








智东西(公众号:zhidxcom)
文 | Lina
智东西11月21日消息,今天,微软小冰首席科学家宋睿华、首席NLP科学家武威、首席语音科学家栾剑在一场小型媒体交流会上介绍了微软小冰今年在自然语言处理、语音学研究、多模态生成等领域研究进展。

▲从左到右:微软小冰首席NLP科学家武威、首席语音科学家栾剑、首席科学家宋睿华
在会后的采访中,栾剑告诉智东西,在AI编曲方面,小冰将寻找更多数据,生成更多的模式和风格。比如小冰可以从“抖音神曲”中挖掘现在流行的音乐风格,生成更好的音乐。
一、AI学会北极熊怎么“蹑手蹑脚”
据微软小冰首席科学家宋睿华介绍,最近几年,微软小冰团队在各大国际会议上发表了48篇论文/文章、获得了包括全双工AI技术在内的72项专利。
当前小冰已经在搭载在4.5亿台第三方智能设备,平均对话轮数(CPS)达到23轮。
宋睿华分享了小冰在比喻、联想方面的进展,以及如何让小冰像人一样能将故事理解成画面。

▲小冰通过联想连接词等方式生成的比喻句
此外,小冰像人一样能将故事理解成画面的能力涉及当前很火的“跨模态理解”技术。
比如在语言方面,当人类阅读一段北极熊捕猎海豹的文字时,脑海中将会主动浮现相应的场景。

而且,虽然文字段落里完全没有提到北极熊是白色的、周围冰天雪地的世界是白色的,但是人类可以通过常识补充这种缺失的信息。
宋睿华告诉智东西,当前,AI在常识领域依旧存在缺失,因为人类不会把习以为常的东西写进文字里,比如人类不会专门说“我今天用两条腿走路”。对于AI常识补充方面,孕育了不少可挖掘的东西。
同时,人类可能没有见过北极熊“蹑手蹑脚”的样子,但可以把自己家里面猫蹑手蹑脚的样子进行代入。通过向人类学习,小冰也可以调动出以前的经验,模拟出当前的场景,像人一样能将故事理解成画面。

▲小冰对“画饼充饥”故事的图像理解
宋睿华告诉智东西,在未来一两年里,微软小冰将继续往多模态方向发展,未来小冰如果有一个具体的形象,变成有摄像头(有眼睛)、有麦克风(有耳朵),这种多模态AI技术将会是未来的发展重点。
二、从简单回复到信息增量
微软小冰首席NLP科学家武威今天分享的主题是《朝向自我完备的对话机器人(Towards a Self-Complete Chatbot)》。
武威说,“自我完备(Self-Complete)”是团队内部自己“造”的词,但是它能够最好地概括小冰过去几年的成果。
对于对话机器人来说,“自我完备”主要指的是具备以下几大能力:

