







芯东西(公众号:aichip001)
编 | 韦世玮
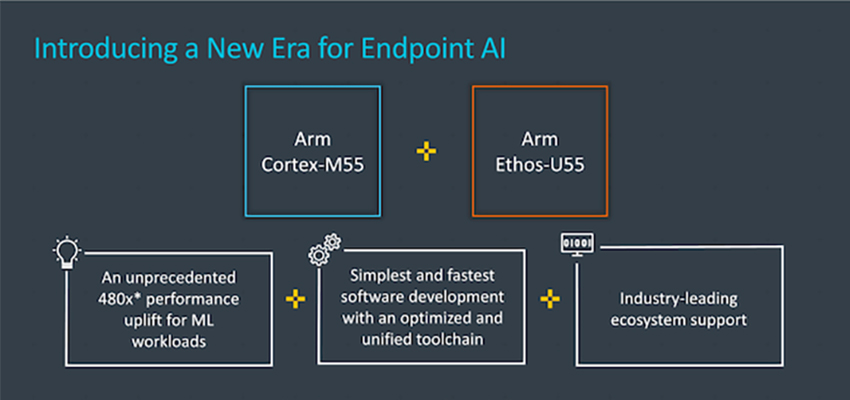
芯东西2月11日消息,今天,Arm推出其人工智能(AI)平台重要新品,包括全新机器学习IP Cortex-M55处理器,以及Ethos-U55神经网络处理器。
其中,Ethos-U55是Arm针对Cortex-M系列处理器推出的首款微神经网络处理器(microNPU),与Cortex-M系列处理器相配合,能进一步提升机器学习性能与能效。
Arm称,Cortex-M55与Ethos-U55的结合使用,能够为微控制器带来480倍的机器学习性能飞跃。
随着机器学习应用在各个行业中愈发普及,在Arm看来,终端AI市场也将在未来几年内呈现爆炸性增长,终端智能设备市场将进一步发展。
因此,Arm通过推出全新IP内核与NPU,在扩展自身AI产品组合的同时,也帮助客户降低芯片开发成本,满足他们提升终端数字信号处理(DSP)和机器学习能力的需求。

一、Cortex-M55:拥有自定义指令集和矢量扩展
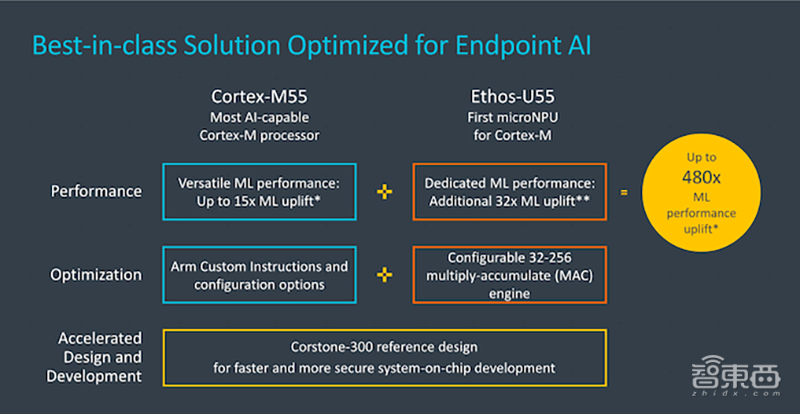
Arm声称,此次推出的Cortex-M55是其有史以来AI功能最强大的Cortex-M处理器,同时也是首款基于Armv8.1-M架构、内建Arm Helium向量处理技术的处理器。
与前几代Cortex-M系列处理器相比,Cortex-M55的机器学习性能最高可提升15倍,DSP性能可提升5倍,能耗比进一步提高。
除此之外,Cortex-M55还支持自定义指令集(Custom Instructions)。在去年的Arm Techcon技术大会上,Arm首次宣布自定义指令集,并与Cortex-M33一起推出。
实际上,这一功能与RISC-V IP内核提供的功能相类似,目的是在密集执行的内核中,将紧凑的指令序列折叠为一条指令,节省功耗和吞吐量。
从传统方式上看,用户要实现这一功能,可以通过内存映射设备来实现,而Arm现在已经可以通过使用协处理器接口,将操作更紧密地与CPU集成在一起。
这就意味着,用户能通过Cortex-M55的自定义指令集延伸处理器能力,对特定工作负载进行优化。

除了自定义指令集外,Cortex-M55还有另一大创新点,它在内核中首次构建了Helium向量处理技术。
Helium,也称为M-Profile Vector Extension(MVE),它能在Arm TrustZone的安全基础上提高Armv8.1-M架构的计算性能。它还引入新的单指令多数据流(SIMD)128位矢量操作,进一步增强DSP和机器学习应用的性能。
在性能方面,Helium能将Cortex-M55的数字信号处理器性能提升5倍,机器学习性能提升15倍。
