








智东西(公众号:zhidxcom)
文 | 心缘
智东西5月26日报道,今天,自然语言处理前沿论坛在北京举办。本届论坛以“机器之‘读、写、说、译’——探寻NLP未来之路”为主题,由百度、中国计算机学会中文信息技术专委会、中国中文信息学会青工委主办。
上午场的演讲主题围绕语义计算和自动问答,介绍这些NLP技术在过去一年的重大进展。
百度高级副总裁、ACL Fellow王海峰首先发表致辞,他表示,NLP不仅需要算法、算力、数据,还需要不断凝练知识,与认知世界和改造世界的过程相结合。

▲百度高级副总裁、ACL Fellow王海峰
哈尔滨工业大学计算机科学与技术学院教授车万翔,北京大学信息科学技术学院研究员、长聘副教授孙栩,复旦大学计算机科学技术学院副教授邱锡鹏,百度NLP主任研发架构师、语义计算技术负责人孙宇分别就动态词向量、稀疏化深度学习NLP、自然语言表示学习以及百度语义计算技术的近期研究和未来发展趋势进行介绍。
中国科学院自动化研究所模式识别国家重点实验室副研究员刘康,百度NLP资深研发工程师、阅读理解与问答技术负责人刘璟分别阐述了所研究的文本阅读理解的进展、数据集和应用,还总结了研究这一领域所需掌握的技能。
一、从“静态”到“动态”词向量的演化过程
哈尔滨工业大学计算机科学与技术学院教授车万翔以《从“静态”到“动态”词向量》为主题发表演讲。
以Word2vec、GloVe等为代表的“静态”词向量已成为基于深度学习的自然语言处理(NLP)技术的‘标配’,这种词向量方法假设“一个词仅由一个向量表示”,降低了建模的复杂度和模型的学习成本,使得在大规模数据上学习词向量成为可能。
然而,这种方法忽略了一个词在不同上下文的差异。比如“我爱吃土豆”和“我在土豆上看视频”中的土豆一个是指食物,而另一个是指视频网站。
有一个方法是基于双语的词向量,即先将中文翻译成英文,进行翻译词抽取后做聚类,然后完成跨语言词义映射和RNNLM。这种方法的问题是需要大规模双语数据,仅是英文中文还好,但再扩展到其他语言就比较麻烦。相较之下,基于单语的词向量方法更为理想。
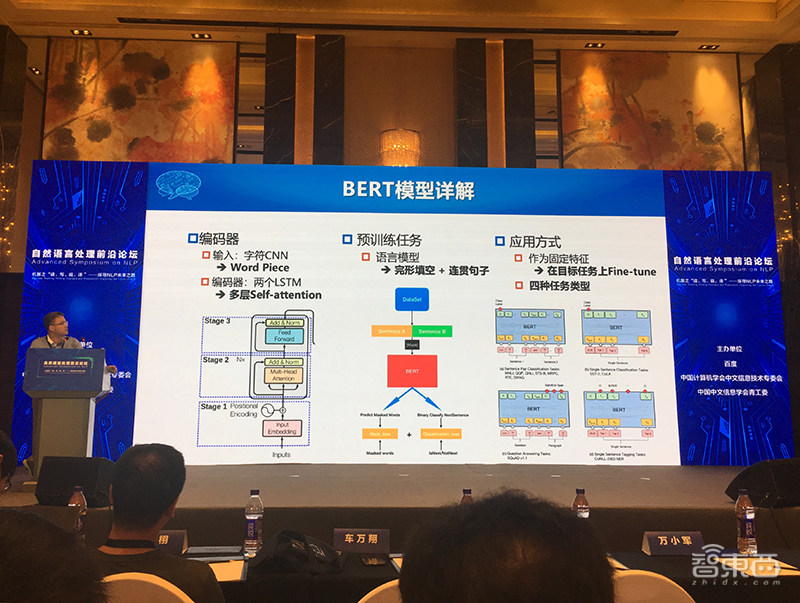
以ELMo和BERT为代表的上下文相关词向量取消了以上假设,在不同的上下文环境下,赋予相同的词以不同的词向量,被称为“动态”词向量,它们在众多NLP任务上取得很好的效果。
这种词向量化的技术一经推出便广受关注,迅速成为NLP领域的热点。
据车万翔介绍,如果不进行微调(Fine-tune),则需要任务相关的复杂模型,而如果进行Fine-tune,则任务相关模型需尽量简单。
车万翔还谈到如何进一步提高系统的性能。除了提高模型和算力外,还可以增加数据。一种增加数据的方法是制造伪数据。它是带标签的预训练数据,不曾面向所研究的任务进行人工标注,标签是样本的近似答案,而非精确答案。

