,无惧披露真实AI性能、与英伟达旗舰芯片产品同台较量,很有大将风范。
这多少会带来更可靠的印象,进而持续扩大英特尔Gaudi系列在AI训练市场竞争的赢面。
二、双芯设计,台积电5nm,128GB内存
英特尔Gaudi 3采用将两个计算Tile、8个HBM封装在一起的设计方式,共有96MB SRAM、8个矩阵数学引擎和64个Tensor Core。这种将两块芯片当一块芯片用的拼装思路,与英伟达上个月发布的Blackwell芯片相似。

Gaudi 3采用台积电5nm、128GB HBM2e,内存带宽达3.7TB/s。从这些保守的制程和内存选择,很难看出它对最强AI训练芯片的势在必得。
现在市面上最先进的制程已经是3nm,其竞品英伟达H100和AMD MI300X都已经用上更先进的HBM3高带宽内存。
英伟达H200采用141GB HBM3e,内存带宽达4.8TB/s;AMD MI300X采用192GB HBM3,内存带宽达5.3TB/s。无论是内存的容量还是带宽,都比Gaudi 3更有竞争力。
据外媒报道,Habana首席运营官Eitan Medina解释说,坚持采用HBM2e的原因是风险管理,其方法是只使用在流片前已在硅片中得到验证的IP,Gaudi 3流片时根本没有经过验证符合其标准的物理层。
相比单芯片性能,英特尔强调的是大量Gaudi 3芯片互连形成的集群能提供更高的性价比和TCO。
现在AI计算竞赛的焦点在大模型上,单卡内存根本不够用,需要将多个AI芯片连接在一起来支撑大模型训练及推理。
性能比拼也不再是看单卡峰值性能,而是比拼大规模扩展后的整体系统性能和TCO,即达到同等算力,谁能节省更多的电力和成本。
因此先进互连技术对数据中心越来越重要。
H100/H200采用英伟达专用互连技术NVLink,总带宽达900GB/s;MI300X采用AMD专用互连技术Infinity Fabric,总带宽达896GB/s。
对比之下,Gaudi 3采用的是常规的ROCe,集成了24个200Gb以太网端口,总带宽达1.2TB/s。其中有3个端口用于节点外通信,剩下1Tb/s用于服务器内芯片之间通信。
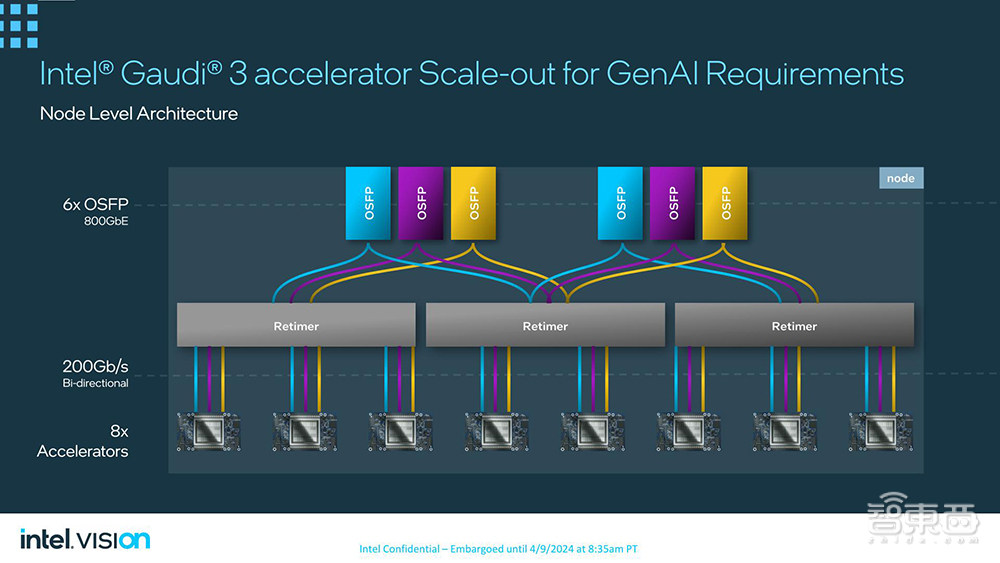
英特尔称,通过将以太网网卡集成到其加速器中,使用传统的主干叶架构扩展以支持512个甚至1024个节点的集群变得更加容易。
这种以太网设置的另一种好处是吸引那些不想投资或换用专有互连技术的客户。