此外,它还依赖现有的寄存器(非NEON矢量寄存器),并引入对通道(lane)预测、循环(loop)预测、分散/聚集(scatter-gather)等复杂操作的支持。
二、Ethos-U55:简化设计NPU
如果想拥有更高的机器学习系统,用户可以将Cortex-M55与Ethos-U55搭配使用。
Ethos-U55是Arm的首款微神经处理器,与现有的Cortex-M系列处理器相比,Cortex-M55与Ethos-U55的结合能让产品的机器学习性能提升480倍。
性能方面,Ethos-U55拥有高度的可配置性,能加速空间受限的嵌入式与物联网设备的机器学习推理能力。它的压缩技术可以节省电力并缩小机器学习模型的尺寸,同时还能运行以往只能在较大型系统上执行的神经网络运算。
实际上,Ethos-U55与其他Ethos-N系列存在一定区别。
首先,Ethos-N是独立的IP模块,可以放到SoC CCN-500网络上,而Ethos-U旨在与配套的Cortex-M处理器紧密协作,并利用其处理能力。
同时,Ethos-U55还可以与较旧的Cortex-M系列处理器一起使用,如Cortex-M7、M4和M33等。

从Ethos-N系列的多层神经网络(MLP)设计上看,它们是使用多个计算引擎实例构建的,每个实例都包含几个主要组件,如SRAM、MAC计算引擎(MCE)和可编程层引擎(PLE)。
但对Ethos-U55来说,由于功率和面积限制,它的设计相对简单,因此Arm将其称为microNPU。
从概念上讲,Ethos-U55只是一个具有计算引擎的MLP,而从设计上看,Ethos-U55在设计过程中删除了PLE。
主要原因在于,Ethos-N系列的PLE将Cortex-M CPU和16通道的矢量引擎集成在一起,导致面积和功耗都相当昂贵,但这对高性能SoC来说还处于可接受的范围。
而Ethos-U55通过与Cortex-M55等CPU相结合,能够让用户摆脱PLE,改为在配套的Cortex-M处理器上进行处理。
虽然这并非一个完整的代替品,但基于严格的功率和面积限制考虑,这不失为一个在可接受范围内的折中方案。
此外,Ethos-U55还删除了较为昂贵的专用SRAM库,因为它只需要很小的SRAM就可以进行足够的内部处理。
Ethos-U55假定外部系统具有某种缓存,可与Cortex-M处理器共享,仍然能完成MLP设计的其他工作。例如,让直接内存存取(DMA)根据需要获取NN层,此外NPU还可以处理内存中的压缩权重和激活工作,在处理之前即时进行解码。
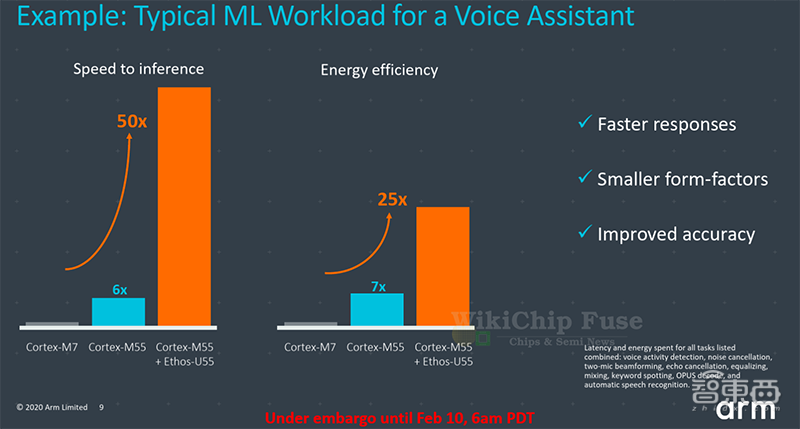
三、M55与U55结合的最高推理性能可提升50倍
Arm声称,与Cortex-M7相比,基于Helium扩展的Cortex-M55,其对典型语音助手类的工作负载推理性能最高可提升6倍,能效可提升7倍。与Ethos-U55结合使用时,这两项性能可分别提高50倍和25倍。