最后,车万翔介绍了几个有趣的研究问题,包括跨语言自然语言处理、如何更好发挥“动态”词向量的迁移能力、轻量级“动态”词向量等。未来研究方向有挖掘伪数据、优化模型(规模和速度)、应用于生成模型等。
二、稀疏化深度学习自然语言处理的近期研究
北京大学信息科学技术学院研究员、长聘副教授孙栩的演讲主题为《稀疏化深度学习自然语言处理的近期研究(Recent Studies on Sparse Deep Learning for Neural Language Processing)》。
当前深度学习多是密集型深度学习,需要更新所有神经元,这对能量消耗非常大。孙栩聚焦在稀疏化的深度学习NLP,提出一个简单有效的算法meProp来简化训练及训练出的神经网络。在反向传递算法中,找出梯度中最重要的信息,仅用全梯度的一小部分子集通过计算来更新模型参数。
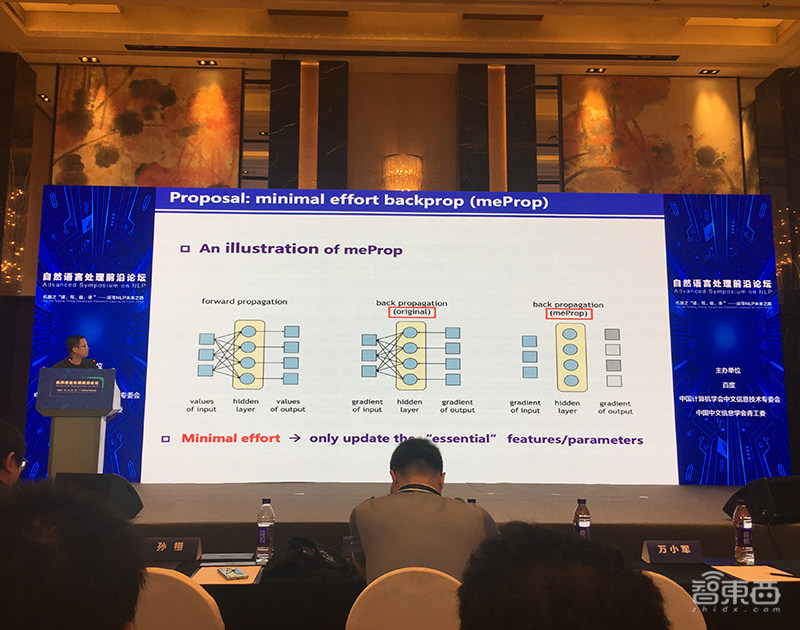
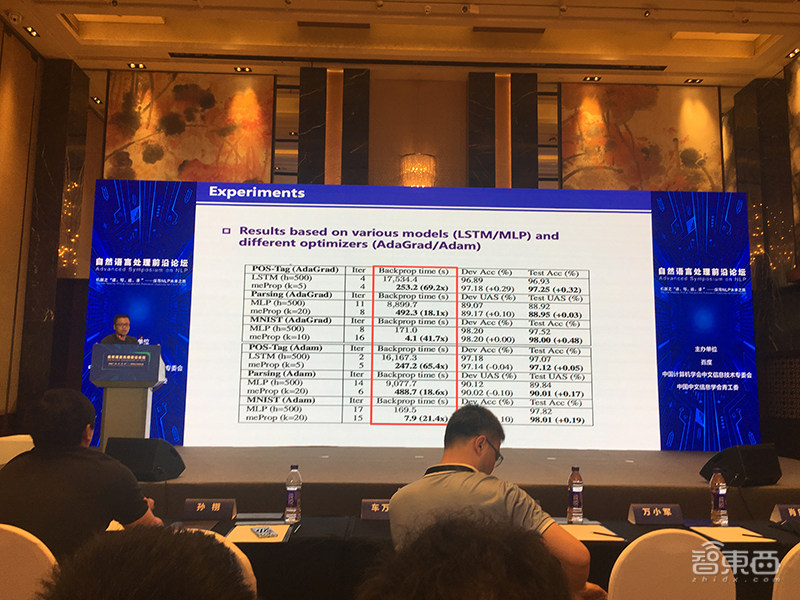