通过超以太网联盟,英特尔正驱动面向AI高速互连技术(AI Fabrics)的开放式以太网网络创新,并推出一系列面向AI优化的以太网解决方案,以大规模纵向和横向扩展芯片,支持越来越庞大的AI模型的训练与推理。
其产品组合包括英特尔AI网络连接卡(AI NIC)、集成到XPU的AI连接芯粒、基于Gaudi加速器的系统,以及一系列面向英特尔代工的AI互联软硬件参考设计。
除了网络外,软件也是英特尔的重头戏。英特尔认为大多数程序员都在AI框架级别或者更高级别进行编程,使用CUDA进行低级编程已经不那么普遍,也就是说英伟达的软件生态护城河已经不像原来那样坚不可摧。
目前英特尔正在不断优化迁移工具和牵头参与行业标准的制定,向市场提供CUDA替代方案。
三、可扩展至8192芯,提供15EFLOPS算力
总结一下英特尔Gaudi 3的主要亮点:
1、AI专用计算引擎:有独特的异构计算引擎,由64个AI定制和可编程TPC以及8个MME组成。每个Gaudi 3 MME能执行64000 次并行操作,实现高计算效率,使其擅长处理复杂的矩阵运算、加速并行AI操作。该芯片支持多种数据类型,包括FP8和BF16。
2、满足大语言模型要求的内存容量:128GB HBMe2、3.7TB/s内存带宽、96MB板载SRAM提供了充足内存,可在更少的Gaudi 3芯片上处理大型生成式AI数据集。
3、面向企业生成式AI的高效系统扩展:Gaudi 3集成了24个200Gb以太网端口,提供灵活且开放标准的网络,支持大型计算集群,可高效地横向和纵向扩展至数千个节点。
4、开放行业软件,提高开发者效率:Gaudi软件集成了PyTorch框架,并提供优化的Hugging Face社区模型,使生成式AI开发人员能够在高抽象级别上进行操作,从而提高易用性和工作效率,并易于跨硬件类型迁移模型。
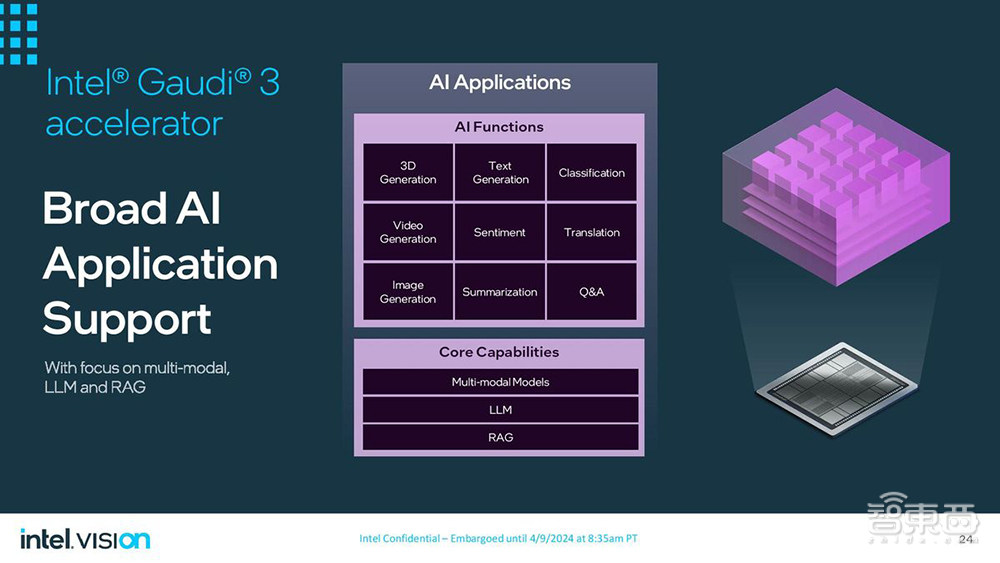
英特尔已经开发了一个端到端AI软件栈,包括从固件、库、驱动程序到开各种AI应用所需的模型、框架和工具。

5、Gaudi 3 PCIe add-in卡:专为实现高效率和低功耗而设计,非常适合微调、推理和检索增强生成 (RAG) 等工作负载,采用全高、双宽、10.5英寸长设计,被动冷却,TDP仅为600W。

除了PCIe add-in卡,Gaudi 3还提供符合OCP标准的OAM模块、搭载8个加速器的通用基板。PCIe规格与OAM版本相同,功耗更低。OAM的TDP在风冷版可达900W,液冷版可达1200W。