值得一提的是,这些性能要实现提升,必须重新编译代码,以充分利用新的M-Profile向量扩展,以及Ethos MAC引擎的处理能力。
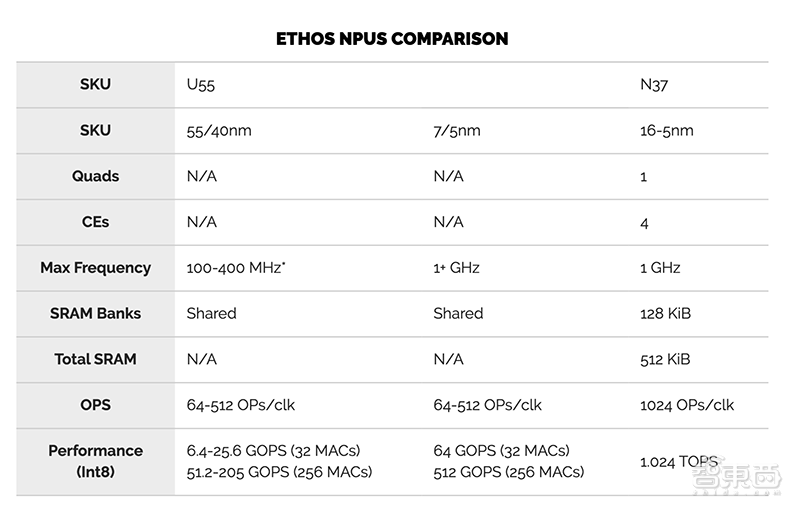
据了解,Cortex-M系列可用于各种芯片和多种工艺技术。
基于此,Arm表示,在55nm或40nm等成熟的节点上,他们希望能看到Ethos-U55的时钟频率可达到100 MHz至400MHz,甚至更高。
为了更好地调整NPU到应用程序,用户可以将MAC计算引擎(Compute Engine)配置为32、64、128或256个MAC。
在32个MAC的最小配置下,用户可以获得6.4-25.6 GOPS的峰值计算性能,而在256 MAC的最大配置下可达到51.2-205 GOPS。
在7nm或5nm这类先进制程节点上,Ethos-U55的时钟频率可达到1 GHz或更高。在这一阶段,128个MAC和256个MAC配置的峰值计算性能,分别为0.25 TOPS和0.5 TOPS。
四、主要合作伙伴已获授权应用
目前,Arm已经向主要合作伙伴开放了Cortex-M55和Ethos-U55的授权,并将在未来几个月内进一步开放,基于此IP的芯片预计在 2021年年初上市并实际投入使用。
在应用方面,Cortex-M55能够广泛地应用于移动设备终端。例如,在智能手机的语音助理、指纹传感器和RF系统中,它能进一步实现这些工作负载的优化。
据了解,已经获得Cortex-M55和Ethos-U55授权的公司有谷歌、恩智浦、意法半导体、赛普拉斯和恒玄科技等。
其中, Google微控制器用TensorFlow Lite部门产品经理Ian Nappier谈到,Arm的这一全新IP进一步推进了在终端设备上实现机器学习,并达成数十亿个具备TensorFlow功能设备的共同愿景。
而这些设备仅依靠电池就能运行神经网络模型,并长达数年之久,还可直接在终端设备上实现低迟延的推论。
另外, 意法半导体微控制器部门总经理Ricardo De Sa Earp也说到,全新的Arm Cortex-M55能够为意法半导体的下一代微控制器,带来所需的机器学习性能与效率提升,从而进一步提升各项AI应用。
结语:为AI终端市场打开创新突破口
作为半导体领域重要的IP架构供应商,长期以来,Arm架构一直占领着移动设备领域指令集架构的重要地位。
对Arm自身而言,随着AI和机器学习等技术的不断成熟和发展,它也持续研发出新的IP架构、完善各类AI产品组合,以满足市场越来越多的AI需求,而此次Cortex-M55和Ethos-U55的推出,也进一步为现在的AI终端市场撕开了又一创新方向。
移动设备领域IP架构的市场竞争仍十分激烈,架构开源、高性价比等需求也愈发鲜明。未来,Arm将如何依靠自身的丰富经验和优势,在众多对手的市场竞争中脱颖而出?我们拭目以待。
文章来源:WikiChip