基于稀疏化梯度,他们通过删除很少被更新的行或列,这会降低训练和解码偶成中的运算量,并且可能在真实世界应用中加速解码。实验结果显示,在很多案例中,他们仅需要更新每个后向传播过程中大约5%的稀疏程度。
最终模型的精确度也有所提高,并且运算量降低了几十倍,对需要低能耗的移动端很有价值。
另一个 meSimp是对最小化努力的简化(minmal effort simplication),该算法可将一个复杂的神经模型裁剪到原来的1/10左右。
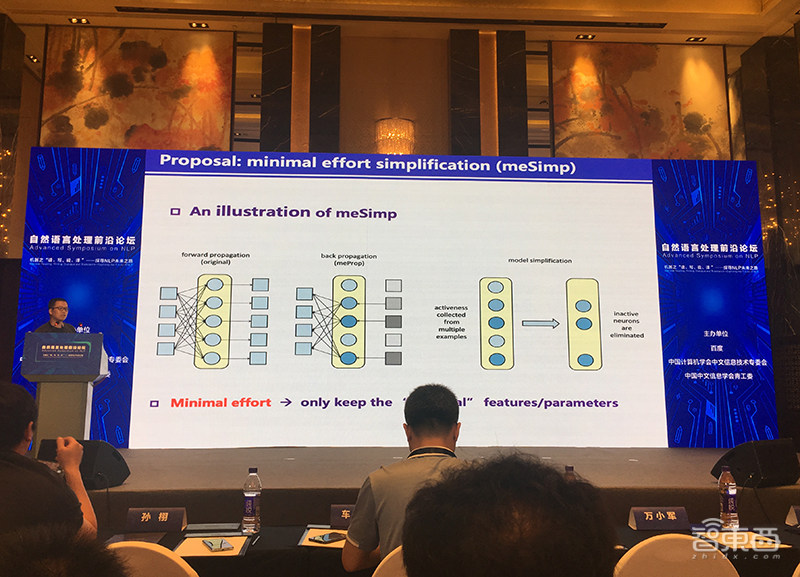
最后,孙栩介绍了他们的近期工作。他们提出了分析稀疏化反向传递的理论框架,meProp可能会被考虑为其中一个典型案例。他们发现如果裁剪不过度,有稀疏化反向传递的训练是可以收敛的。
三、NLP中的表示学习进展
目前全连接自注意力模型(如Transformer)在NLP领域取得了广泛成功。复旦大学计算机科学技术学院副教授邱锡鹏主要介绍了NLP中的表示学习进展。

