







智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 漠影
国产大模型又双叒出圈了?
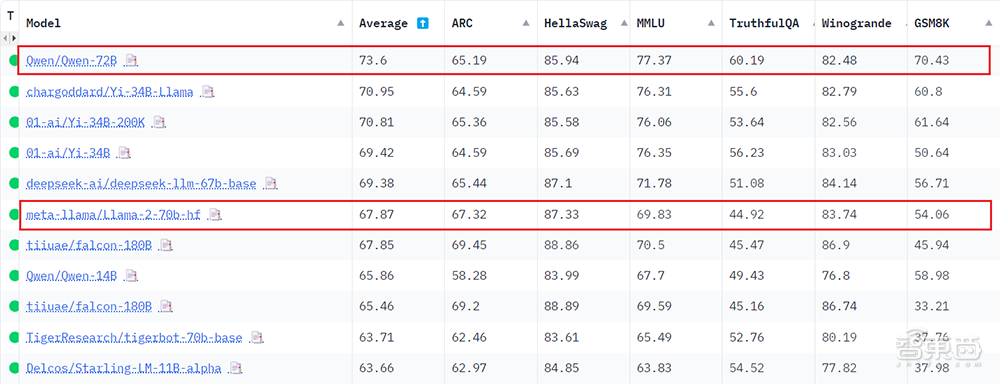
智东西12月12日报道,近日,阿里云通义千问720亿参数的模型Qwen-72B力压Llama 2等国内外开源大模型,登顶全球最大模型社区Hugging Face的开源大模型排行榜(Open LLM Leaderboard)榜首。
▲Hugging Face开源大模型排行榜,数据截至12月12日
在六个维度的测评中,通义千问取得平均73.6分的成绩。其中,在考察数学推理能力的GSM8K和考察事实性问答能力的TruthfulQA基准上,通义千问分别超出Llama 2分数的30.3%和34%。
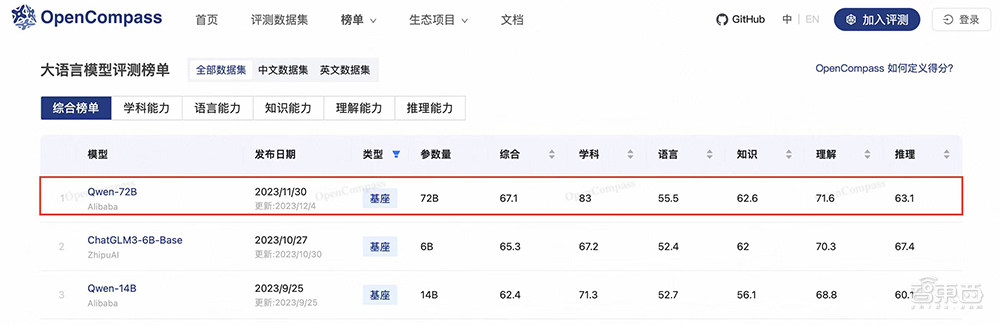
而就在今天,在由上海AI实验室推出的、国内权威开源大模型评测OpenCompass的最新中文大模型榜单上,通义千问72B同样拿下第一。
▲OpenCompass中文大模型榜单,数据截至12月12日
开源12天,通义千问72B即斩获多项权威测评榜单冠军,硬实力备受专业认可。
在开源社区,通义千问72B引发了一波全球开发者的狂欢,有国外学者认为这一开源模型在处理某些任务中的表现与GPT-4不相上下。截至目前,通义千问全系列开源模型累计下载量已突破150万,催生出150多款新模型、新应用。
来自中国的超强开源大模型,是如何炼成的?智东西对话了通义实验室的科学家,寻求答案。