1、具备学习能力(初级能力包括从人类对话进行中学习;高级能力包括从其他对话机器人中学习)
2、具备对话的自我管理能力(初级能力包括能够知道自己在单轮对话中需要表达的内容、高级能力包括有能力把握整个对话流程)
3、具备知识联通能力(能够连接世界上多项多模态知识)
以从人类对话中进行学习来举例,通过小冰团队打造的生成模型(Generation Models)小冰与人类的对话可以从单独进展到多轮、从简单回复进展到具备信息增量的内容等等。
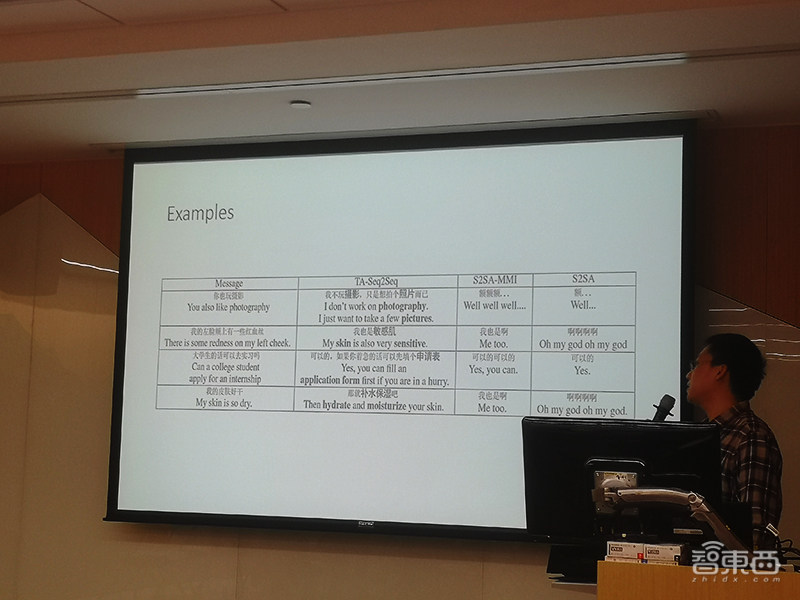
上图是三种不同模型针对同一对话给出的不同回复,当人类给出“我的皮肤好干”对话时,SSA模型给出的回复是“啊啊啊啊”,S2SA-MMI模型给出的回复是“我也是啊”,微软的TA-Seq2Seq模型给出的回复是“那就补水保湿吧”——“补水保湿“就是一个明显的信息增量内容。
武威说,这项研究虽然研究时间不长,但是发展得非常快。
此外,当前,全双工多轮对话等技术在AI语音交互领域非常火,在过去几个月之内,百度、阿里、小米等都陆续发布了相关的新品。
武威告诉智东西,微软小冰很早就推出了相关功能,而且小冰的多轮对话能力不仅仅是让小冰把上下文理解得更准确、给出更准确的回复,更重要的是小冰会把控整个对话流程、进行有来有往的对话引导。因为人类的交流过程不是一个简单的问答模式,而是有目的、有情商的交流。
三、AI唱歌的难点:清唱数据缺乏
微软小冰首席语音科学家栾剑分享了微软小冰在AI唱歌方面的进展。
栾剑说,微软小冰做唱歌技术的原因有三点:1、AI唱歌比AI说话的技术门槛更高;2、唱歌的情感表达更丰富、更激烈;3、唱歌是一个非常重要的娱乐方式。

而唱歌的三大要素则包括吐字发音、节拍、旋律。这三大要素将通过两种方式输入机器,第一种是通过已有音频输入、第二种则是通过曲谱输入。
栾剑说,对于AI唱歌来说,由于清唱数据严重缺乏,必须利用大量混合伴奏音轨的数据进行训练。

针对这一难点,微软小冰团队通过人声部分检测、音素时刻对齐、音高轨迹提取等方式,通过模型+数据的结合,才能成功打造出会唱歌的小冰。
不过,栾剑对智东西强调:微软小冰的语音合成技术现在暂时只会对企业开放,不对个人开放,因为这一技术对用户隐私、AI欺诈等方面存在着很高的风险。
四、落地线上零售,用抖音神曲训练AI
虽然这场分享会以技术进展为主,但微软小冰的研发大咖们也分享了一些微软小冰在落地方面的进展。
比如在线上零售方面,目前,小冰团队已经在日本、美国落地了相应的技术,AI将通过几个简单的问题,迅速判断出用户的购物需求。

比如当用户提出需要购买一份毕业礼物时,AI通过10轮以内的对话陆续挖掘出用户送礼对象的兴趣爱好,最后推荐一份合适的礼物(比如书、相机、咖啡等)。
据武威介绍,这一系统当前用户点击的推荐转化率高达68%。
同时,宋睿华表示,在AI对音乐、文字、图画等创作方面,音乐是一个非常大的市场。因为人类对音乐的消费需求是很大的,但是真正能写歌的人很少。
栾剑表示,现在微软小冰的技术既可以帮助企业定制虚拟歌手、又可以为用户提供音乐工具与平台,让用户更方便地创造自己的歌曲。
在AI作曲的优化方面,栾剑再次强调,数据+模型非常重要。一方面,小冰将寻找更多数据,生成更多的模式和风格。比如小冰可以从“抖音神曲”中挖掘现在流行的音乐风格,生成更好的音乐。
另一方面,在数据不足的时候,可以用专家模式抽取规则,把规则和算法模型更有机地结合。