邱锡鹏的演讲主要涵盖两部分内容。
1、模型层面
邱锡鹏介绍,应更好地融合局部和非局部的语义组合,另外他分析和对比CNN、RNN、Transformer的基本原理和优缺点,并提出了改进模型Star-Transformer。

Star-Transformer在局部和非局部之间提供了更好的平衡,提高了模型的泛化能力,有较好的并行能力和较低的复杂度,在小数据上效果非常好。
2、学习层面
学习层面方面初始假设端到端从零开始学习纯数据驱动,可通过知识增强、迁移学习和多任务学习的方法,其中迁移学习最主流的方法是无监督预训练。
通常的方法是用知识增强和预训练模型(如ELMo、BERT、GPT、ERNIE等)来提高其泛化能力,在很多NLP任务上取得了很好性能。
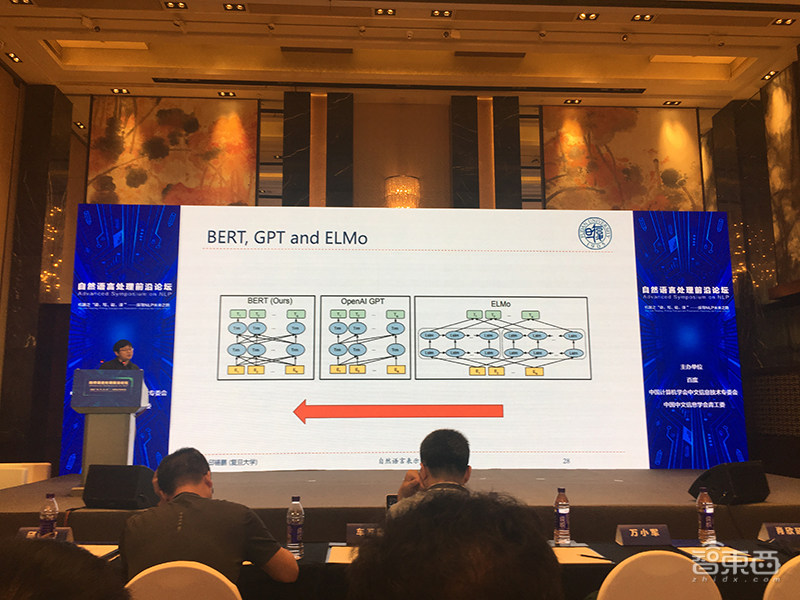
邱锡鹏表示,目前在表示学习方面,BERT更胜一筹。但BERT并非最终形态,还有很大的优化空间。他也提到如何Fine-tune BERT,微调方法有3类:(1)直接在单任务上微调;(2)先进一步训练BERT,再在单任务上微调;(3)先进一步训练BERT,再进行多任务微调,最后单任务微调。

四、百度语义计算技术的发展脉络
百度NLP主任研发架构师、语义计算技术负责人孙宇重点介绍了百度语义计算技术研发现状及发展脉络,并分享了该技术在百度各产品中的应用情况和挑战。
百度语义计算Topic将深度学习和文本任务深度融合,充分利用互联网大数据优势,研发了包括语义表示Ernie、语义匹配SimNet、语义解释、多模态语义计算在内的多项领先语义技术。
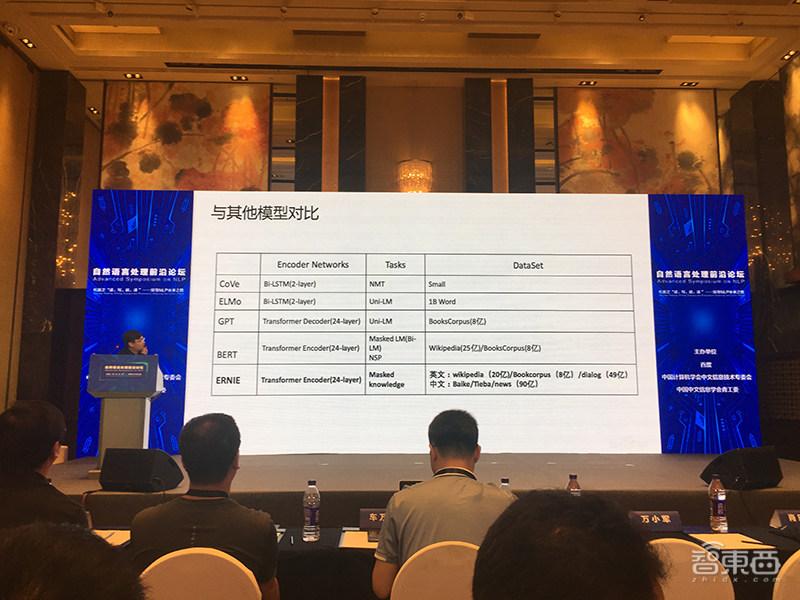
早期,百度采用过基于检索的表示方式、Topic Model等方法来做语义识别技术。后来基于DNN的语义表示技术兴起,百度在算法和规模上对word embedding进行研究。