英特尔也为Gaudi 3开发了参考架构。
搭载8个Gaudi 3的单个节点,FP8性能可达14.7PFLOPS,拥有1024GB内存和8.4TB/s网络带宽。512个节点,可提供7.5EFLOPS算力,有524.3TB内存容量、614TB/s网络带宽。
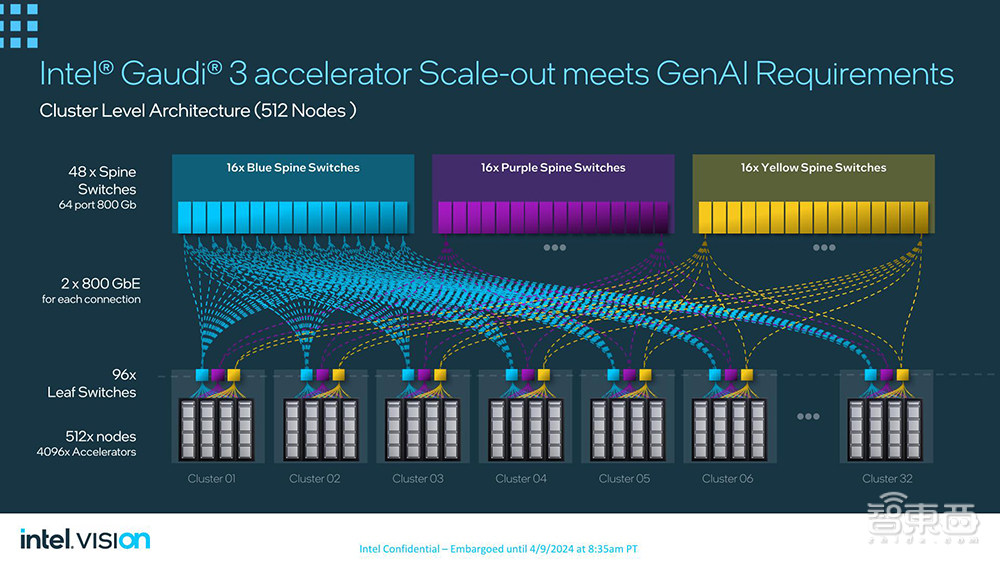
Gaudi 3最多可扩展到由8192个芯片组成的1024个节点的集群,可提供15EFLOPS算力、1PB内存容量、1.229PB/网络带宽。

结语:大规模AI计算已经进入系统竞赛
在Intel Vision大会上,“生成式AI”这一主题可以说是贯穿全程,从数据中心的大规模AI训练与推理,到AI PC改变端侧生产力,英特尔正竭力展示自己作为先进芯片技术领导者的竞争力。
如今谈到大模型训练芯片,英伟达当仁不让是首选供应商,但这棵摇钱树早已被其他芯片大厂和创业新秀盯上,英特尔便是其中之一。英特尔正通过推出更具性价比的可扩展系统来打破这种一家独大的局面,这将为市场带来另一种选择。
大规模AI计算已经进入系统竞赛,无论是守擂者英伟达,还是英特尔、AMD、Cerebras、Groq等追击者,都明显加大对先进Chiplet封装、先进存储、先进互连技术的重视,通过从超越制程和reticle极限的芯片内部设计优化,到扩展至大型集群系统的技术升级,为整个数据中心的AI计算提供更高性能和能效的加速。
除了Gaudi 3,英特尔还在Intel Vision大会上分享了数据中心至强处理器和AI PC的进展,并现场连线远在英特尔晶圆厂的同事,演示如何在AI PC上用先进AI技术辅助芯片检测。
英特尔宣布面向数据中心、云和边缘的下一代处理器进行品牌焕新,即英特尔至强6。配备能效核的至强6(此前代号为Sierra Forest)将于2024年第二季度推出,配备性能核的至强6(此前代号为Granite Rapids)将紧随其后推出。
配备性能核的英特尔至强6包含了对MXFP4数据格式的软件支持,与使用FP16的第四代至强处理器相比,可将下一个token的延迟时间缩短至原来的15%,能运行700亿参数Llama-2模型。
英特尔预计将于今年出货4000万台AI PC,以及超过230种的设计,覆盖轻薄PC和游戏掌机设备。新一代英特尔酷睿Ultra客户端处理器家族(代号Lunar Lake)将于今年推出,具备超过100 TOPS平台算力,NPU算力超过46TOPS。