一、全球开发者热捧,学者称与GPT-4不相上下
12月1日,阿里云宣布正式开源720亿参数的大语言模型——通义千问Qwen-72B。
模型一经发布,立刻在社交平台X上引起大量海内外开发者关注和转发。
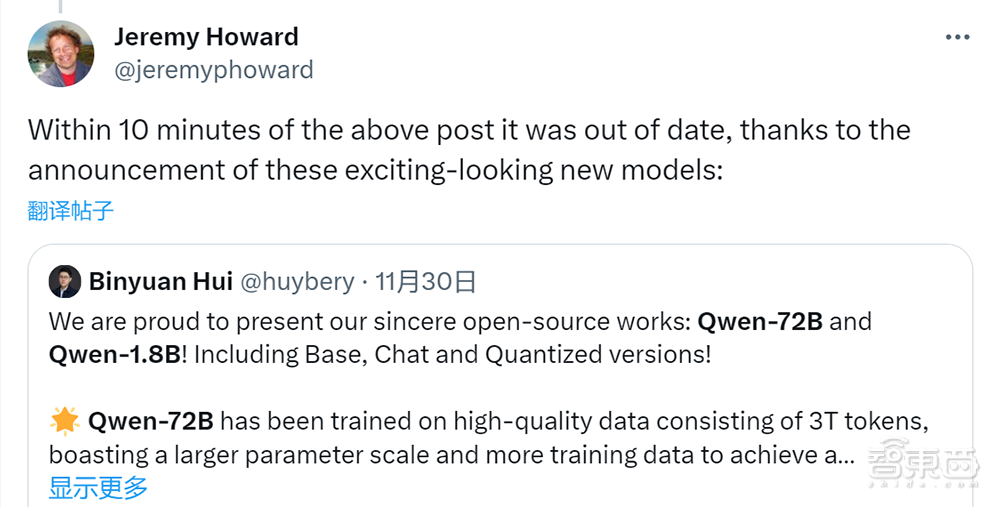
数据科学家、AI研究机构fast.ai联合创始人Jeremy Howard转发通义千问的发布帖子并称:“由于这些令人兴奋的新模型的发布,上述帖子在发布10分钟后就过时了。”在这之前,他刚刚转发了一篇关于另一款中国开源大模型DeepSeek基准测试成绩的推文。
通用机器人1X公司AI副总裁、谷歌前高级研究科学家Eric Jang转发称:“伟大的工作!这篇技术论文非常值得一读,我很高兴他们还开源了对齐的VLM。”

微软365管理平台创企CoreView首席技术官Ivan Fioravanti连用几个感叹号表达自己的激动:“又一个新的大模型可以测试了!几个月后,这些模型将变得异常强大!”
一名关注AI的波兰学者称:“乍一看,确实令人印象深刻。再仔细一看,(通义千问)在处理波兰语方面,与GPT-4不相上下(而Llama2在这方面表现糟糕)。”
印度NLP科学家、数据科学社区Maxpool创始人Pratik Bhavsar则认为,该模型在很多任务上已经超越了GPT-4,并且迫不及待地想用通义千问来实现商业化应用落地。
在国内,中小企业和创业公司也对开源的通义千问十分青睐。具身智能机器人创企有鹿智能的创始人、CEO陈俊波曾称通义千问为“目前至少在中文领域智能性表现最好的开源大模型之一”。

▲有鹿智能创始人、CEO陈俊波(图源:阿里云)