2017年,百度开始做基于大规模表示迁移的探索——多特征融合。当时面临的严峻问题是标注语料少,因此百度研究人员们想到借由20亿搜索Query构建多特征语义表示,提升了SLU的Intent&Slot效果。
百度研究人员发现BERT对实体知识的语义概念捕捉的较少。

后来百度又做了一些改进。在数据层面,基于海量百科、新闻、对话多源数据训练,构建双向多层Transformer的语义建模模型,融合并强化中文词、实体等先验语义知识学习和进行多阶段知识学习。
据悉,通过在公开数据集上进行实验,ERNIE的中文效果和英文效果全面领先BERT。
在应用方面,百度提供面向工业应用的中文NLP开源工具集PaddleNLP,产品在广告相关性计算、推荐广告触发、推荐新闻去重、对话意图识别等领域已有一些落地。
百度还对传统文本匹配方法进行改进,在2013年设计研发神经网络语义匹配模型SimNet,当时时间比较紧没有将Paper及时发出,失去了一些机会。近年相关工作有微软的DSSM、DUET,华为诺亚方舟实验室的Arc-I、Arc-II等。
随后百度又基于SimNet基础模型全新升级,将算法模型框架升级为多层次匹配框架。

2019年百度发表的论文提出增强版representation-based model,适合对长文本的匹配;在匹配矩阵模型方面,该论文添加新匹配范式interaction-based model,先做粗匹配,再做精细化匹配,联合对模型进行优化,匹配更加充分和精细。
语义计算系列技术覆盖长短文本及多模态场景,在百度搜索、推荐、度秘、广告等产品发挥作用。
在对海量数据的研究中,百度发现数据时效性影响很大,另外还有频段、长短等数据分布问题和多渠道融合问题有待解决。
孙宇认为,尽管BERT很牛了,加入知识融合仍会有新的提升。
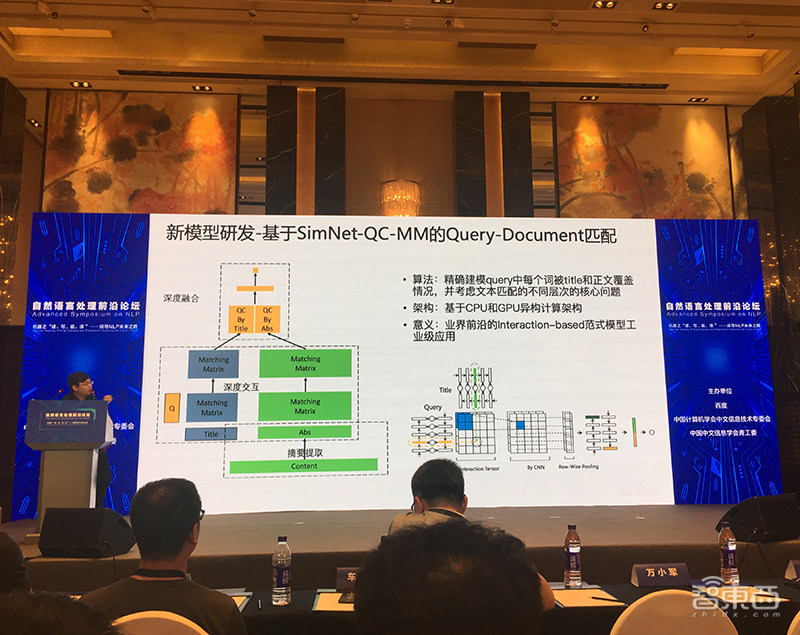
另外,孙宇还提到了基于SimNet-QC-MM的Query-Document匹配这一新模型研发。该算法精确建模query中每个词被title和正文覆盖情况,并考虑文本匹配的不同层次的核心问题,意义在于是有业界前沿的Interaction-based范式模型工艺级应用。
孙宇最后简单谈了一下未来的重点工作。语义表示将进一步突破,加强知识的利用、无监督任务的学习和弱监督信号灯的利用。他们将对多语言表示技术、面向生成任务的通用表示技术、多模态表示技术等进行语义表示的拓展性探索。
五、文本阅读理解的主流数据集和研究技能
在自动问答方面,中国科学院自动化研究所模式识别国家重点实验室副研究员刘康结合研究组近年的工作,介绍了从文本阅读理解的基本框架和方法。
跟学生做阅读理解题相似,给机器一段文字,它通过自动理解分析文本,针对相应问题给出答案。
机器阅读理解主要分为三类:基于问答的提炼(extraction based question answering),填空测验(cloze test)和多选(multiple choice)。这三类阅读理解在预测层采用的方法各不相同。

