








今年9月起,智东西公开课品牌全新升级为智猩猩。智猩猩定位硬科技讲解与服务平台,提供公开课、在线研讨会、讲座、峰会等线上线下产品。
「AI新青年讲座」由智猩猩出品,致力于邀请青年学者,主讲他们在生成式AI、LLM、计算机视觉、机器学习等人工智能领域的最新重要研究成果。
AI新青年是加速人工智能前沿研究的新生力量。AI新青年的视频讲解和直播答疑,将可以帮助大家增进对人工智能前沿研究的理解,相应领域的专业知识也能够得以积累加深。同时,通过与AI新青年的直接交流,大家在AI学习和应用AI的过程中遇到的问题,也能够尽快解决。
有兴趣分享学术成果的朋友,可以与智猩猩教研产品团队进行邮件(class@zhidx.com)联系。
目前,大多数大语言模型都仅支持短文本输入,而实际应用中,很多任务都需要长文本输入能力,如长文档的总结、提问等。传统方法为了进行长度拓展通常需要使用超过100块以上的A100 GPUs或TPUs,这样的计算资源消耗对大多数研究而言都是难以持续的。

为了解决这样的问题,麻省理工学院韩松团队和香港中文大学贾佳亚团队联合提出了基于 LoRA 的全新大模型微调方法:LongLoRA ,仅用一台8卡机器就能将 Llama2 模型从原本的4k tokens 处理长度拓展到 32k,甚至是 100k。
此外,为了提升模型的长文本对话能力,团队还构建了高质量长文本对话数据集 LongAlpaca-12k,并开源了首个 70B 参数量的长文本大语言模型 LongAlpaca-70B。该工作的代码、数据集、模型和 demos 已经全部开源在https://github.com/dvlab-research/LongLoRA。
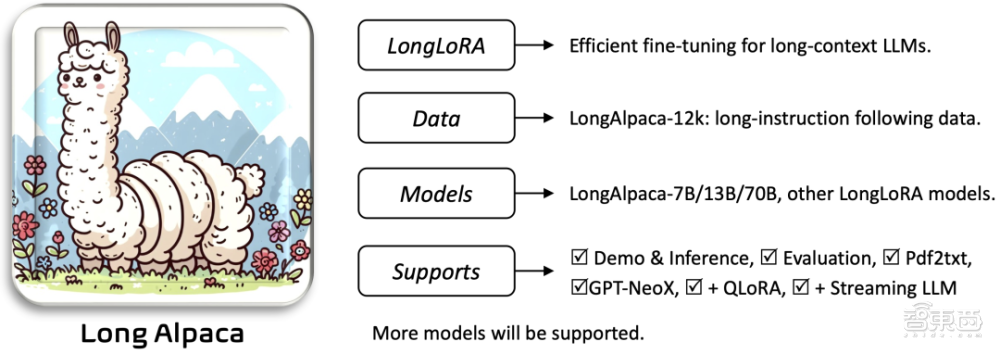
11月27日晚7点,「AI新青年讲座」第230讲邀请到 LongLoRA 一作、香港中文大学在读博士陈玉康参与,主讲《高效的大型语言模型长文本训练方法 LongLoRA》。
讲者
陈玉康,香港中文大学在读博士;研究方向包括大语言模型、AutoML、3D 视觉等,曾在 CVPR、NeurIPS、T-PAMI 等顶级会议期刊上发表论文20篇,Google Scholar Citation 1300+。
第230讲
主题
《高效的大型语言模型长文本训练方法 LongLoRA》
提纲
1、大语言模型长文本对话的难点
2、基于 LongLoRA 的长文本模型微调方法
3、长文本对话数据集 LongAlpaca-12k
4、开源的长文本大语言模型 LongAlpaca-70B
直播信息
直播时间:11月27日19:00
直播地点:智东西公开课知识店铺
成果
论文标题:《LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models》
论文地址:http://arxiv.org/abs/2309.12307
开源代码:https://github.com/dvlab-research/LongLoRA