华东理工大学X-D Lab的学生开发者颜鑫,已经基于通义千问开源模型开发了心理健康大模型MindChat(漫谈)、医疗健康大模型Sunsimiao(孙思邈)、教育/考试大模型GradChat(锦鲤)等。通义千问72B开源后,颜鑫十分好奇它如何刷新“我们领域中的能力极限值”。
“我们可能基于Qwen-72B做些学术探索,包括利用联邦学习算法处理数据。”

▲华东理工大学X-D Lab的学生开发者颜鑫(图源:阿里云)
二、屠榜多个开源模型权威评测,大幅超越Llama 2成新标杆
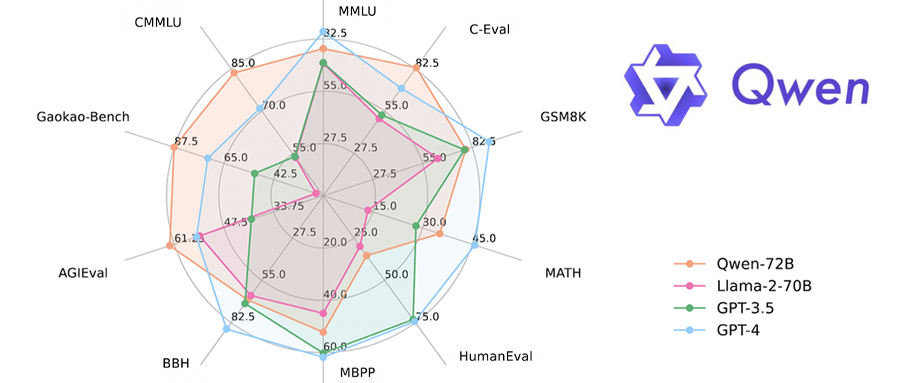
通义千问Qwen-72B开源发布时,就在10大权威测评集中取得了开源模型最优成绩,其中还有4个基准的成绩超越了闭源模型GPT-4。
值得一提的是,在数学能力测评基准MATH上,Qwen-72B取得35.2分,是同规模Llama 2的近乎三倍。
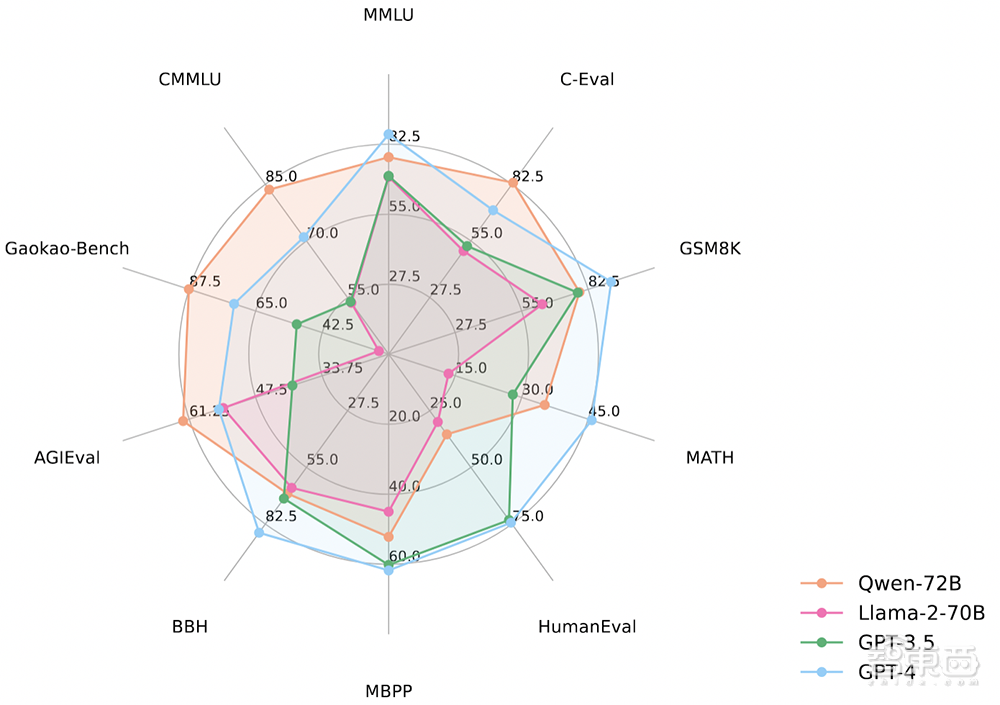
▲Qwen-72B在10大权威测评上的成绩
在今日刚刚更新的OpenCompass开放评测体系中,Qwen-72B夺得开源基座模型(Base)第一。
▲OpenCompass大模型排行榜,数据截至12月12日
在OpenCompass中文能力的测试中,通义千问72B基座大模型和对话大模型包揽前二,已经与包括GPT-4在内的主流模型拉开差距。
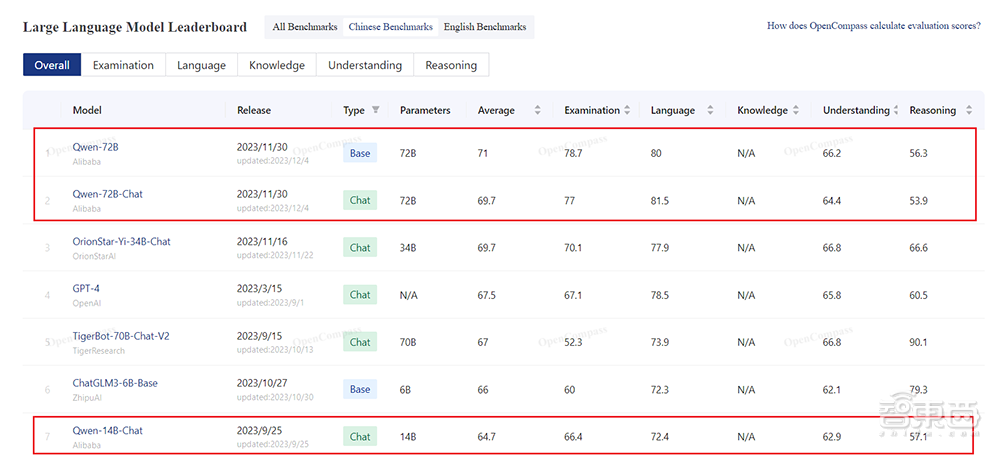
▲OpenCompass中文大模型榜单,数据截至12月12日