关于机器阅读理解的数据集也层出不穷:

2016年是机器阅读理解的一个分界点,在此之前传统的方法是词汇匹配、语义关系识别、事件抽取、逻辑推理等基于特征工程的方法,在2016年之后CNN、RNN、Attention等神经方法出现。
机器阅读理解的基本神经框架如下:

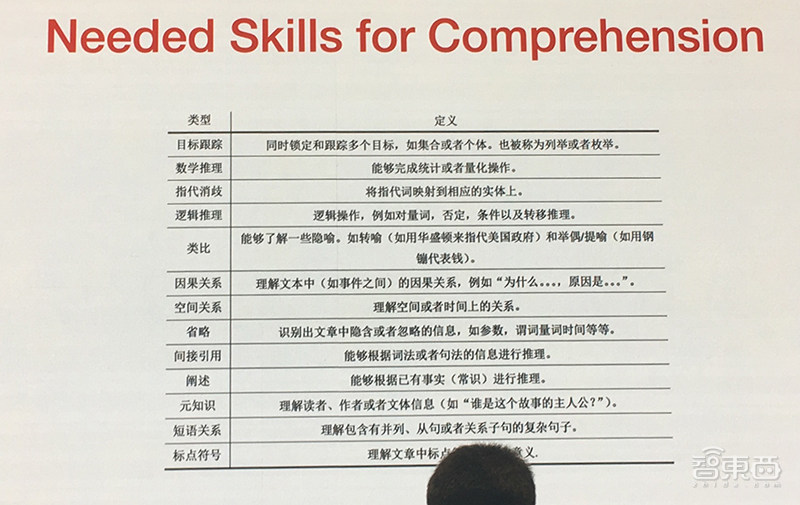
刘康还总结了研究机器阅读理解所需掌握的技能:
六、百度阅读理解技术研究及应用
百度NLP资深研发工程师、阅读理解与问答技术负责人刘璟首先介绍了百度针对实际工业应用研发的机器阅读理解技术,介绍了其在百度搜索问答中的应用,并介绍百度公开发布的中文阅读理解数据集DuReader,及其对中文机器阅读理解研究的推动。
刘璟表示,机器阅读理解的应用意义在于解决传统的检索式问答的“最后一公里”难题。得益于近两年阅读理解技术的快速进步,百度已将这一技术应用到智能问答中。他认为,这一快速进步主要归功于数据集规模的增加和深度学习的快速发展。
针对越来越多的挑战,相应的阅读理解数据集也在增加。
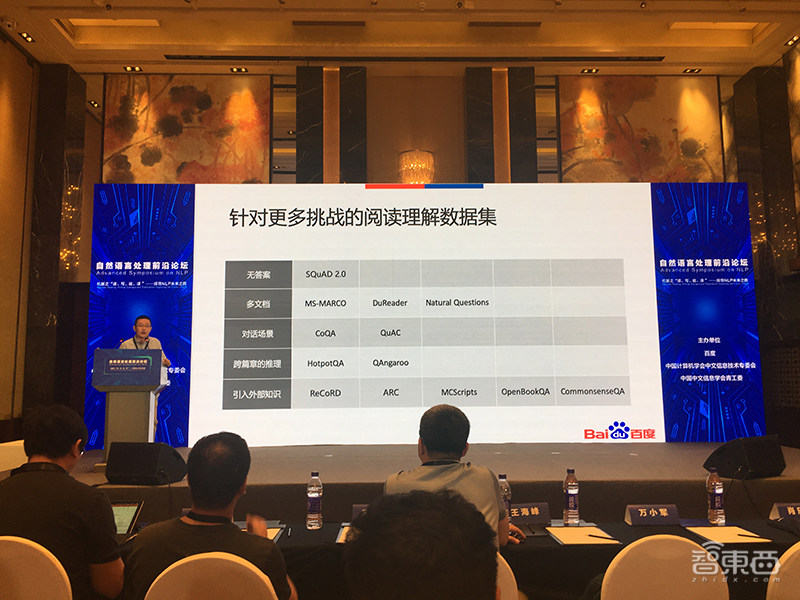
百度的研究内容主要包含多文档阅读理解模型V-NET(ACL18),以及知识表示和文本表示融合模型KTNET(ACL19)。
现实应用中的阅读理解通常存在搜索场景的真实问题,和包含多个候选文档段落致使包含较多歧义信息的问题。对此,百度研发了端到端的多文档阅读理解模型V-NET,该模型在英文多文档阅读理解数据集MSMARCO V2问答任务上三次排名第一。