几天前,通义千问72B登顶最权威的Hugging Face开源大模型排行榜。该榜单收录了全球上百个开源大模型,测试维度涵盖阅读理解、逻辑推理、数学计算、事实问答等六大评测。
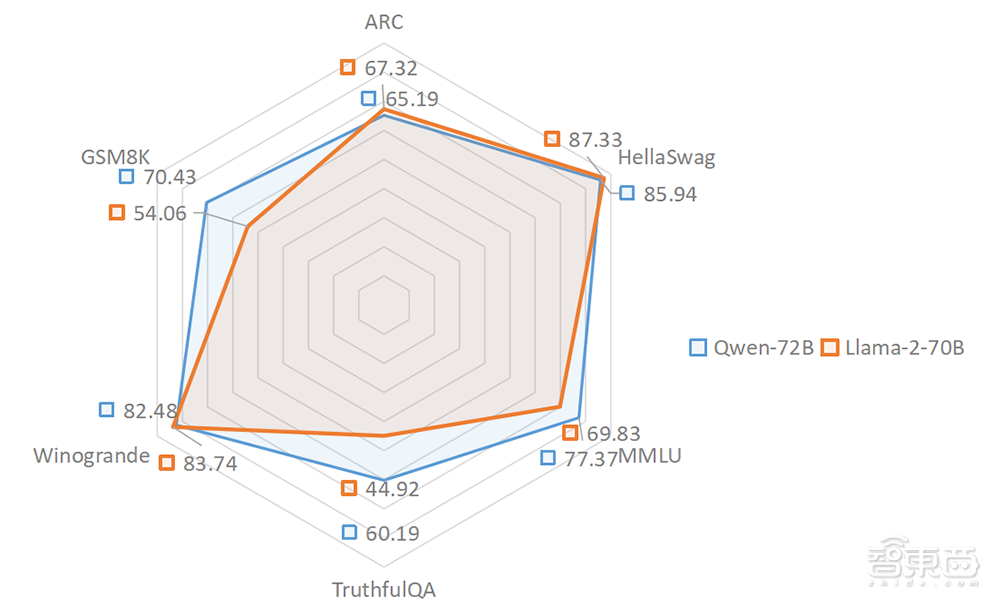
▲Qwen-72B与Llama-2-70B在六大测评上的成绩
其中,通义千问在MMLU、TruthfulQA、GSM8K三个基准上的成绩都大幅超越Llama 2。
对应到具体能力上,MMLU考察模型的世界知识和语言能力,是一个综合评测。TruthfulQA 考察模型的常识问答,包含常识能力、抗幻觉能力、问答能力等。GSM8K则考察模型的数学推理和计算。
在实际应用中,通义千问各方面的能力表现如何?
首先来看一道经典数学题:0.999无限循环和1哪个大?

通义千问的解题逻辑清晰,结果正确。
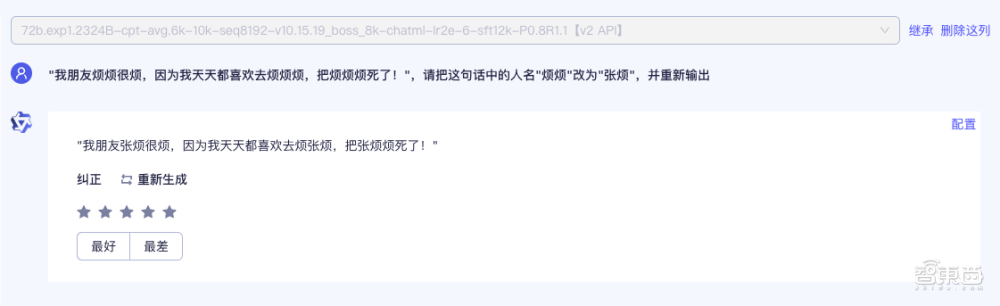
在对中文的理解上,通义千问也能准确识别出复杂的叠词:
再来看一道逻辑推理题:天堂地狱两扇门,两个门卫,一个说真话,一个说假话,只能对一个人提问一次,如何找出天堂之门?

通义千问没被难倒,准确地通过逻辑分析找到了问题的答案。
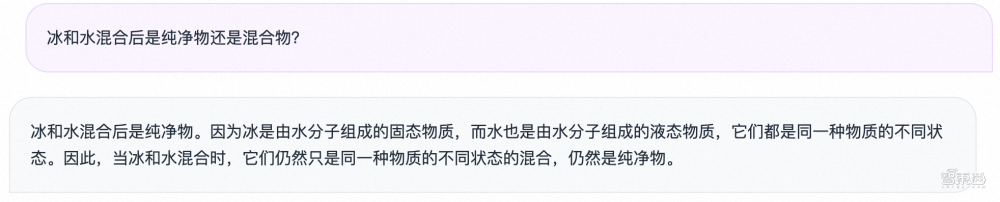
常识方面,通义千问也是不在话下,准确回答出了冰和水混合后是纯净物还是混合物。
面对“坑向”的假设性问题,通义千问也在努力尝试给出合理的回答。
总的来看,通义千问72B性能十分抗打,超越Llama 2成为开源大模型的新标杆。
三、强悍的开源大模型,是如何炼成的?
那么问题来了——Qwen-72B为什么能有这么出色的性能?
阿里巴巴通义实验室科学家告诉智东西,通义千问大模型的持续优化和进步,主要依赖三大基础能力。
首先,训练更扎实,方法更先进。
在Qwen-72B模型的训练上,阿里云利用多达43T的高质量数据进行训练,折合7T Tokens,数据涵盖近20种语言,覆盖金融、法律、医疗等领域。同时,通义千问团队对数据配比和数据源进行了优化,目前已使用了更高质量、更具多样性的3T Tokens进行训练。
在训练方法上,通义千问团队综合利用了DP(数据并行)、TP(张量模型并行)、PP(流水线并行)、SP(序列并行)等方法进行大规模分布式并行训练,并引入FlashAttention-2等高效算子提升训练速度。
其次,AI基础设施全面升级,大模型训练又快又好。

在今年的云栖大会上,阿里云CTO周靖人就曾表示,阿里云全面升级了AI基础设施。这大幅提升了大模型的训练和推理的效率,通义千问72B开源模型的推出就是最新例子。
借助阿里云AI平台PAI的拓扑感知调度机制,通义千问团队有效降低了大规模训练时通信成本,将训练速度提高30%。
此外在训练稳定性方面,通过PAI平台AiMaster管理组件监控作业的日志、报错、Metrics等信息,团队可以区分用户错误和系统错误,根据作业类型和容错场景提供管理能力和全链路自动化运维能力,自动剔除故障机器重启任务,使训练过程中人工干预重启频率由每天降低到每周。
据悉,中国有一半大模型公司都跑在阿里云上,百川智能、智谱AI、零一万物、昆仑万维、vivo、复旦大学等大批头部企业及机构均在阿里云上训练大模型。
最后,来自应用场景和开源社区的充沛反馈也帮助研发团队不断迭代和优化基础模型。
目前,全球大模型领域主要有两条技术路线。一条是以OpenAI的GPT-4为代表的闭源路线,另一条是以阿里云的通义千问、Meta的Llama 2等为代表的开源路线。
闭源模型的定制性不如开源模型,无法满足现阶段模型应用市场的多样化需求。
阿里云是国内最早开源自研大模型的科技企业,陆续开源了Qwen-7B、Qwen-14B、Qwen-72B和Qwen-1.8B四款大语言模型,还开源了两款多模态大模型——视觉理解模型Qwen-VL和音频理解大模型Qwen-Audio,率先实现了大模型“全尺寸、全模态”开源。
阿里云也为开发者提供了更便利更普惠的大模型服务:开发者可在魔搭社区直接体验系列模型效果,也可通过阿里云灵积平台调用模型API,或基于阿里云百炼平台定制大模型应用;阿里云AI平台PAI还针对通义千问全系列模型进行深度适配,推出轻量级微调、全参数微调、分布式训练、离线推理验证、在线服务部署等服务。
智东西从一些开发者群里了解到,站在用户的角度上看,之所以选择国产开源模型,一是因为开源模型性价比高、定制化程度高,能够适应现阶段千行百业对大模型应用的多样化探索。
二是借助开源社区的有效反馈和集体智慧,开源模型能够更加快速地迭代优化、壮大生态,甚至一些问题都是类似的,更容易找到现成的解决方案。
最后,国内用户需要更加可控、更懂中文的强大模型,通义千问72B在中文能力上远超Llama 2,相比国外模型,这是中国自研大模型不可替代的优势。
结语:开源生态助力大模型市场“飞轮效应”
在12月1日通义千问发布会上,周靖人曾表示,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”。
在阿里云畅想的“大模型自由市场”中,通义千问只是“百模”之一。而Qwen大模型系列的开源开放,则是阿里云知行合一,开展大模型生态建设的最佳实践。产业生态是构筑商业闭环和竞争壁垒的关键,越早将大模型推向市场,越多吸纳用户的反馈来反哺大模型,越能实现“模型越强、应用越多,应用越多、模型越强”的“飞轮效应”。
超越Llama 2是国产大模型“百模大战”中的一个节点,通过更广泛的落地应用、更繁荣的生态,进一步向最强闭源大模型GPT-4发起冲击,或许是AI之战中,以阿里云为代表的中国公司更有机会获胜的关键路径。