要更好的抽取核心信息,除了依靠文档进行理解外,还可以引入外部知识,将原文本的文本表示与知识图谱的知识表示相结合,为此百度推出知识文本融合的阅读理解模型KT-NET。

除了在技术上进步,百度在去年推出面向搜索场景的阅读理解数据集DuReader 2.0,规模包含30万问题和150万文档,拥有66万人工标注答案、问题类型、实体和经验。该数据下载量超2万。

最后,刘璟谈到工业应用中对阅读理解模型鲁棒性的要求,主要在于过稳定(over-stability)和过敏感(over-sensitivity)问题。
过稳定指的是问题改变,答案没变;过敏感指的是问题没变,答案改变。
这两个问题在应用过程可能会影响用户体验的一致性,其鲁棒性可通过对抗样本生成、复述生成等方法提升。
工业应用中对阅读理解泛化能力也有要求:在领域A训练的模型能否很快很好的迁移到领域B,通过多任务学习、迁移学习等提升模型的泛化能力。
结语:预训练语言模型是最大亮点
总的来看,自然语言处理(NLP)作为各大高校和研究机构的人工智能方重点研究课题之一,过去一年间在技术和应用上都取得了可观的进步。其中最大的亮点当属预训练语言模型。从ELMo、ULMFiT、Transformer、BERT到ERNIE,这些算法横扫各大NLP性能测试榜单。尤其是BERT,被誉为NLP新时代的开端。
尽管BERT已经非常强大,但它仍有改进的空间,这也将成为今年诸多研究人员重点研究和突破的方向。
另外,随着NLP技术的逐渐成熟,其应用正变得更加广泛。除了在相对常见的搜索、机器翻译、阅读理解和智能写作持续提高水平外,NLP技术也开始更为深入地切入工业场景,并在广告相关性计算、推荐新闻去重等领域发挥更大的商业价值。
